Администратор, конечно, может безвозмездно разместить, вашу статью, либо залупить за площадку долларов 10, что нам, естественно, не совсем хотелось бы. Главное значение не в статье, а в гиперссылке, которая ведёт на ваш интернет-сайт.
Следует отметить, чем же это полезно для сайта. Значит у на есть сайт- донор и сат реципиент. 1-ый это тот, кто ставит на вас гиперссылку. Так вот, зачем это нужно. Самым важным считается то, что увеличивается ссылочный вес вашей странички. Это полезно для ТИЦ и приятно вебмастеру, заинтригованные гости из поисковиков. Однако имеется и оборотная сторона медали. Для написания хороших текстов необходимо владеть немалым количеством времени, понимать, о чем пишешь, и поиск хорошего места для размещения, займет много времени. Чтобы уменьшить это время можно использовать некие сервисы. Читать →
Начиная с 2007 года возрастает интерес к контенту, продвигающему сайт в топы. На сегодняшний день просто нет единой пошаговой инструкции к оптимизации статьями, поэтому толковый вебмастер при выборе того или иного способа руководствуется темой и целью проекта. Читать →
Скажу очевидное, но чтобы сайт или блог находили пользователи Интернета, необходимо добавить сайт в поисковые системы рунета. Google, Yandex и Mail.ru являются самыми популярными поисковиками в рунете, их коротко и рассмотрим в данном посте. Читать →
Google Tag Manager (GTM) — TMS (Tag Management Solution), online сервис (http://tagmanager.google.com) и javascript framework от Google, кот. при помощи небольшого script блока в коде вашего сайта предоставляет доступ к набору внешних js библиотек аналитики для детального анализа его использования юзерами. Google Tag Manager позволяет отображать в realtime через Google Analytics (http://analytics.google.com) статистику популярных сервисов аналитики: AdWords, DoubleClick, ComScore итд (их число ограничено). В GTM кроме стандартной статистики page views Google Analytics можно также анализировать events (click, link click, form submit итд), рекламные кампании и general usability сайта — heat maps, hover переходы, timing, user sessions итд, создавать custom triggers. Все это создает детальную картину использования сайта юзерами, очень полезную для маркетинга. Основное преимущество TMS — автоматизация работы маркетолога.
Все Tags/Triggers для анализа сайта создаются в Web UI на сайте GTM. Для получения базовой аналитикиникакого программирования не требуется — вы просто один раз вставляете script блок GTM и он сам загружает все Tags. Вся получаемая статистика отображается в Reports вкладке сервиса Google Analytics. При необходимости можно писать свои custom event listeners и передавать в GTM нужную статистику через его API из javascript на вашем сайте. Script блок Google Tag Manager является универсальным, включает код Google Analytics, его можно встраивать в любые сайты, например, в Google Blogger (http://www.blogger.com). Google Tag Manager можно рассматривать как plugin для Google Analytics, кот. значительно расширяет возможности для анализа — в статье рассматривается пример их совместного использования.
Вы должны иметь возможность редактировать код вашего сайта, иметь доступ к основной template. Например, в free блогах Google Blogger можно редактировать XML/HTML код основной template и вставлять gadgets/plugins/javascript snippets, а в free WordPress.com нельзя. Ниже приводится схема процесса установки GTM.
Чтобы установить Google Tag Manager на сайт нужно:
войти/создать Google ID account. При этом вы получаете доступ сразу ко всем онлайн сервисам Google, хотя в некоторых из них нужно создать еще внутренний аккаунт, чтобы их подключить.
в онлайн сервисе Google Analytics нажать Access Google Analytics, создать Account (указать любой Nickname/Company/Group) и Property (указать ваш сайт, url блога), получить Google Analytics Tracking ID для сайта. Status: Not Installed должен обновиться на Status: Receiving Data в теч. 72 час. Без Status Receiving Data история статистики не будет сохраняться.
в онлайн сервисе Google Tag Manager создать Account (указать любой Nickname/Company/Group) и Container (выбрать для Web, указать ваш сайт или любой Nickname), получить код для GTM Container
удалить из вашего са
йта/блога старый код Google Analytics, если он использовался (код GTM Container включает в себя Google Analytics).
вставить код для GTM Container в основную template вашего сайта сразу после (или во страницы, кот. должны участвовать в статистике, если сайт статический, без template). Код GTM Container должен встречаться в странице только 1 раз, его нельзя дублировать, нельзя использовать вместе с кодом Google Analytics — при этом возникают ошибки.
в онлайн сервисе Google Tag Manager/Container создать Tag с типом Page View и привязкой к Google Universal Analytics, указать в нем Google Analytics Tracking ID — чтобы статистика page views от GTM Container отображалась в Google Analytics Web UI в разделе Reports/Realtime/Overview для вашей Property.
в онлайн сервисе Google Tag Manager/Containerсделать Publish чтобы GTM Container на вашем сайте увидел созданный Тag.
в онлайн сервисе Google Analytics зайти во вкладку Admin, выбрать в Property ваш сайт, перейти в Reports/Realtime/Overview. Вся статистика от GTM может отображаться в Overview (page views/clicks), Content (page views/clicks), Events (clicks, form submits etc), Social (follow me/join clicks/social events) итд. Ваши заходы на сайт и просмотры страниц/events должны будут отображаться в realtime.
Модификация GTM Container кода для XML
Для сайтов на базе XML template потребуется слегка модифицировать стандартный код GTM Container. Например, Google Blogger использует для блога XML Template.
Для transitional XHTML doctype:
Обратите внимание, что в стандартном шаблоне GTM Container код в
Обратите внимание, что в стандартном шаблоне GTM Container удален iframe. В этом случае GTM не сможет работать/собирать статистику если в броузере отключен JavaScript, но только такой код пропустит Strict XML Parser. GTM-XXXX надозаменить на свой GTM ID.
Замена символов:
Вместо ...]]> иJavascript комментария /* */ можно просто заменить & на & Это не приведет к ошибке в коде, т.к. XML Parser подставит & обратно при генерации HTML.
Кроме того, в XML символ (') заменяется на ' (Например, так делает Blogger - достаточно вставить код, сохранить и закрыть template и потом снова ее открыть) Это также не приведет к ошибке в коде, т.к. XML Parser подставит (') обратно при генерации конечного HTML.
Вставка кода в Blogger:
в Blogger нельзя вставлять код в Layout через Add Gadget/HTML-Javascript snippet - он не вставится, XML parser его удалит.
Для вставки кода в Blogger вручную:
в Template рядом с Customize нажмите Edit HTML
вставьте модифицированный под transitional XHML код GTM Container c вашим GTM ID сразу после
сделайте Save Template
Для вставки автоматом:
в Settings/Other/Analytics Web Property ID просто укажите свой Tracking ID. При этом Template должна быть Layout или Dynamic Views - для Classic не работает. И пишут что это будет старый код для Classic Analytics.
В любом случае, нужно выбрать только один из вариантов вставки кода - код не должен дублироваться.
Версии Google Tag Manager и Google Analytics
Есть 2 версии Google Tag Manager: 1 и 2. С начала 2015 онлайн сервис использует GTM 2.0. Основные отличия GTM 2.0:
Web UI онлайн сервиса стал более простым и удобным, стал напоминать Web UI Google Analytics. В Admin вкладке GTM Account => GA Account, GTM Container => GA Property.
появился import/export containers
rules стали triggers. Теперь сначала задается тип взаимодействия, затем условия выполнения. При этом в trigger автоматом включается соотв. event listener, для него не нужно создавать отдельный Listener Tag как раньше. Для отображения event/trigger в панели Google Analytics по прежнему надо создавать отдельный Tag c привязкой к trigger в More.
Macros стали Variables. Variables используются в условиях Tag и Trigger для получения значений различных event/object properties, например {{ Page URL }}. Могут быть built-in или создаваться user.
Есть 2 версии Google Analytics: Classic и Universal. Сейчас онлайн сервис использует Universal (генерит Tracking ID и код для Universal), но раньше надо было делать migrate Classic аккаунта в Universal для каждой Property. Код от Classic пока работает с Tracking ID от Universal. Основные внешние отличия:
В онлайн сервисе GA:
в Classic у Property есть только Tracking Code
в Universal у Property есть раздел Tracking Info c Tracking Code и др. параметрами
Если вы хотите использовать GA вместо GTM, то при вставке GA кода в XML Template нужно также использовать ...]]> иJavascript комментарий /* */ или & как это описано выше.
Пример URL click tracking в Google Tag Manager
В Google Tag Manager есть 2 типа click events/triggers (c auto listener):
Click - используется для обработки click на любых элементах сайта: image, div, button, form, итд, включая url click и javascript click (кроме Flash объектов). Ему соответствует event gtm.click(). Click передает цепочке listeners (bubble up/event propagation) самый вложенный DOM child element под кликом.
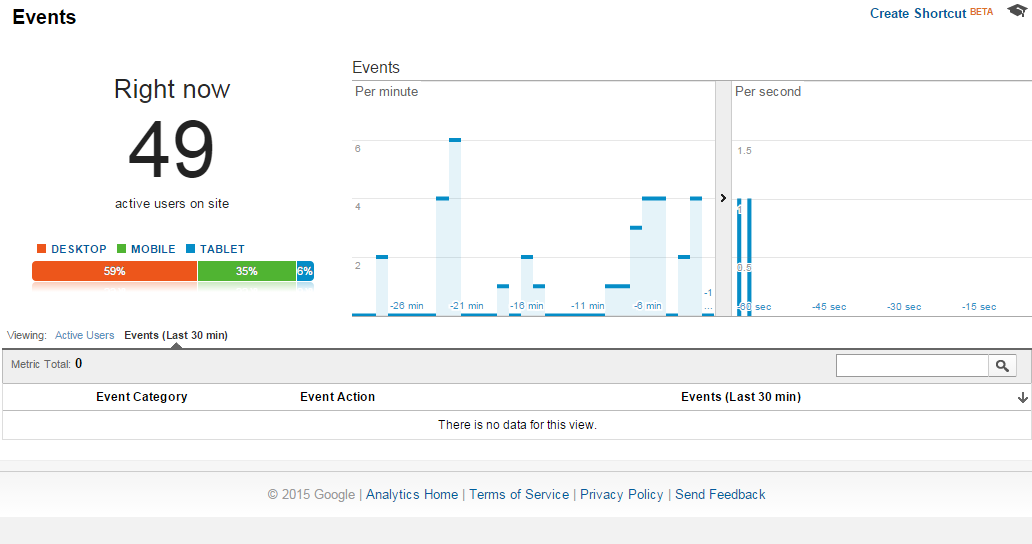
Click может быть real/реальным (переход на другую страницу) и virtual/виртуальным (переход по anchor внутри страницы, click на ссылке с pdf или javascript). В зависимости от этого Click может отображаться в Google Analytics как Page View(разделы Overview, Content) или как Click (раздел Events). Если это Click по кнопкам соц.сетей типа Follow Me on Twitter, Facebook его также можно отображать в разделе Social. Для отображения Click в Google Analytics вы создаете специальный Tag с привязкой к trigger, в зависимости от типа Tag он будет учитываться в статистике и отображаться в одном из перечисленных разделов. Пример отображения реальных page views и clicks as page views для загруженного сайта приводится ниже.
В онлайн сервисе Google Tag Manager в Container вашего сайта создаем простейший url click trigger для сбора статистики переходов по ссылкам:
Если нужно, в Variables включить Click URL built-in variable - просто отметить галкой Clicks/Click URL - после этого переменная будет доступна в dropdowns различных условий в Tag/Trigger. Click URL - куда будет переход, Page URL - текущая страница, с кот. производится переход. Полный список built-in variables: https://support.google.com/tagmanager/answer/6106965
в Triggers создать Trigger с Event Click и типом Click или Link Click. Для Link Click указать на каких страницах сайта он должен срабатывать (можно задать RegExp маску или создать contains условие/несколько условий для Page URL variable), оставить галки Wait for Tags, Check Validation. Для Link/Link Click указать при переходе на какие url он будет срабатывать (можно задать RegExp маску или создать contains условие/несколько условий уже для Click URL variable). После этого trigger будет работать на сайте, это можно проверить в GTM Debugger.
в Tags создать Tag с привязкой к Google Universal Analytics, указать в нем Google Analytics Tracking ID вашего сайта, указать тип Event, задать Category, Action, Label в виде текста или variables (например, {{Page URL}}, Click, {{Click URL}}). Value на задается и не отображается. В условиях срабатывания в More указать галкой созданный ранее Trigger. После этого статистика click event trigger от GTM Container будет отображаться в Google Analytics Web UI. В случае Tag с типом Event - как click в Reports/Realtime/Event (в колонках Category, Action и при клике на Category будет видна Label). В случае Tag с типом Page View - как page view в Reports/Realtime/Overview или Content. В обоих случаях просто считается число срабатываний trigger, но либо как clicks, либо как page views. При просмотре Reports/Realtime/Event надо не забывать сбрасывать крестиком создаваемую сверху автоматом цепочку синих прямоугольников-фильтров Category/Action, иначе вы не увидите другие events.
сделать Publish чтобы GTM Container на вашем сайте начал передавать статистику в созданный Тag.
в Google Analytics выбрать в Admin панели в качестве Property ваш сайт, иначе Reports не будут работать.
Wait For Tags - принудительная задержка перехода по нажатой ссылке до истечения Timeout или до завершения исполнения всех tags на текущей странице. Если галки нет - медленные Tags могут не успеть выполниться до начала загрузки новой страницы.
Check Validation - ожидание проверки validation. В случае Forms исполняет Tag (учитывает нажатие Submit в статистике) только когда все поля формы заполнены правильно и она считается valid. Если галки нет - учитываются любые нажатия Submit/url clicks.
Как видите, никаких модификаций кода сайта для создания полностью готового trigger (с auto listener) не нужно.
Смотреть Page Views History надо в разделе Audience/Overview, а Events History - в разделе Behavior/Events/Overview. Можно выставить нужный интервал: Hour, Day, Week, Month или установить custom диапазон (год, All Time итд). Можно сравнивать данные двух диапазонов.
Audience/Overview - Page Views History:
Behavior/Events/Overview - Events History:
Google Tag Manager Debugger
В Google Tag Manager есть встроенный Debugger для отладки events прямо на сайте. Он запускается внизу страницы в отдельном frame (как Developer Tools) если в GTM Web UI вместо Publish сделать Preview. При этом в Container Dashboard появляется сообщение Previewing на желтом фоне, и пока не сделать Leave Preview Mode Debugger будет автоматом загружаться на всех страницах сайта.
В окне Debugger можно смотреть в real time текущие значения Tags, Variables и Data Layer. Слева выдается стек сработавших DOM/GTM events, в правой части - какие Tags/Triggers сработали, какие условия в триггерах были/не были выполнены, вся передаваемая системе статистика (Data Layer). Во время debugging лучше кликать по ссылкам с Ctrl+click, чтобы при переходе текущая страница с окном Debugger оставалась открытой, а новая открывалась в новой вкладке.
Раньше в Google Docs Settings была галка, кот. позволяла делать tracking (view/download count) документов через Google Analytics автоматом, но начиная с 2011 ее убрали. На текущий момент Google Docs интегрированы в Google Drive, но легкого пути для их элементарного tracking по прежнему нет, что вызывает недоумение (Яндекс Диск это давно делает автоматом и без проблем).
Теоретически Google мог бы это сделать через plug-in для Google Drive или для отдельных приложений Google Docs, но их нет. Есть только плагины для Google Sheets, кот. подключаются к Google Analytics и рисуют красивые таблицы и графики со статистикой. Также есть плагины для Google Drive, кот. красиво отображают структуру ваших файлов на диске в виде инфографики. Но tracking доков они не делают.
Решения:
Офиц. решение Google:для tracking нужносделать embed документа в html page и вместо документа ссылаться и track-ать уже html page через Google Analytics. Это очень неудобно, т.к. предполагает создание массы вспомогательных промежуточных html с embed каждого документа или ссылкой на него, фактически дублируя вручную уже имеющийся автоматический функционал Google Drive. При заходе на html срабатывает page view event, кот. трактуется как view/download count самого документа (хотя, строго говоря, view это не download). Это возможно, если у вас уже есть блог и создать лишнюю страницу не проблема, но не работает когда у вас есть только документ на Google Drive и нет сайта. Все остальные также должны ссылаться на html с документом - тогда это будет учитываться в статистике. Нескольких документов/ссылок в этих html уже быть не может.
Google Tag Manager вместе с Google Analytics дают возможность track-ать не только page views, но и clicks. Т.е. мы избавляемся от промежуточного нагромождения из html с embedded документом/ссылкой на него и теперь можем считать url clicks для конкретной url вместо page views, но только со страниц нашего сайта с GTM. Если ссылки на документ делаются из нескольких мест - придется считать их все (это делается в одном trigger). Но переходы по этой же ссылке с других доменов/чужих сайтов посчитать уже нельзя - на них не установлены GTM/Analytics с нашими Tracking ID, для разных доменов нужны разные Tracking ID.
export doc и использовать для хранения и sharing документов Яндекс Диск с его built-in статистикой для любого файла на диске.
Advanced GTM Features
Описание advanced возможностей GTM не является частью данной статьи. GTM 2.0 сильно упростил работу по обработке статистики сайта за счет triggers с auto listeners. После установки GTM Container кода на сайте подключение всех создаваемых в дальнейшем в Web UI Tags/Triggers для сбора статистики происходит автоматически и не требует программирования/доп. изменений кода. Но вы также можете:
создавать Custom Variables и использовать их в условиях срабатывания Tags/Triggers
создавать GTM Triggers на базе Custom Events - писать свои custom events/listeners в коде сайта, регистрировать их в GTM Web UI и подключать к Triggers. Такие triggers можно как обычно привязывать к стандартным и Custom Tags.
создавать Custom HTML Tags для HTML и Images со своим алгоритмом обработки статистики, получаемой через Data Layer
вызывать напрямую библиотеки аналитики, передавать системе статистику через Data Layer (JSON) из скриптов сайта если это необходимо - см. API.
Пример отправки custom event в GTM через data layer:
dataLayer.push({ ‘event’: ‘myCustomEventName’ });
Пример привязки вашего custom event к GTM Trigger:
Пример использования нескольких условий в Trigger:
Пример создания Custom HTML Tag со своей обработкой статистики:
Пример создания Custom Variable:
При создании переменной просто указывается ее имя, после чего ее можно использовать в условиях Tags/Trigger и Custom HTML Tags.
Пример Custom HTML Tag - page tracking container:
Пример Custom HTML Tag - event tracking template:
для конкретной задачи - PlayVideo event tracking:
Пример обработки event из скрипта на сайте через Data Layer:
код GTM Container не может дублироваться на одной и той же странице
один и тот же код Google Tag Manager нельзя использовать на html страницах в разных доменах. Для каждого домена генерится отдельный Tracking код или используется Custom HTML Tag с вашей реализацией cross-domain обработки статистики.
есть проблемы со сбором статистики по Flash
triggers, созданные в онлайн сервисе GTM Web UI (со встроенными auto event listeners), срабатывают не всегда, т.к. это зависит от конкретной реализации DOM event propagation вашего сайта. Если listeners сайта не передают сработавший event дальше по DOM цепочке, нужно модифицировать код сайта и вручную писать custom event listeners, привязывать их к Tag/Trigger в GTM и передавать данные через data layer (см. Advanced GTM Features). Using GTM Data Layer with HTML Event Handlers: https://developers.google.com/tag-manager/devguide#events
GTM Tags загружаются с Google CDN асинхронно, нет поддержки синхронных A/B testing tags, как в других TMS
компилятор GTM сжимает ваш скрипт в Custom HTML Tag, сокращая названия переменных и функций для оптимизации, поэтому нельзя использовать eval() для вычисления dynamic variables.
в Custom HTML Tag должно быть не более 10240 characters. Если ваш скрипт больше - сожмите его или разбейте на несколько Custom Tags.
При прочих проблемах можно использовать GTM Debugger
Ограничения Google Analytics:
код Google Analytics не может дублироваться на одной и той же странице
один и тот же код Google Analytics нельзя использовать на html страницах в разных доменах. Для каждого домена генерится отдельный Tracking код.
если Reports/Realtime page views/events работаeт, показывает ваши заходы на сайт, но у Property сайта Status: Tracking Not Installed - ждать 72 часа - статус обновляется не сразу.
При прочих проблемах можно использовать Google Analytics Debugger Chrome Extension
Автор: vkatmandu
Дата публикации: 2015-04-15T19:08:00.000+04:00
Наиболее популярными движками для блогов являются WordPress и Blogger. Они подойдут почти для каждого в виду интуитивности интерфейсов и наличию настраиваемых элементов. Однако, растёт число людей, использующих простые генераторы статичных сайтов (например, Jekyll).
Здесь не будет рассуждений не тему того, кто всё же прав. Речь пойдёт о сервисе, который представляет собой нечто среднее между описанными выше движками. Читать →