IP-камера или камера с интернет-протоколом — это тип цифровой камеры безопасности, которая принимает и отправляет видеоматериалы через IP-сеть. Они обычно используются для наблюдения. В отличие от аналоговых камер видеонаблюдения (CCTV), IP-камерам не требуется локальное записывающее устройство, только локальная сеть. IP-камеры подключаются к сети так же, как телефоны и компьютеры.
КАК РАБОТАЮТ СЕТЕВЫЕ IP-КАМЕРЫ?
Для аналоговых и аналогово-цифровых камер видеонаблюдения требуется коаксиальный видеокабель для передачи отснятого материала на цифровой видеорегистратор (DVR). С другой стороны, IP-камера безопасности может передавать отснятый материал по беспроводному соединению. В частности, ip камеры видеонаблюдения подключаются к сетевому видеорегистратору (NVR) через Wi-Fi, кабель Ethernet или USB.
IP-камера снимает кадры с высоким разрешением — разрешение может достигать 16 мегапикселей, в зависимости от модели камеры. Каждая IP-камера оснащена чипом обработки, который сжимает видео по мере его записи. Что это означает? Ну, чем выше разрешение камеры, тем больше данных в каждой видеозаписи. Изображения с высоким разрешением требуют больше места для хранения и большей пропускной способности для передачи данных, чем изображения более низкого качества. Для передачи изображений высокой четкости по сети IP-камеры должны сжимать файлы или уменьшать их размер, чтобы избежать чрезмерного использования полосы пропускания. Современные стандарты сжатия, такие как h.264 и MPEG-4 означает, что либо нет падения, либо просто небольшое падение частоты кадров и разрешения, когда отснятый материал наконец достигает вашего телефона или компьютера.
Вот некоторые дополнительные преимущества использования IP-камер перед камерами видеонаблюдения:
- Двустороннее аудио. Владелец камеры может слушать и говорить с объектом через динамик на камере. Некоторые камеры дверного звонка предлагают эту функцию.
- Удаленный доступ. Авторизованные пользователи могут просматривать видео в реальном времени с любого смартфона, планшета или компьютера.
- Лучшее разрешение. IP-камеры имеют разрешение до 4 раз больше, чем аналоговые камеры.
- Меньше кабелей и проводов. Power over Ethernet обеспечивает питание через кабель Ethernet, позволяя камере работать без специального источника питания.
ПРИ НАСТРОЙКЕ IP-КАМЕРЫ МОЖНО ВЫБРАТЬ ОДИН ИЗ ТРЕХ ВАРИАНТОВ СЕТИ.
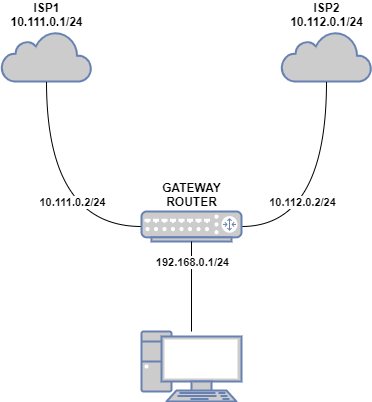
Беспроводной сети или сети Wi-Fi, передает и принимает данные к беспроводному модему. Телефоны, компьютеры, некоторые телевизоры, игровые консоли и другие устройства безопасности подключены через Wi-Fi, и ваша IP-камера ничем не отличается. Один из способов просмотра видеозаписи с IP-камеры — ввести ее IP-адрес в веб-браузере. Имейте в виду, что IP-адрес должен быть статическим. Некоторые интернет-провайдеры предоставляют своим клиентам динамические IP-адреса, которые время от времени меняются. Вы захотите поговорить со своим провайдером о статическом IP-адресе, чтобы убедиться, что вы можете получить доступ к своей IP-камере.
Проводная сеть соединяет IP — камеру к сети с помощью кабеля Ethernet. Эта установка считается наиболее безопасной, так как существует небольшая вероятность помех сигнала или несанкционированного доступа. Ожидайте максимальной скорости передачи данных с помощью Ethernet, поскольку проводное соединение намного эффективнее Wi-Fi.
Сотовая сеть, пожалуй, самый удобный из трех, но это самый медленный. В целом Wi-Fi обеспечивает более высокую скорость загрузки и выгрузки. Большинство IP-камер поставляются с сотовым передатчиком из коробки, поэтому настройка, установка и подключение просты.
ВАМ НЕОБХОДИМО УБЕДИТЬСЯ, ЧТО ВАША СЕТЬ БЕЗОПАСНА, ИНАЧЕ IP-КАМЕРЫ МОГУТ СТАТЬ ЖЕРТВОЙ ХАКЕРОВ.
Перед установкой системы IP-камеры безопасности вы или ваш поставщик камеры безопасности должны спросить:
- Защищена ли ваша система IP-камеры с помощью уникальных учетных данных?
- Ваша беспроводная сеть является частной?
В 2014 году журналист наткнулся на веб-сайт, на котором было проиндексировано 73 000 местоположений с незащищенными IP-камерами по всему миру. Жутко, мягко говоря, но находка подняла очень важный момент. Большинство камер видеонаблюдения имеют имя пользователя и пароль по умолчанию. Хотя предполагается, что логин по умолчанию будет изменен, во многих случаях — по крайней мере, 73 000 случаев, очевидно — он был оставлен без изменений в качестве логина по умолчанию.
На веб-сайте были получены кадры с камер видеонаблюдения различных предприятий, включая торговые центры, склады и автостоянки. Но что еще хуже, были также кадры с камеры из жилых комнат и спален частных резиденций.
Это испытание раскрывает суровую правду: незащищенные IP-камеры на удивление легко взломать.
Хорошие новости? Это даже проще, чтобы обеспечить IP — камера! На самом деле это так — вам просто нужно проверить две вещи. Во-первых, убедитесь, что вы изменили учетные данные для входа в камеру по умолчанию. Если вы не знаете, как это сделать, обратитесь к руководству по эксплуатации камеры. Специалист по безопасности может помочь вам в этом, если вы наймете компанию для установки вашей системы видеонаблюдения. Следующее, что вам нужно сделать, это еще раз проверить, является ли ваш Wi-Fi частным. Если камеры подключены к общедоступной сети Wi-Fi, любой, у кого есть IP-адрес, может получить доступ. При частном подключении Wi-Fi только пользователи, вошедшие в систему Wi-Fi, могут получить доступ к отснятому с камеры видеоматериалу.
Как только камера безопасности и Wi-Fi будут защищены, вы будете настроены. Современные беспроводные модемы используют систему шифрования данных под названием Wi-Fi Protected Access (WPA). С годами стандарты WPA ужесточились. WPA3 считается наиболее безопасным и используется на некоторых новых модемах. WPA дополнительно защитит ваши камеры видеонаблюдения от взлома и других типов несанкционированного доступа.
По сравнению с аналоговыми камерами, IP-камеры безопасности предлагают удобные функции и подходят для любого дома или бизнеса. Независимо от того, нужна ли вам всего одна камера или несколько, вы не ошибетесь с IP-камерами.
2021-07-31T19:10:16
Безопасность