Чтобы ваш ноутбук работал эффективно и быстро, необходимо время от времени устанавливать обновления программного обеспечения. Обновления для вашего ноутбука очень важны, так как они представляют новые функции и приложения, которые могут помочь вам в повседневных задачах. К ним относятся обновления, касающиеся каждого оборудования или устройства, встроенного в ваш ноутбук. Однако распространенная проблема, возникающая после обновления до Windows 10, заключается в том, что звуковая система не работает, поэтому, если вы столкнулись с такой проблемой, вам не о чем беспокоиться, поскольку мы собираемся решить эту проблему отсутствия звука.
Нет проблем со звуком после обновления Windows 10
Поддержание Windows на вашем ноутбуке в актуальном состоянии очень важно, так как это помогает вашему ноутбуку работать более эффективно, но иногда эти обновления могут испортить настройки вашего оборудования. Есть вероятность, что новое обновление может стать несовместимым с оборудованием. Итак, в этом случае мы описали некоторые возможные исправления, которые могут устранить проблему отсутствия звука после обновления до Windows 10.
Исправление 1: проверьте, включены или отключены динамики.
Первым делом вам нужно проверить состояние динамиков, потому что они могут быть отключены, поэтому для этого вам нужно щелкнуть параметр «Звуки» в меню, которое появляется, когда вы щелкаете правой кнопкой мыши по динамику, как на изображении ниже:
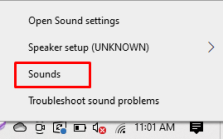
Затем, после нажатия на параметр «Звуки», откроется другое окно с различными параметрами, а в параметре воспроизведения вы можете увидеть на изображении ниже, что динамики отключены, поэтому теперь мы собираемся включить его:
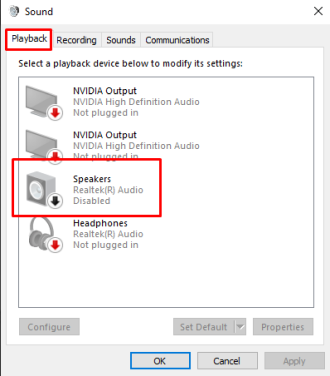
Просто щелкните правой кнопкой мыши на динамике и нажмите «Включить», а затем нажмите «ОК», как на изображении ниже, ваш динамик включится, и, надеюсь, проблема будет решена.
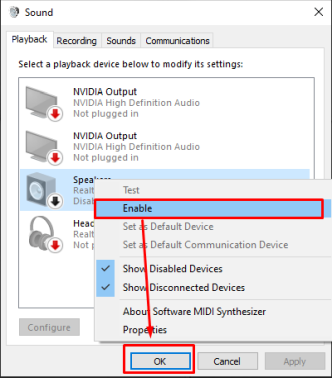
Вы также можете проверить свои динамики, щелкнув параметр тестирования, если динамики включены.
Исправление 2: проверьте, отключен ли ваш звук
Проверьте звук, он может быть отключен; вы можете проверить это, щелкнув значок динамика на панели задач, как показано на изображении ниже:
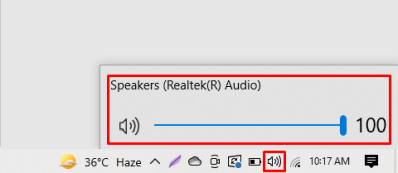
Кроме того, проверьте звук для других устройств в настройках микшера громкости, которые можно открыть, щелкнув правой кнопкой мыши значок динамика на панели задач, как показано на изображениях ниже:
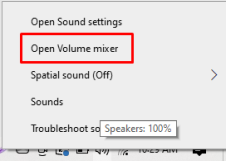
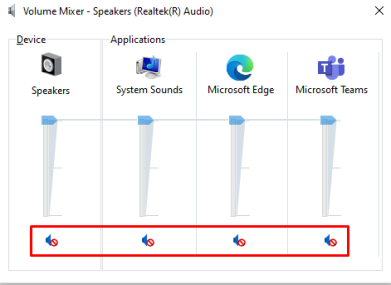
Вы можете щелкнуть значок динамика, чтобы включить звук, если звук выключен, затем включить его и воспроизвести любой звук, если он работает, тогда все в порядке, а он не работает, а затем перейти к следующему исправлению.
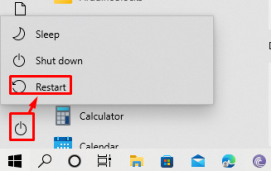
Исправление 3: перезагрузите ноутбук
В большинстве случаев эту проблему можно решить, просто перезагрузив ноутбук, поэтому попробуйте перезагрузить ноутбук и проверьте, решена ли проблема или нет.
Исправление 4: проверьте драйверы динамиков в диспетчере устройств
Иногда после обновления Windows либо обновление не совместимо с вашим оборудованием, либо его драйвер не обновлен, поэтому для этого вам нужно зайти в диспетчер устройств вашего ноутбука.
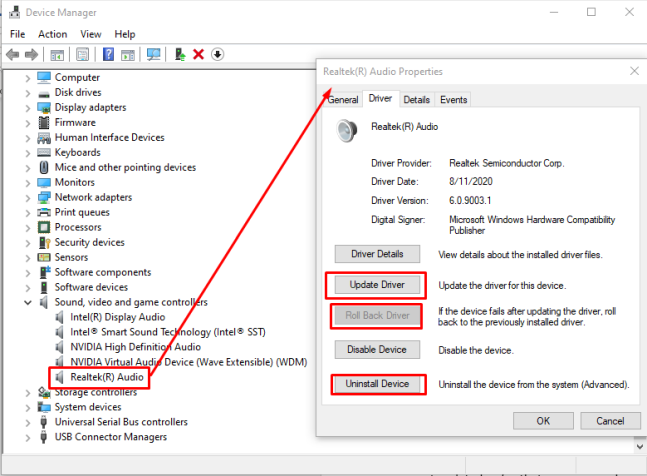
Отсюда вы можете обновить драйвер и, если он уже обновлен, удалить его и перезагрузить ноутбук. В некоторых случаях Windows не может правильно обновить драйвер, в этом случае нажмите «Откатить драйвер», чтобы установить ранее установленный драйвер.
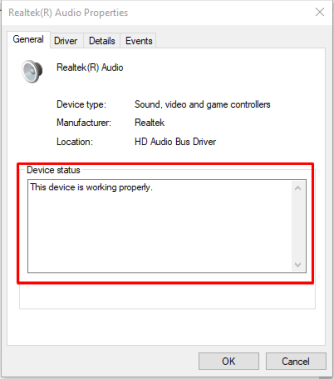
Также вы можете увидеть состояние устройства, нажав на общую опцию, как на изображении ниже, и если состояние говорит о том, что устройство не работает должным образом, попробуйте либо переустановить драйвер, либо обновить драйвер.
Исправление 5. Запустите средство устранения неполадок для динамиков
Если все приведенные выше исправления не устранили вашу проблему, то чтобы проверить, что компьютер говорит о проблеме, вам необходимо запустить средство устранения неполадок для динамиков, а для запуска средства устранения неполадок выполните указанные шаги:
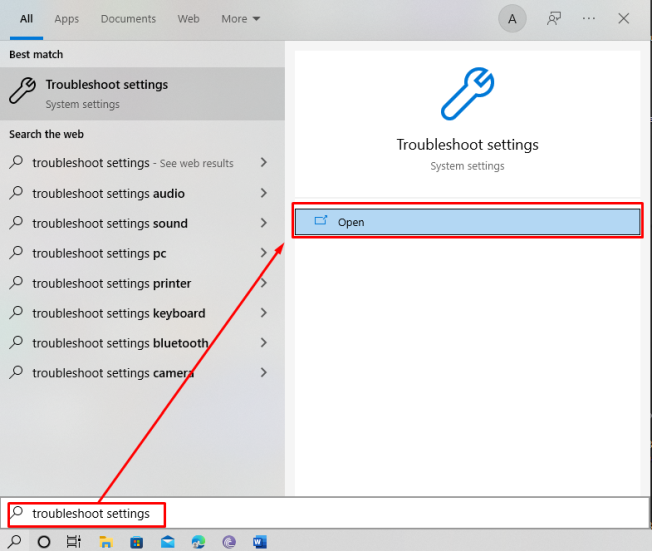
Шаг 1: Откройте настройки устранения неполадок
Найдите настройки устранения неполадок в строке поиска Windows и откройте ее, как показано на изображении ниже:
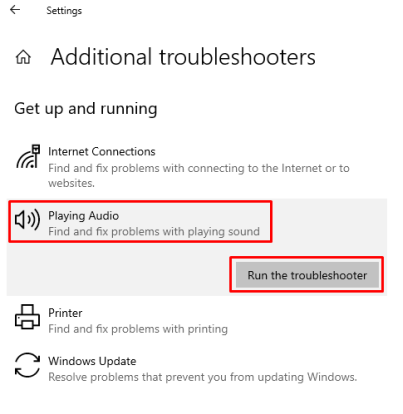
Шаг 2: Запустите средство устранения неполадок для воспроизведения звука в дополнительных средствах устранения неполадок.
После того, как вы открыли средство устранения неполадок, щелкните расширенные средства устранения неполадок, где вы увидите вариант воспроизведения звука. Нажмите «Запустить средство устранения неполадок», как показано на изображении ниже, и компьютер начнет искать проблемы.
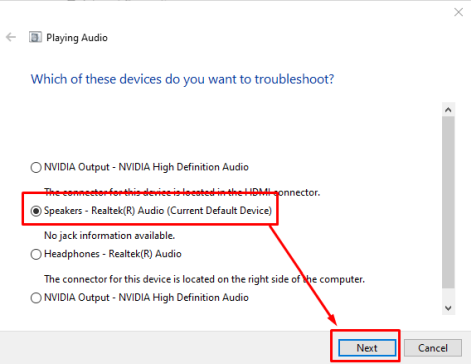
Шаг 3: Выберите устройство, которое вы хотите устранить, в аудиосистеме.
Затем он спросит вас, какое устройство вы хотите устранить, в зависимости от аппаратного обеспечения вашего ноутбука, поэтому вам нужно выбрать вариант динамиков и нажать «Далее», как показано на изображении ниже.:
Шаг 4: Отключите улучшения
. Он начнет обнаруживать проблемы с динамиками и скажет отключить улучшения, чтобы улучшить качество звука, поэтому нажмите «Открыть улучшения звука» и продолжите поиск проблем.
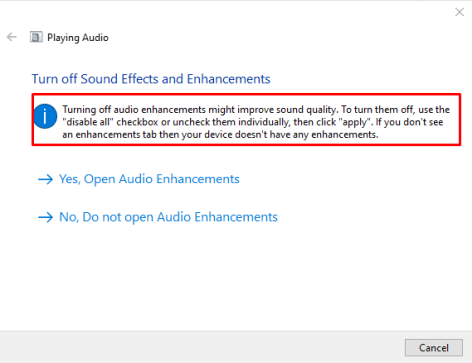
В расширенном параметре вы можете изменить качество звука, а также отключить улучшения, сняв флажок, чтобы включить улучшения звука, также вы можете проверить звук, нажав на опцию тестирования. После того, как вы внесли нужные изменения, нажмите значок «Применить», затем нажмите «ОК», как показано на изображении ниже:
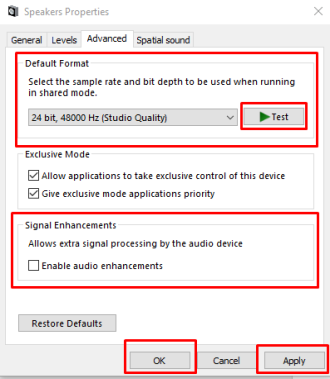
Как и в нашем случае, динамики были отключены, поэтому он автоматически включил их, как вы можете видеть на изображении ниже:
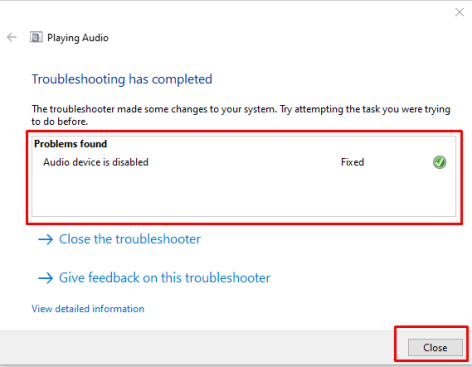
Если проблем нет, вы увидите следующее сообщение:
Вывод
Обновления работают как спасательный круг для компьютера, поскольку они информируют машину о новых приложениях, функциях и делают ее более защищенной от вирусов и потенциальных угроз. Однако иногда эти обновления могут быть несовместимы с некоторыми устройствами компьютера, такими как динамики. В этом случае мы предоставили 5 возможных исправлений, которые могут помочь вам, если после обновления Windows 10 возникнут проблемы со звуком.




