Из статьи вы узнаете про стандартные потоки ввода и вывода, и перенаправление этих потоков в файл или от одного процесса другому.
Архив рубрики: Публикации
Ladybird, новый кроссплатформенный веб-браузер с открытым исходным кодом

Браузер Ladybird, основанный на движках SerenityOS LibWeb и LibJS.
Недавно Представлены разработчики операционной системы SerenityOS введение своего кросс-платформенного веб-браузера под названием «Леди Бёрд» на основе движка LibWeb и интерпретатора JavaScript LibJS, которые разрабатываются проектом с 2019 года.
Стоит отметить, что создание нового браузера с нуля невозможно без вложения больших средств и сотрудничества многих людей на протяжении многих лет. Руководитель проекта Ladybird доказывает обратное с помощью нового кроссплатформенного браузера с графическим интерфейсом с открытым исходным кодом, реализованного на C++.
Как создать аккаунт в Телеграм без номера телефона
Лучший способ регистрации в Телеграмме без номера телефона
Мессенджер «Телеграм» на сегодняшний день узнается даже совсем юными обывателями сети. Его используют для разного рода целей, от бытового общения, до бизнес целей, планирования, структуризации рабочих процессов и иных задач. Порой зарегистрировать новый Telegram профиль не представляется возможным, по причинам блокировки контактного телефона, уже имеющегося аккаунта, либо попросту ввиду недостачи новых слотов сим-карты в телефоне. С целью пользовательского облегчения регистрации нового профиля в Telegram, наш сайт 365SMS.org предоставляет виртуальные номера, позволяющие оперативно проводить активацию телеграм без номера.
Основное отличие нашего интернет ресурса, от аналоговых порталов, состоит в том, что ваш профиль в Telegram не слетает спустя длительное время. Аккаунт остается актуальным для вас, вне зависимости от временного простоя. Для пользователей сети отнюдь не нова та проблема, когда их купленный номер и впоследствии зарегистрированный аккаунт Telegram, достается “неизвестным” лицам, которые меняют аватарку профиля, стирая контакты и тд. Наш сервис предлагает только:
- Действенный продукт.
- Множество номеров разных стран и сервисов.
- Объективную ценовую политику.
- Удобство интерфейса сайта 365SMS.
Автоматизированный сервис нашего портала, обеспечивает своих клиентов демократичными тарифами, скоростью предоставления услуг, действенными и гибкими решениями при покупке нужных активационных сервисов.
Довольно часто аналоговые компании ставят ограничение на прием определенного количества смс сообщений для активации различных сервисов. Наша же компания не имеет подобных рамок, поэтому пользователей при покупке может принять как 1-у смс, так и 10-ть. Виртуальный номер актуален не 5 и не 10 минут, а целых 20-ть, поэтому вы в состоянии завершить все запланированные дела и задачи, избыточно не тратясь на покупку дополнительных виртуальных номеров. Следует учесть, что покупка виртуального номера для активации Telegram, не предусматривает повторное смс подтверждение на данный сервис, так как политика Telegram такова: 1 номер – 1 аккаунт.
Стоит заметить, что оплата происходит только за полученные смс сообщения, если они не поступили, номер деактивируется, и вы ничего не теряете. Простота активации телеграм без номера в нашем сервисе изумляет.
Далее мы прилагаем подробную инструкцию для регистрации в телеграм без номера:
Шаг первый
В правом верхнем углу находите кнопку регистрация, кликаете и проходите её.

Шаг второй
Пополняете баланс профиля на нужную сумму.

Шаг третий
Выбираете нужного оператора и страну, а также сам сервис, в нашем случае Telegram. Покупаете номер с помощью нажатия на корзинку.

Шаг четвертый
Принимаете код на указанный в графе телефон и завершаете регистрацию.



Шаг пятый
После того как вы получили код и завершили регистрацию профиля Telegram, нажмите «завершить работу с номером».

Поздравляем, вы стали обладателем подтвержденного Telegram аккаунта. Теперь ваши рутинные, бытовые или бизнес заботы облегчаться многократно. Наш сервис направлен на упрощение и поддержку пользователей сети в интернет коммуникации.
Портал 365SMS – выбирается все чаще, как физическими гражданами, так и юридическими лицами для своих целей и задач. Активация Telegram без номера по низкой цене, с нашим сайтом возможна.
2022-09-12T21:45:44
Вопросы читателей
Как исправить зависание iPhone на логотипе Apple
Это сложная ситуация, потому что как устранить ошибку, если вы даже не можете получить доступ к iPhone? С этим каждый год приходится сталкиваться некоторым несчастным пользователям. Их iPhone застрял на логотипе Apple и не загружается. Некоторые другие пользователи видят белый или черный экран смерти или продолжают перезагружаться. Хорошей новостью является то, что Dr.Fone может помочь вернуть ваш iPhone в рабочее состояние.
Почему iPhone может зависнуть на логотипе Apple
Это может произойти по нескольким причинам, некоторые из которых находятся под вашим контролем, а другие нет.
- Вы пытались сделать джейлбрейк своего iPhone
- Новое обновление iOS на старом iPhone
- Процесс восстановления iPhone пошел не так
- Аппаратное обеспечение устройства было повреждено из-за воды, износа, падений и т. д.
Как исправить зависание iPhone на логотипе Apple
Приложение Dr.Fone имеет ряд модулей для обслуживания и ремонта вашего Android и iPhone. Один из модулей называется «Восстановление системы», который мы будем использовать в сегодняшней демонстрации продукта и рассмотрим шаги, необходимые для устранения проблемы.
1. Сначала загрузите и установите iOS System Recovery с сайта Wondershare (компания-учредитель приложения Dr.Fone). Он доступен как для Windows, так и для macOS, но я буду использовать Windows 11 для демонстрации продукта.
2. На рабочий стол должен быть добавлен ярлык приложения. Если нет, вы также можете найти и запустить его из поиска Windows (нажмите Windows+S).
3. Теперь подключите iPhone к компьютеру с Windows с помощью кабеля Lightning to Type A или Type C.
4. Нажмите на модуль восстановления системы, который вы только что купили.
![]()
5. Dr.Fone должен автоматически обнаружить устройство. В открывшемся всплывающем окне выберите «Восстановление iOS» на левой боковой панели. Теперь вас встретит два варианта — стандартный режим и расширенный режим.
Стандартный режим попытается решить проблему, не стирая пользовательские данные, в то время как расширенный режим очистит ваше устройство при устранении проблемы. Если вы сделали резервную копию данных iPhone в iCloud или iTunes, вам не о чем беспокоиться. Но все же рекомендуется сначала попробовать Стандартный режим.
![]()
6. Появится всплывающее окно с предупреждением о том, что подключенный iPhone перейдет в режим восстановления. В нем также объясняется, что вам нужно нажать кнопку «Выйти из режима восстановления», прежде чем вы сможете отключить и использовать свой iPhone. Нажмите кнопку «Войти в режим восстановления».
![]()
7. Dr.Fone автоматически определит вашу версию iOS и сопоставит ее с нужной прошивкой, которую вам нужно установить, чтобы волшебство произошло. Нажмите кнопку Start, чтобы начать загрузку прошивки.
![]()
8. Вы можете увидеть процесс загрузки, а затем экран подтверждения. Дождитесь завершения процесса. Теперь нажмите кнопку «Исправить сейчас», чтобы начать процесс восстановления. Dr.Fone установит загруженную прошивку и попытается исправить проблему с зависанием iPhone при появлении логотипа Apple.
![]()
Теперь, когда Wondershare часто обновляет свое программное обеспечение, чтобы не отставать от обновлений iOS. Таким образом, некоторые экраны могут немного отличаться на вашем компьютере. Если это так, следуйте инструкциям на экране и прочитайте все, прежде чем принимать решение.
Если стандартный режим не работает, перезапустите процесс и на этот раз выберите расширенный режим. Опять же, вы потеряете все данные, хранящиеся локально, включая все установленные приложения.
Культовый логотип Apple
Хотя нам всем нравится логотип Apple, мы не хотим продолжать видеть его на экране нашего дорогого iPhone. Ведь всему свое время и место. Я надеюсь, что Dr.Fone смог решить проблему, и теперь ваш iPhone загружается правильно. Если ничего не помогает, вам не остается ничего другого, кроме как отнести его в ближайший Apple Store.
2022-09-12T14:31:32
Вопросы читателей
Chown linux: синтаксис и описание команды
Chown linux – команда позволяющая изменить владельца пользователя и / или группы для данного файла, каталога или символической ссылки. Что такое команда Chown linux и зачем ее нужно использовать.
Команда Chown linux
Команда chown позволяет изменить владельца пользователя и / или группы для данного файла, каталога или символической ссылки.
chown (от англ. change owner) — UNIX‐утилита, изменяющая владельца и/или группу для указанных файлов. В качестве имени владельца/группы берётся первый аргумент, не являющийся опцией. Если задано только имя пользователя (или числовой идентификатор пользователя), то данный пользователь становится владельцем каждого из указанных файлов, а группа этих файлов не изменяется. Если за именем пользователя через двоеточие следует имя группы (или числовой идентификатор группы), без пробелов между ними, то изменяется также и группа файла. При стандартной настройке сервера команда вызывает сброс накопленных кэшей (событие touch).
В Linux все файлы связаны с владельцем и группой, и им назначены права доступа для владельца файла, членов группы и других.
Chown linux синтаксис и опции
Синтаксис chown, как и других подобных команд linux очень прост:
$ chown пользователь опции /путь/к/файлу
В поле пользователь надо указать пользователя, которому мы хотим передать файл. Также можно указать через двоеточие группу, например, пользователь:группа. Тогда изменится не только пользователь, но и группа. Вот основные опции, которые могут вам понадобиться:
- -c, –changes – подробный вывод всех выполняемых изменений;
- -f, –silent, –quiet – минимум информации, скрыть сообщения об ошибках;
- –dereference – изменять права для файла к которому ведет символическая ссылка вместо самой ссылки (поведение по умолчанию);
- -h, –no-dereference – изменять права символических ссылок и не трогать файлы, к которым они ведут;
- –from – изменять пользователя только для тех файлов, владельцем которых является указанный пользователь и группа;
- -R, –recursive – рекурсивная обработка всех подкаталогов;
- -H – если передана символическая ссылка на директорию – перейти по ней;
- -L – переходить по всем символическим ссылкам на директории;
- -P – не переходить по символическим ссылкам на директории (по умолчанию).
Утилита имеет ещё несколько опций, но это самые основные и то большинство из них вам не понадобится. А теперь давайте посмотрим как пользоваться chown.
Использование Chown linux
Например, у нас есть несколько папок dir и их владелец пользователь sergiy: $ls
Давайте изменим владельца папки dir1 на root: $chown root ./dir1
Если вы хотите поменять сразу владельца и группу каталога или файла запишите их через двоеточие, например, изменим пользователя и группу для каталога dir2 на $root:chown root:root ./dir2
Если вы хотите чтобы изменения применялись не только к этому каталогу, но и ко всем его подкаталогам, добавьте опцию -R: $chown -R root:root ./dir3
Дальше давайте изменим группу и владельца на www-data только для тех каталогов и файлов, у которых владелец и группа root в каталоге /dir3: $chown –from=root:root www-data:www-data -cR ./
Для обращения к текущему каталогу используйте путь ./. Мы его использовали и выше. Далее указываем нужную группу с помощью опции –from и просим утилиту выводить изменения, которые она делает в файловой системе с помощью опции -c.
Больше команд для Linux в разделе.
Chown как сменить владельца файла
Чтобы изменить владельца файла, используйте chown команду, за которой следует имя пользователя нового владельца и целевой файл в качестве аргумента:
chown USER FILE
Например, следующая команда изменит владельца файла с именем file1 на нового владельца с именем linuxize :
chown linuxize file1
Чтобы изменить владельца нескольких файлов или каталогов, укажите их в виде списка через пробел. Команда ниже меняет владельца файла с именем file1 и каталогом dir1 на нового владельца с именем linuxize :
chown linuxize file1 dir1
Числовой идентификатор пользователя (UID) можно использовать вместо имени пользователя. Следующий пример изменит владельца файла с именем file2 на нового владельца с UID 1000 :
chown 1000 file2
Если в качестве имени пользователя существует числовой владелец, то владение будет перенесено в имя пользователя. Чтобы избежать этого префикса, идентификатор с помощью + :
chown 1000 file2
Chown как изменить владельца и группу файлов
Чтобы изменить владельца и группу файла, используйте chown команду, за которой следует новый владелец и группа, разделенные двоеточием ( : ) без промежуточных пробелов и целевого файла.
chown USER:GROUP FILE
Следующая команда изменит владельца файла с именем file1 на нового владельца с именем linuxize и группой users :
chown linuxize:users file1
Если вы опустите имя группы после двоеточия ( : ), группа файла изменится на группу входа указанного пользователя:
chown linuxize: file1
Chown как изменить группу файлов
Чтобы изменить только группу файла, используйте chown команду с двоеточием ( : ) и именем новой группы (без пробелов между ними) и целевой файл в качестве аргумента:
chown :GROUP FILE
Следующая команда изменит группу-владельца файла с именем file1 на www-data :
chown :www-data file1
Еще одна команда, которую вы можете использовать для изменения групповой принадлежности файлов – это chgrp .
Chown как изменить владельца символических ссылок
Когда рекурсивный параметр не используется, chown команда изменяет групповое владение файлами, на которые указывают символические ссылки , а не сами символьные ссылки .
Например, если вы попытаетесь изменить владельца и группу символической ссылки, на symlink1 которую указывает ссылка /var/www/file1 , chown изменит владельца файла или каталога, на который указывает символическая ссылка:
chown www-data: symlink1
Скорее всего, вместо смены целевого владельца вы получите ошибку «невозможно разыменовать symlink1: Permission denied».
Ошибка возникает из-за того, что по умолчанию в большинстве дистрибутивов Linux символические ссылки защищены, и вы не можете работать с целевыми файлами. Эта опция указана в /proc/sys/fs/protected_symlinks . 1 значит включен и 0 отключен. Мы рекомендуем не отключать защиту символических ссылок.
Чтобы изменить групповое владение самой символической ссылкой, используйте -h параметр:
chown -h www-data symlink1
Chown как рекурсивно изменить владельца ссылок
Чтобы рекурсивно работать со всеми файлами и каталогами в данном каталоге, используйте параметр -R ( --recursive ):
chown -R USER:GROUP DIRECTORY
Следующий пример изменит владельца всех файлов и подкаталогов в /var/www каталоге на нового владельца и группу с именем www-data :
chown -R www-data: /var/www
Если каталог содержит символические ссылки, передайте -h опцию:
chown -hR www-data: /var/www
Другими параметрами, которые можно использовать при рекурсивном изменении владельца каталога, являются -H и -L .
Если аргумент, переданный chown команде, является символической ссылкой, указывающей на каталог, эта -H опция заставит команду пройти по ней. -L указывает chown на прохождение каждой символической ссылки в каталог, который встречается. Обычно вы не должны использовать эти параметры, потому что вы можете испортить вашу систему или создать угрозу безопасности.
Chown использование справочного файла
--reference=ref_file Опция позволяет изменить пользователя и группы владельца указанные файлы , чтобы быть такими же , как в указанном отпечатком ( ref_file ). Если ссылочный файл является символической ссылкой, chown будут использоваться пользователь и группа целевого файла.
chown --reference=REF_FILE FILE
Например, следующая команда назначит пользователя и владельца группы file1 для file2
chown --reference=file1 file2
Chown – видео инструкция
Chown – выводы
chown утилита командной строки Linux / UNIX для изменения владельца файла и / или группы
Чтобы узнать больше о chown команде, посетите страницу руководства chown или введите man chown свой терминал.
2022-09-12T12:46:17
Linux
Создаём свой центр сертификации на Linux
Здесь я покажу вам, как можно создать свой центр сертификации и выпускать свои сертификаты для ваших тестовых или внутренних веб серверов.
Введение
Само-подписанные ssl-сертификаты бывают нужны в некоторых случаях:
- При работе с тестовыми веб-серверами. Когда вам всё равно требуется протокол https. Или не требуется, но вам просто хочется использовать https вместо http. То удобно иметь свой центр сертификации и для каждого тестового сайта выпускать ssl-сертификаты.
- При работе с внутренними web-серверами. Если у компании есть свой внутренний сайт или веб-приложение. И этот сайт доступен только из внутренней сети компании. То, вероятно, вам захочется использовать протокол https вместо http. А так как доступ к сайту есть у ограниченного числа компьютеров, то на них можно добавить свой корневой ssl-сертификат. И тогда, эти компьютеры начнут доверять внутренним сайтам компании.
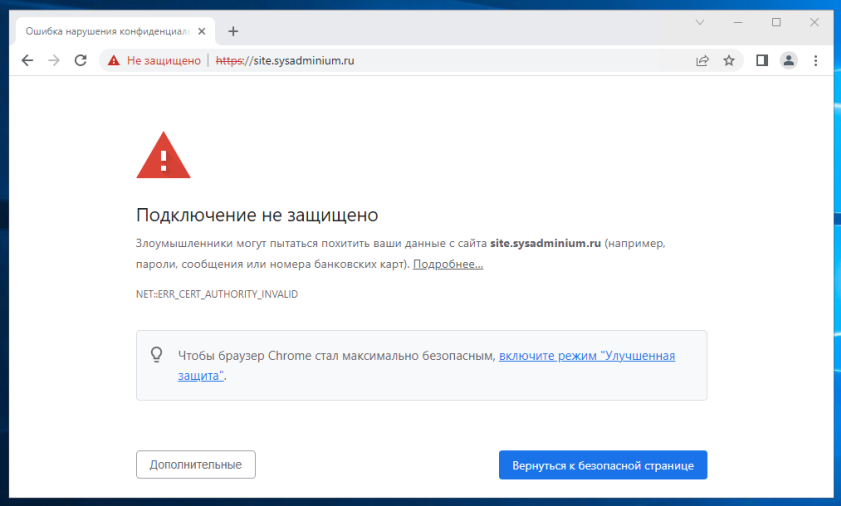
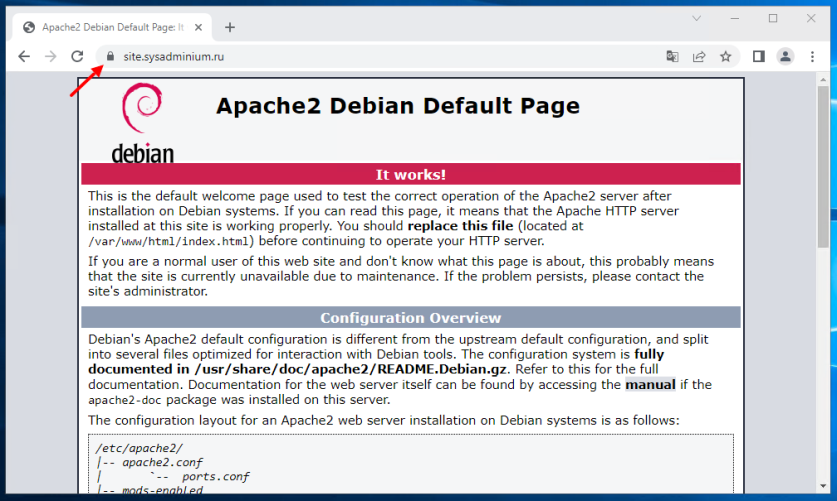
Если вы не знаете, что означает доверие к сертификату сайта, то покажу вам следующие скриншоты.
На этом скриншоте, браузер не доверяет сайту, но если нажать на кнопку «Дополнительные«, то вы всё равно сможете перейти на сайт:
А на этом скриншоте браузер доверяет сайту. Об этом говорит то, что сайт открылся без предупреждений и замочек в адресной строке:
В этой статье я проделаю следующее:
- На Debian 11 установлю apache2 и настрою его работу на https (с сертификатами по умолчанию для localhost).
- Покажу что клиенты пока не доверяют этому сертификату.
- Создам центр сертификации на этом же сервере. А именно:
- создам закрытый корневой ключ и открытый корневой ключ (он же корневой сертификат);
- с помощью этой пары ключей буду выпускать сертификаты для доменов;
- установлю выпущенный корневой сертификат на компьютер клиента (на windows);
- с помощью корневого ключа и сертификата, я выпущу ключ и сертификат для домена (для веб-сервера).
- Затем я настрою apache2 на использование созданных мною закрытого ключа и сертификата для веб-сервера. И продемонстрирую вам что клиентский браузер начал доверять сертификату сайту.
- Дальше я установлю и настрою другой веб-сервер — nginx. Настрою его на работу по протоколу https. И продемонстрирую доверие браузера к сайту.
Устанавливаю apache2
Устанавливаю web-сервер apache2:
$ sudo apt install apache2
Настраиваю его работу по протоколу https:
$ sudo a2enmod ssl $ sudo a2ensite default-ssl.conf $ sudo systemctl restart apache2
Проверяю доверие к ssl-сертификату сайта, открыв его по https:
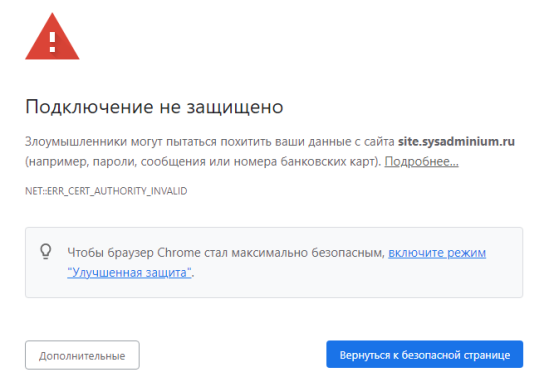
Как видите, доверия нет.
Создаю центр сертификации
Теория
Протокол HTTPS это объединение протоколов HTTP + SSL/TLS. А протокол TLS это асинхронное шифрование. То есть создаётся пара ключей. И то, что один ключ может зашифровать, другой может расшифровать и наоборот. В протоколе HTTPS эти ключи не равнозначные:
- закрытый ключ — это обычный ключ шифрования применяемый в асинхронном шифровании.
- открытый ключ — это тоже ключ шифрования. Но он дополнительно содержит некоторую информацию, например имя домена, имя организации и другое. Такой ключ называют сертификатом.
А ещё протокол TLS позволяет создавать цепочки сертификатов. То-есть, если браузер доверяет родительскому сертификату, то он автоматически будет доверять и всем дочерним сертификатам. А чтобы создать дочернюю пару ключей, нужно иметь доступ к родительской паре ключей.
Корневая пара ключей обычно не подтверждает никакой домен. А используется для создания промежуточных сертификатов или сертификатов для доменов (для web-серверов).
Обычно, когда создают ssl-сертификат для домена, то для безопасности отнимают у него право создания дочерних сертификатов.
Корневой ключ обычно защищают паролем. Это уже симметричное шифрование, когда зная один ключ (пароль) можно зашифровать и расшифровать файл закрытого ключа.
Сервер на котором создают корневые сертификаты, а затем с их помощью выпускают сертификаты для доменов называют — центр сертификации.
Создаю корневой закрытый ключ
Для создания ssl/tls сертификатов можно использовать утилиту openssl, она не требует админских прав.
Создаю корневой закрытый ключ:
$ openssl genpkey -algorithm RSA -out rootCA.key -aes-128-cbc ....................................+++++ ......................+++++ Enter PEM pass phrase: Verifying - Enter PEM pass phrase:
Разберу эту команду:
- genpkey — команда для создания закрытого ключа;
- -algorithm RSA — алгоритм асинхронного шифрования, именно он используется для выделения открытого ключа из этого закрытого;
- -out rootCA.key — получаемый файл закрытого ключа;
- -aes-128-cbc — алгоритм симметричного шифрования, которым мы зашифруем файл закрытого ключа с помощью пароля. Пароль нужно будет ввести.
Создаю корневой сертификат
Теперь создаю корневой сертификат (открытый ключ):
$ openssl req -x509 -new -key rootCA.key -sha256 -days 3650 -out rootCA.crt Enter pass phrase for rootCA.key: You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [AU]:RU State or Province Name (full name) [Some-State]:Moscow Locality Name (eg, city) []:Moscow Organization Name (eg, company) [Internet Widgits Pty Ltd]:Sysadminium Organizational Unit Name (eg, section) []:. Common Name (e.g. server FQDN or YOUR name) []:Sysadminium
Разберу команду:
- req — создаёт сертификаты или запросы на сертификаты;
- -x509 — будем создавать сертификат а не запрос;
- -new — создаём новый сертификат (нужно будет ввести значения некоторых полей в сертификате);
- -key rootCA.key — используемый закрытый ключ, из которого нужно создать открытый;
- -sha256 — алгоритм хеширования, чтобы создать подпись ключа;
- -days 3650 — выпускаем сертификат на 10 лет (обратите внимание что закрытые ключи не имеют срока жизни а сертификаты имеют);
- -out rootCA.crt — получаемый сертификат.
Итак, я создал пару ключей:
$ ls -l root* -rw-r--r-- 1 alex alex 1306 сен 9 11:26 rootCA.crt -rw------- 1 alex alex 1874 сен 9 11:19 rootCA.key
Когда мы будем создавать дочерние сертификаты для доменов, нам понадобится файл с порядковым номером выпускаемых сертификатов. Он должен быть с тем же именем что и корневой ключ, но иметь расширение srl.
Создаю файл порядковых номеров для выпуска сертификатов, в нём следует указать два нуля:
$ nano rootCA.srl 00
Дальше нужно передать корневой сертификат на клиентские компьютеры и установить его в доверенные корневые центры сертификации. Я забираю корневой сертификат по протоколу sftp, показывать этот процесс думаю не нужно.
Установка корневого сертификата на Winows
Устанавливаются сертификаты на Windows очень просто. Дважды щелкаем по сертификату и открывается окно с его свойствами. Дальше нажимаем на кнопку «Установить сертификат«:
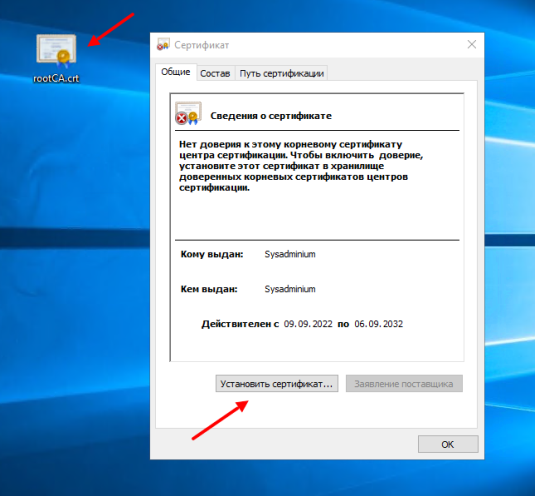
Установить можно для текущего пользователя или для всего компьютера. Так как у меня это тестовая установка, я выберу «Текущий пользователь«:
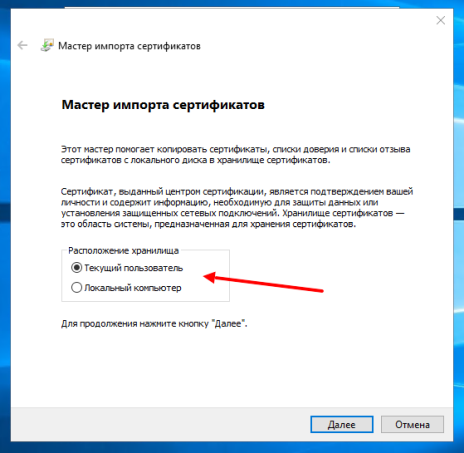
После нажатия на кнопку «Далее» нужно выбрать «Поместить все сертификаты в следующее хранилище» и нажать кнопку «Обзор«:
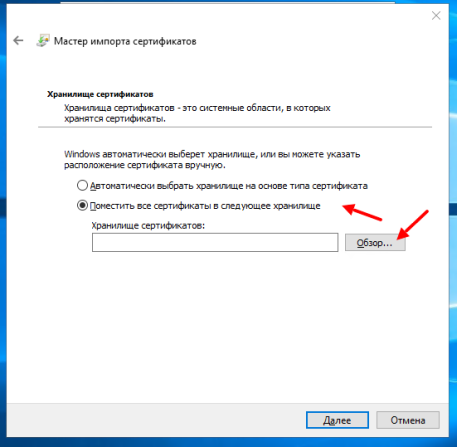
В открывшемся окне выбираем «Доверенные корневые центры сертификации«:
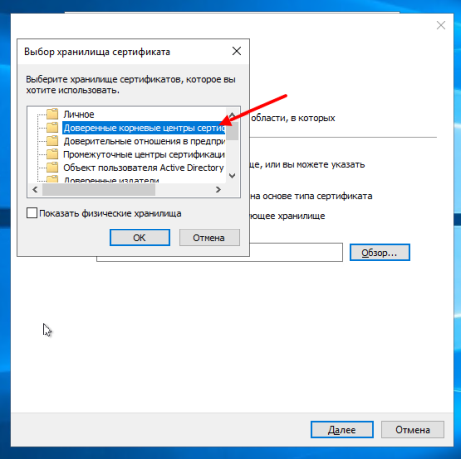
Затем нажимаем кнопку «ОК«, «Далее» и «Готово«.
И наконец, подтверждаем установку сертификата:
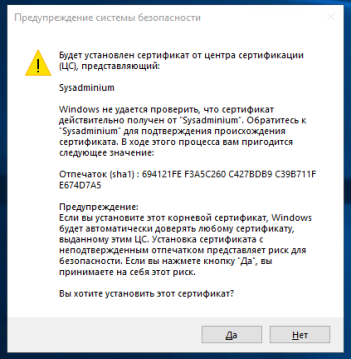
И затем нужно будет ещё раз нажать кнопку «ОК«.
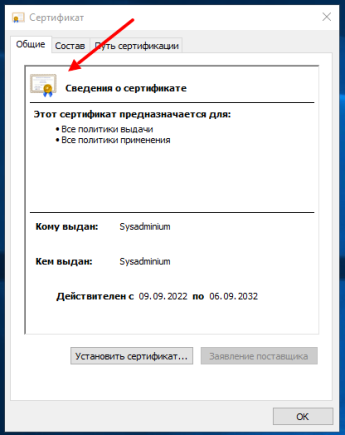
Если вы еще раз откроете свойства сертификата (двойным щелчком по нему), то увидите что система начала ему доверять:
Создаю ключ и сертификат для домена
Теперь, с помощью корневых ключей мы можем создать ключи для домена. У меня будет домен — site.sysadminium.ru.
Утилита openssl не может без конфигурационного файла добавлять некоторые поля. А нам нужно будет в сертификат добавить поле subjectAltName. Без этого поля браузер Chrome не доверяет сертификату.
Поэтому вначале я создаю следующий конфиг:
$ nano sysadminium.cnf [ req ] default_bits = 2048 distinguished_name = req_distinguished_name req_extensions = req_ext [ req_distinguished_name ] countryName = Country Name (2 letter code) countryName_default = RU stateOrProvinceName = State or Province Name (full name) stateOrProvinceName_default = Moscow localityName = Locality Name (eg, city) localityName_default = Moscow organizationName = Organization Name (eg, company) organizationName_default = Sysadminium commonName = Common Name (eg, YOUR name or FQDN) commonName_max = 64 commonName_default = site.sysadminium.ru [ req_ext ] basicConstraints = CA:FALSE keyUsage = nonRepudiation, digitalSignature, keyEncipherment subjectAltName = DNS:site.sysadminium.ru
В блоке [ req ] — настраивается команда req:
- default_bits = 2048 — длина ключа по умолчанию.
- distinguished_name = req_distinguished_name — distinguished_name — это поля в сертификате, например Common Name, organizationName и другие. Для этих полей мы создадим блок req_distinguished_name ниже.
- req_extensions = req_ext — расширение для req, здесь мы можем добавить дополнительные поля в сертификат. А в этом параметре мы просто указываем что ниже будет блок req_ext с дополнительными полями.
Блок [ req_distinguished_name ] — служит для конфигурации полей сертификата.
А блок в блок [ req_ext ] — можно добавить некоторые расширяющие свойства сертификата:
- basicConstraints = CA:FALSE — полученные сертификаты нельзя будет использовать как центр сертификации. Другими словами, забираем у сертификатов для доменов право создавать дочерние сертификаты.
- keyUsage = nonRepudiation, digitalSignature, keyEncipherment — созданный ключ будет иметь следующие свойства: неотказуемость (если ключом что-то подписали то аннулировать подпись невозможно), цифровая подпись (сертификат можно использовать в качестве цифровой подписи), шифрование ключей (сертификат можно использовать для симметричного шифрования). Об этих свойствах на английском хорошо написано здесь.
- subjectAltName = DNS:site.sysadminium.ru — а здесь указываем поле subjectAltName и его значение. Как я уже говорил, без этого поля браузер Chrome не доверяет сертификату.
Создаю закрытый ключ для домена
Теперь я создам закрытый ключ для домена:
alex@deb-11:~$ openssl genpkey -algorithm RSA -out site.key .......................................+++++ .............+++++
Создаю файл запроса для домена
С помощью закрытого ключа для домена создаю файл запроса на сертификат:
$ openssl req -new -key site.key -config sysadminium.cnf -reqexts req_ext -out site.csr You are about to be asked to enter information that will be incorporated into your certificate request. What you are about to enter is what is called a Distinguished Name or a DN. There are quite a few fields but you can leave some blank For some fields there will be a default value, If you enter '.', the field will be left blank. ----- Country Name (2 letter code) [RU]: State or Province Name (full name) [Moscow]: Locality Name (eg, city) [Moscow]: Organization Name (eg, company) [Sysadminium]: Common Name (eg, YOUR name or FQDN) [site.sysadminium.ru]:
Обратите внимание, все параметры были использованы из конфига, вручную мне не пришлось ничего вписывать.
Создаю сертификат для домена
Теперь, с помощью корневых ключей, подписываю файл запроса и создаю сертификат для домена:
$ openssl x509 -req -days 730 -CA rootCA.crt -CAkey rootCA.key -extfile sysadminium.cnf -extensions req_ext -in site.csr -out site.crt
Разберу команду:
- x509 — создание сертификата путём подписывания;
- -req — если подписывать будем файл запроса, то нужно использовать эту опцию;
- -days 730 — сертификат я делаю на 2 года;
- -CA rootCA.crt -CAkey rootCA.key — указываю корневую пару ключей;
- -extfile sysadminium.cnf — файл, содержащий расширения сертификатов. Без этой опции расширения из файла запроса не попадут в сертификат;
- -in site.csr -out site.crt — файл запроса и файл сертификата.
После проделанного у меня появились три файла связанных с сертификатом для домена:
$ ls -l site.* -rw-r--r-- 1 alex alex 1257 сен 9 14:27 site.crt # сертификат -rw-r--r-- 1 alex alex 1098 сен 9 14:17 site.csr # запрос -rw------- 1 alex alex 1704 сен 9 14:15 site.key # ключ
Перенастраиваю apache2
Кинем сертификат и ключ в следующие каталоги:
$ sudo cp site.crt /etc/ssl/certs/ $ sudo cp site.key /etc/ssl/private/
И настроим apache2 на использование этих ключей:
$ sudo nano /etc/apache2/sites-enabled/default-ssl.conf SSLCertificateFile /etc/ssl/certs/site.crt SSLCertificateKeyFile /etc/ssl/private/site.key
Применим изменение конфига apache2:
$ sudo systemctl reload apache2
И проверим как открывается наш сайт с клиента на котором установлен наш корневой сертификат:
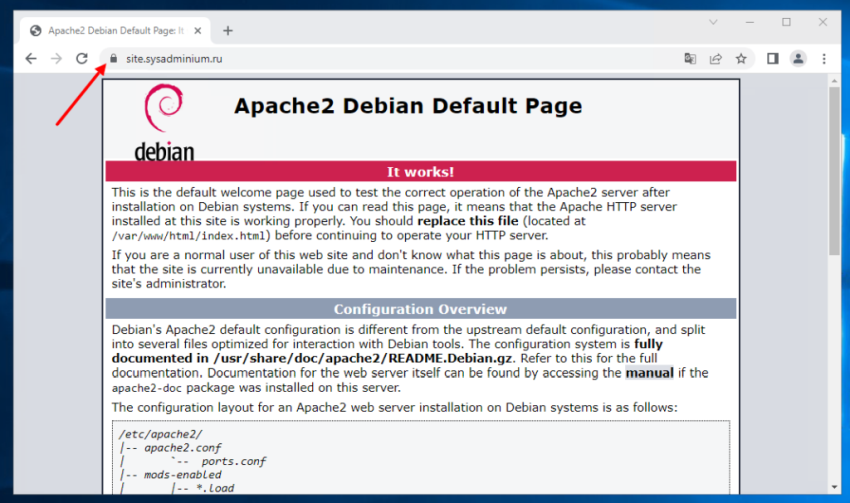
Как видим, браузер начал доверять нашему тестовому сайту.
Смотрим на сертификат из Chrome
Нажмите на замочек возле адреса сайта (он виден на скриншоте выше). Дальше нажмите на «Безопасное подключение» и на «Действительный сертификат«. Откроются свойства сертификата:
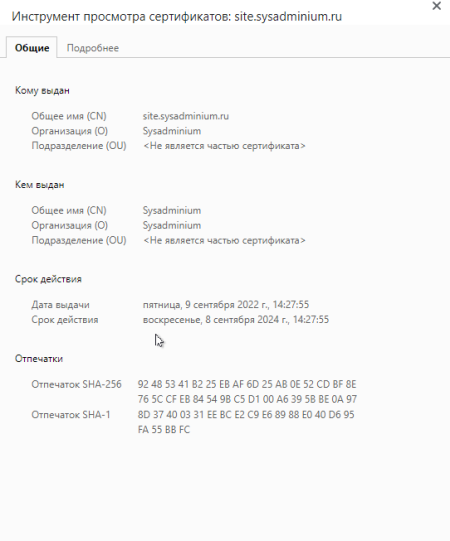
На вкладке «Подробнее» вы можете изучить и остальные свойства.
Например, помните мы указывали алгоритм ассиметричного шифрования — RSA:
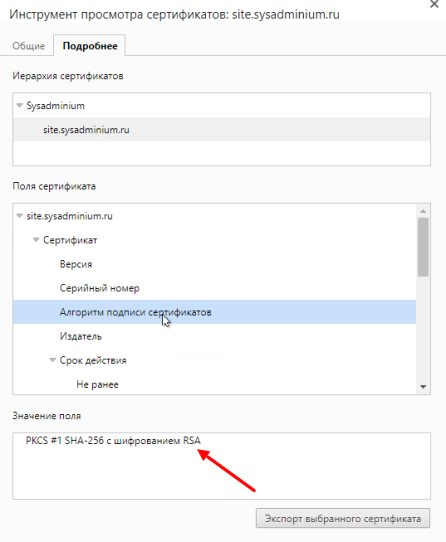
А помните, мы создали файл для серийных номеров выпускаемых сертификатов и записали в нём «00». Давайте посмотрим на серийный номер нашего сертификата:
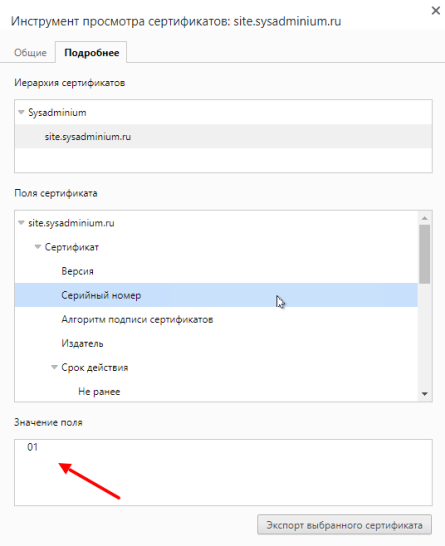
Можем посмотреть на сам открытый ключ:
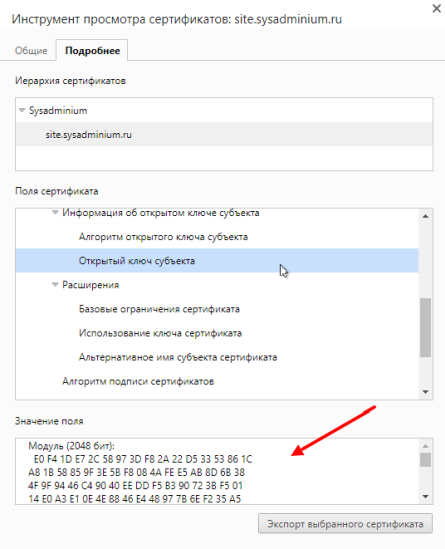
А в расширениях видно альтернативное имя, которое так нужно браузеру Chrome для доверия к сертификату:
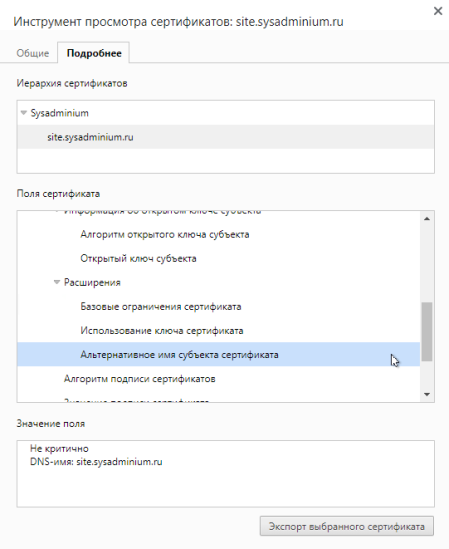
Раньше браузеры проверяли только CN:
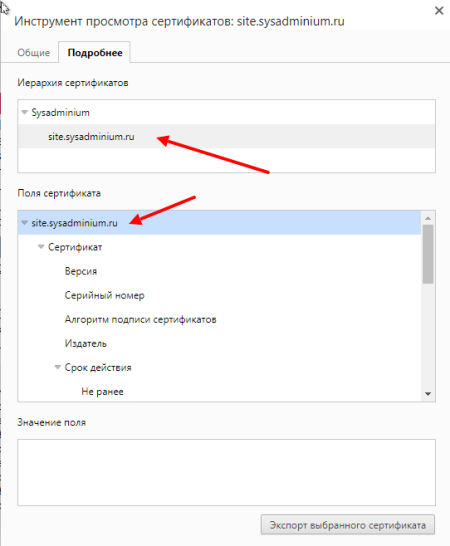
А сейчас, если есть альтернативное имя, то они даже не смотрят в параметр Common Name. А Chrome требует это поле и вообще перестал смотреть на Common Name.
Настраиваю веб-сервер Nginx
Ну и наконец я покажу как настроить Nginx на использование наших сертификатов.
Для начала выключу apache2 и установлю nginx:
$ sudo systemctl stop apache2.service $ sudo apt install nginx
И настрою его. Нужно рас-комментировать и поменять значения некоторых полей:
$ sudo nano /etc/nginx/sites-enabled/default listen 443 ssl default_server; listen [::]:443 ssl default_server; ssl_certificate /etc/ssl/certs/site.crt; ssl_certificate_key /etc/ssl/private/site.key;
Применю изменения:
$ sudo systemctl reload nginx
И наконец, проверю доверие к ssl-сертификату сайта, обновив страничку в браузере.
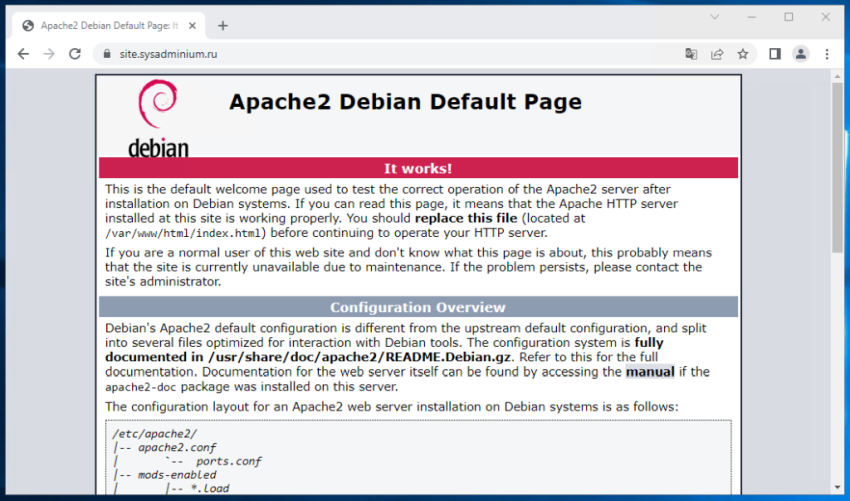
Здесь apache2 создал свою индексную страничку, поэтому оба веб сервера (nginx и apache2) используют одну и туже страницу. Но как вы помните, я отключил apache2, так что у меня точно отвечает nginx.
Итог
Надеюсь я смог объяснить, как сделать свой центр сертификации и начать выпускать свои собственные сертификаты для доменов. Мы создали следующие файлы:
- rootCA.key — корневой закрытый ключ. Используется для создания дочерних сертификатов. Обычно лежит на сервере центра сертификации и зашифрован с помощью пароля.
- rootCA.srl — корневой сертификат. Используется для создания дочерних сертификатов. Его нужно распространить на все ваши компьютеры и установить в хранилище корневых сертификатов. Его тоже можно защитить паролем, но я этого не делал.
- site.key — ключ для домена (для веб сервера). Его можно было сгенерировать на веб-сервере и не передавать на сервер центра сертификации. Но в моём примере был один сервер и для веб-сервера и для центра сертификации.
- site.csr — файл запроса на сертификат для домена. Его также можно было сделать на веб-сервере и передать в центр сертификации, чтобы там выпустить сертификат.
- site.crt — сертификат для домена (для веб сервера). Этот файл создаётся из файла запроса на сертификат с помощью пары корневых ключей.
Также я показал, как использовать созданные сертификаты для настройки веб серверов: apache2 и nginx.
Если вы интересуетесь настройками веб-серверов на Linux, то возможно вам также понравится эта статья:
2022-09-12T11:53:52
Сервера Linux