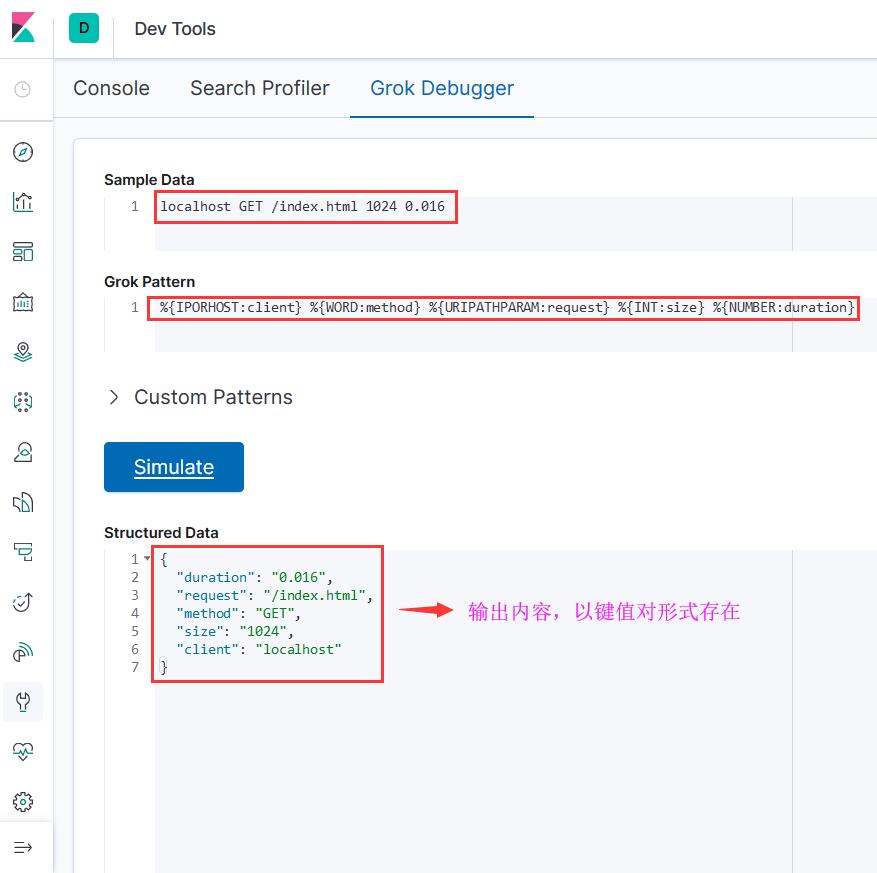
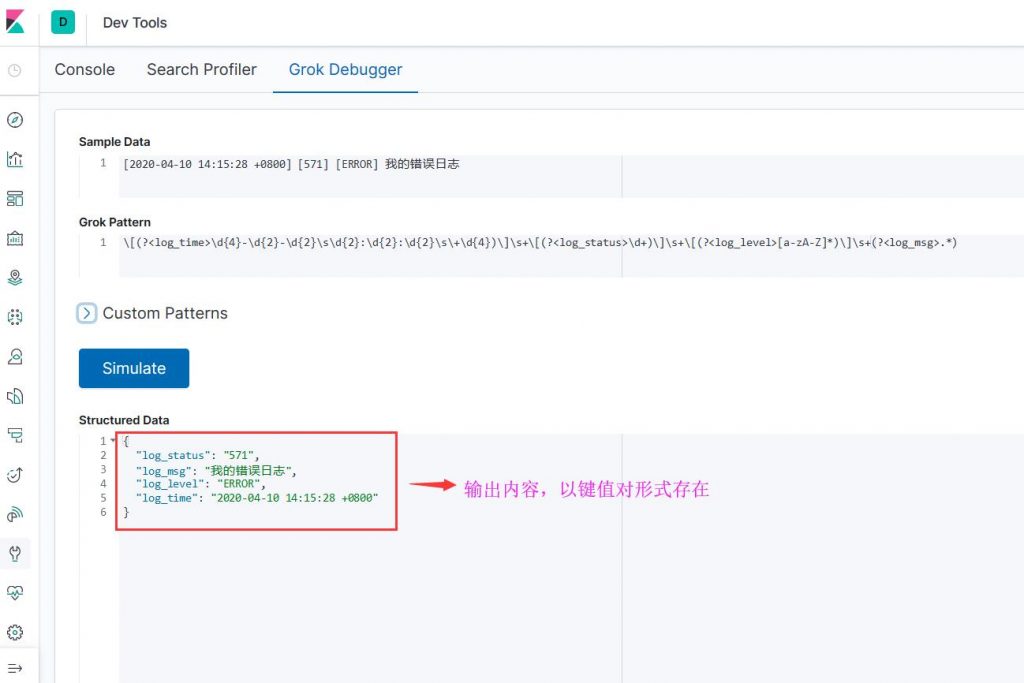
Grok — это инструмент, который объединяет несколько предопределенных регулярных выражений для сопоставления сегментированного текста и сопоставления с ключевыми словами.
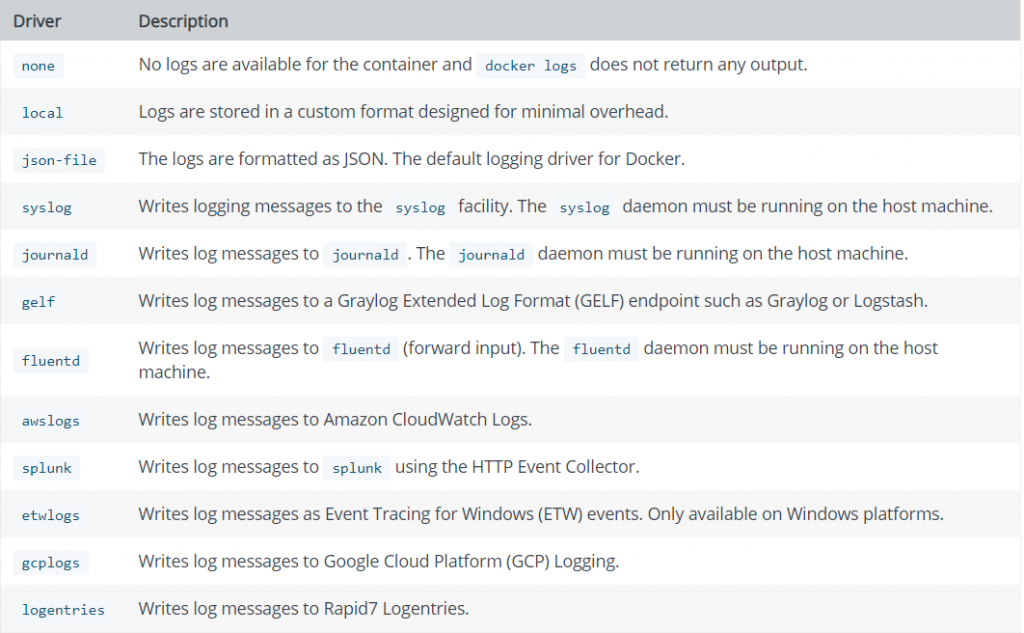
Когда контейнер запускается, он фактически является подпроцессом docker deamon. Docker daemon может получить стандартный вывод процесса в контейнере, а затем обработать его через собственный модуль LogDriver. LogDriver поддерживает множество способов и по умолчанию записывает в локальные файлы. Его также можно отправить в системный журнал и т. Д.
Docker по умолчанию соберет стандартный вывод приложения в файл json.log и построчно сохранит данные в формате JSON. Формат файла следующий:
Graylog — это инструмент управления полными журналами с открытым исходным кодом с функциями, аналогичными ELK. Docker изначально поддерживает протокол graylog, а Graylog также официально поддерживает Docker, которые могут быть легко соединены. Graylog официально предоставляет Dockerfile для развертывания системы ведения журнала в Docker, а также предоставляет файл docker-compose.yml для быстрого развертывания всего стека Graylog. Подробное содержимое можно просмотреть по адресу http://docs.graylog.org/en/3.1/pages/installation/docker.html.
1. Создайте каталог graylog в текущем каталоге пользователя в качестве рабочего каталога для развертывания:
$ mkdir graylog
$ cd graylog
2. Инициализируйте каталог и файлы конфигурации
$ mkdir -p ./graylog/config
$ cd ./graylog/config
$ wget https://raw.githubusercontent.com/Graylog2/graylog-docker/3.1/config/graylog.conf
$ wget https://raw.githubusercontent.com/Graylog2/graylog-docker/3.1/config/log4j2.xml
# Кроме того, поскольку Graylog определяет пользователей и группы пользователей с идентификатором 1100,
# Причина Graylog может сообщить о недостаточных разрешениях ошибки каталога конфигурации при запуске, которая может быть решена с помощью следующей команды
chown -R 1100:1100 ./graylog/config
3. Измените файл конфигурации. Файл graylog.conf, полученный на предыдущем шаге, является конфигурацией по умолчанию, предоставленной официальным лицом. Пользователи могут конфигурировать в соответствии со своими потребностями. Например, часовой пояс в конфигурации по умолчанию — часовой пояс UTC, который можно изменить на часовой пояс Китая
5. Запустите «docker-compose up», чтобы запустить службу. После того, как служба запустится нормально, вы можете получить доступ к веб-интерфейсу graylog через http: // ip: 9000. Пользователь по умолчанию — admin / admin.
Сбор журналов Graylog осуществляется путем определения входных данных. Вы можете выбрать вход для сбора журналов на вкладке Система на странице веб-управления Graylog.
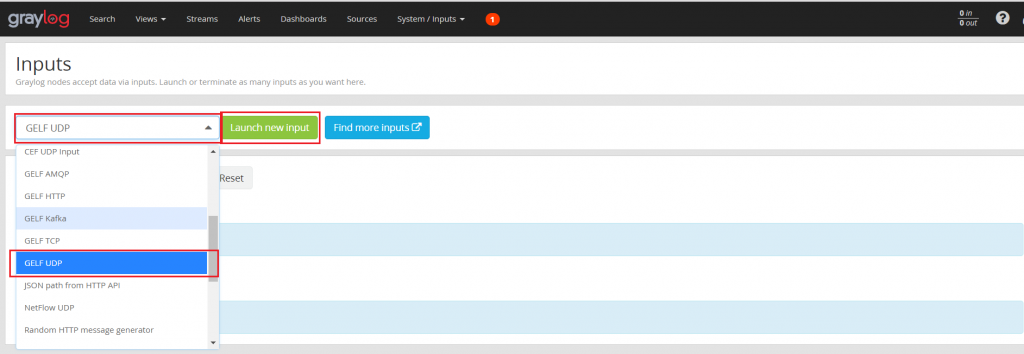
После входа на страницу ввода выберите тип ввода, такой как определение ввода GELF UDP:
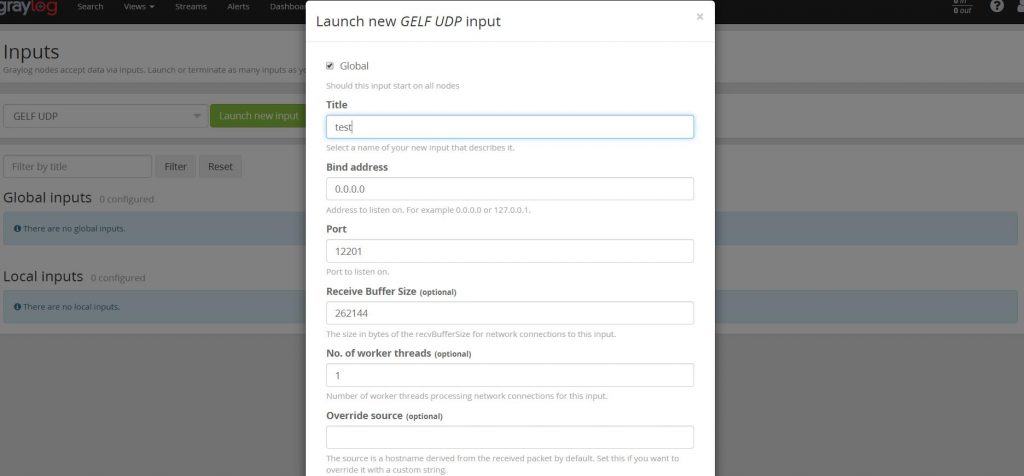
После завершения выбора нажмите «Lanch new input», чтобы ввести подробную конфигурацию ввода, а после ее завершения сохраните.
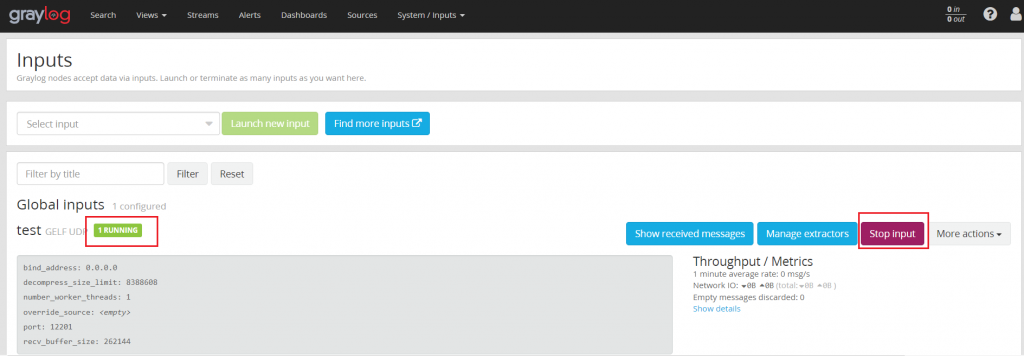
Если после сохранения все в порядке, вход перейдет в состояние RUNNING, а затем вы сможете отправить данные на этот вход. Нажмите «Stop input», вход остановится, прием данных прекратится, и «Stop input» станет «Начать ввод», нажмите «Пуск», когда вам нужно принять данные.
При настройке контейнера Docker для отправки данных в Graylog, вы можете добавить следующие параметры при запуске команды docker run для запуска контейнера:
docker run --log-driver=gelf
--log-opt gelf-address = udp: // адрес серого журнала: 12201
--log-opt tag = <текущий тег службы контейнера, используемый для классификации при запросах graylog>
<IMAGE> <COMMAND>
Конкретные примеры:
docker run -d
--log-driver=gelf
--log-opt gelf-address=udp://localhost:12201
--log-opt tag="{{.ImageName}}/{{.Name}}/{{.ID}}"
busybox sh -c 'while true; do echo "Graylog test message"; sleep 10; done;'
Если контейнер запускается командой docker-compose, вы можете добавить следующую конфигурацию в файл docker-compose.yml:
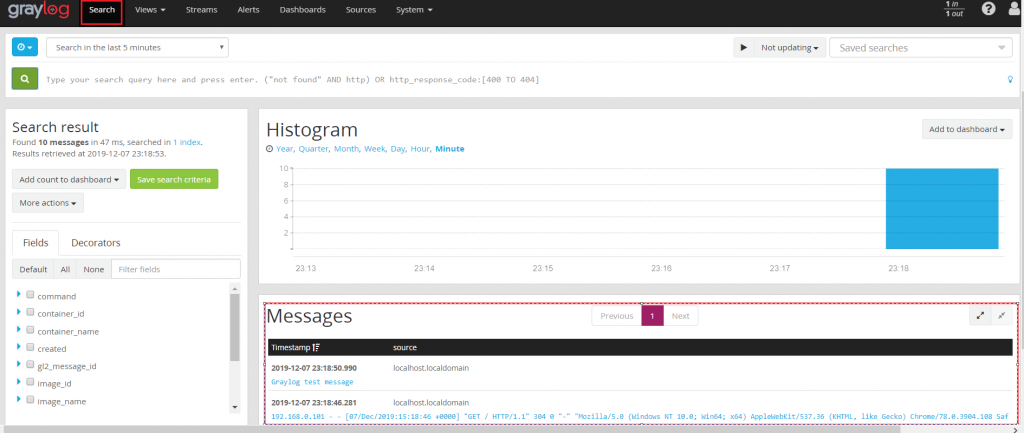
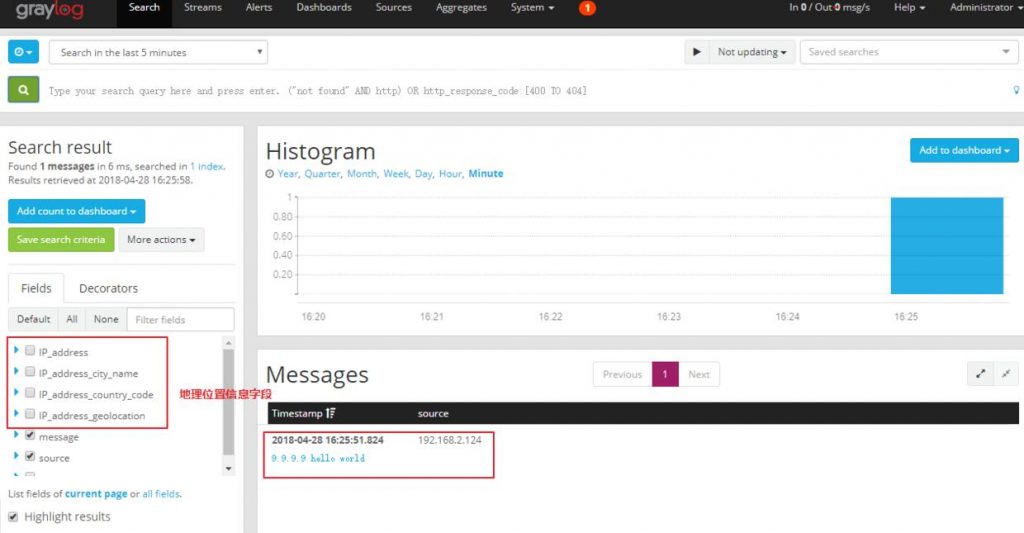
В процессе использования graylog для сбора журналов нетрудно обнаружить, что существует «Карта мира», показывающая географическое местоположение. Если вы просто нажмете на позицию на картинке ниже, 99% не покажет вам нужную карту, и появится красное сообщение об ошибке (оставшиеся 1% на самом деле не будут успешными ^). Так как же открыть эту «карту мира»? Следующее содержание этой статьи будет представлено подробно.
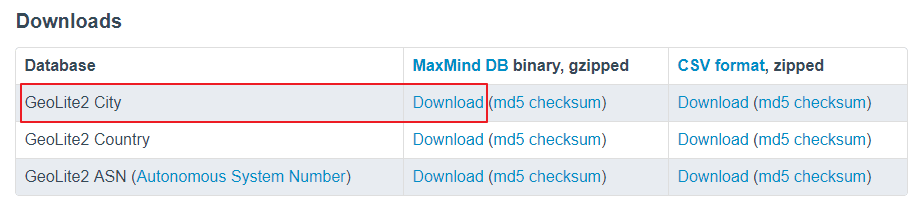
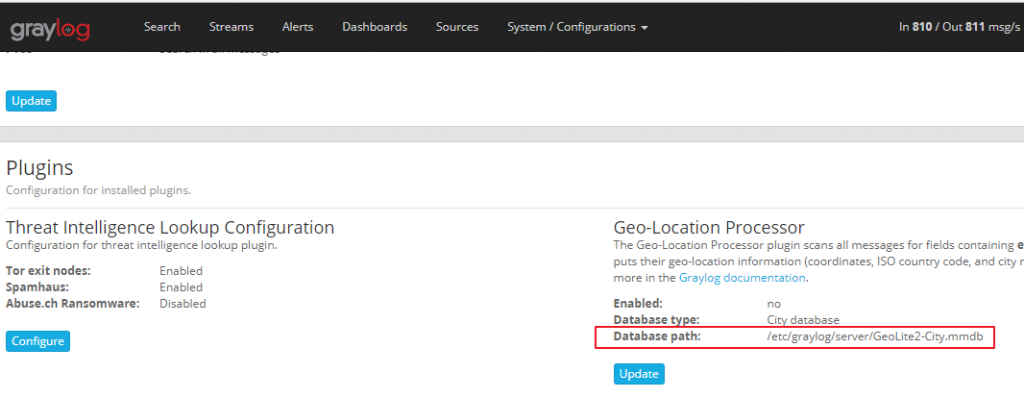
Настройте базу данных 1. Разархивируйте загруженный сжатый пакет. 2. В зависимости от способа установки изменитеGeoLite2-City.mmdbПоместите файл в нужное место. Я установил Graylog в форме RPM. Нажмите «Система-> Конфигурации» в веб-интерфейсе Graylog. Вы можете увидеть размещение файлов по умолчанию, как показано ниже:
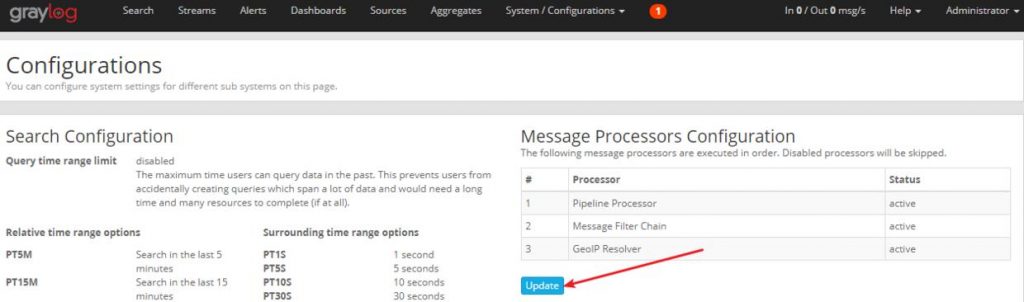
3. Обновить процессор географического местоположения. Нажмите «Система-> Конфигурации» в веб-интерфейсе graylog и нажмите кнопку «Обновить» на рисунке ниже:
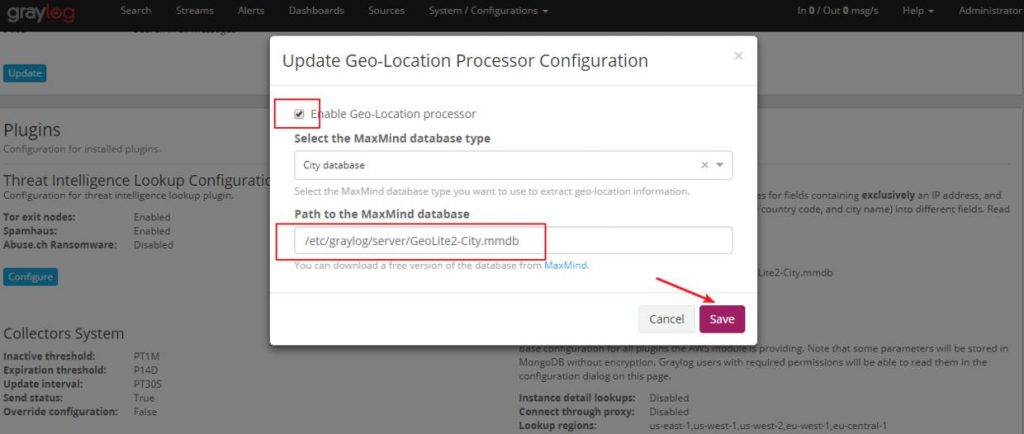
Установите флажок Включить, проверьте размещение файлов и нажмите кнопку «Сохранить», чтобы сохранить конфигурацию.
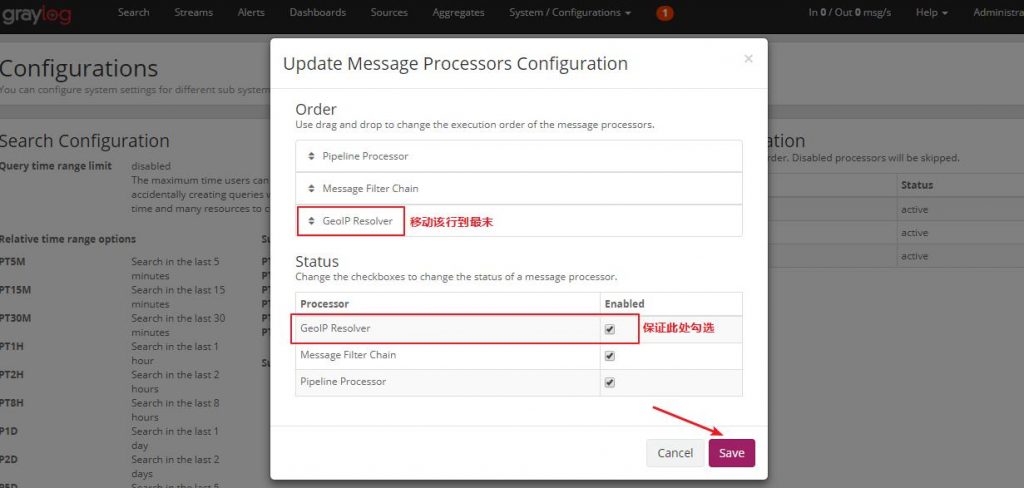
Настройте процессоры GeoIP Resolver Нажмите кнопку «Обновить», чтобы обновить конфигурацию:
Переместите строку GeoIP Resolver, установите в качестве последнего обработчика сообщений распознаватель GeoIP, включите GeoIP Resolver и нажмите кнопку «Сохранить», чтобы сохранить настройки:
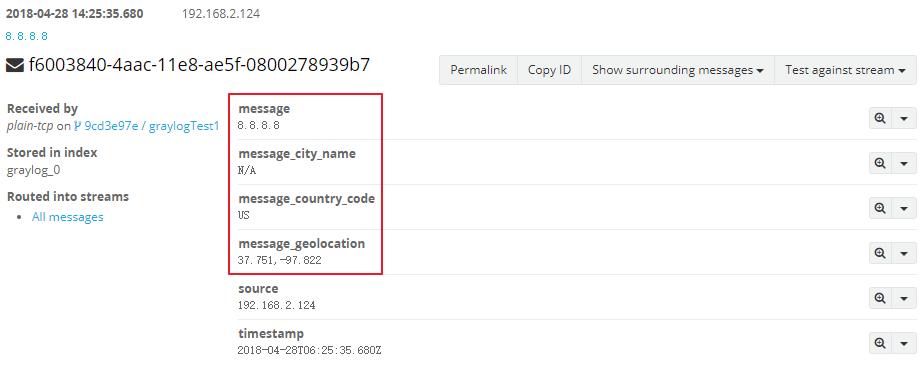
тест На этом этапе настройка завершена. Graylog начнет искатьСодержит только Поле адреса IPv4 или IPv6 и извлечение его географического местоположения в<field>_geolocationПоле. Короче если у вас есть полеfield1Если содержимое является только IP-адресом, graylog сохранит географическое местоположение на основе IP-адреса этого поля.field1_geolocationДюйм
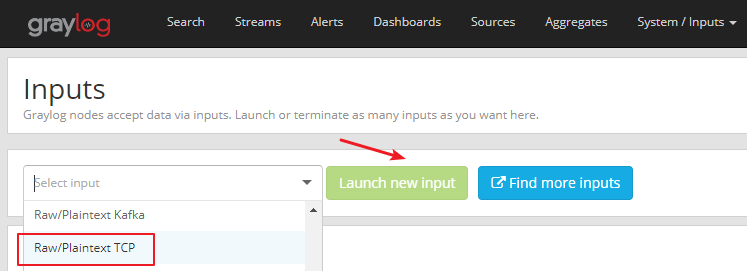
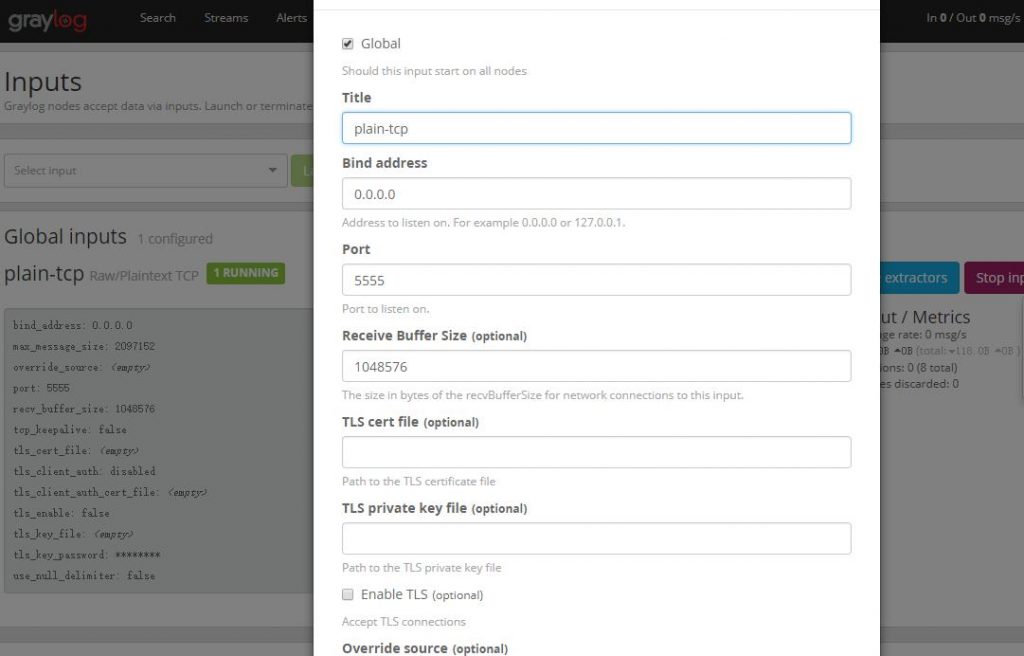
Давайте проверим это ниже: 1. Нажмите «System-> Inputs», чтобы создать ввод типа Raw / Plaintext TCP.
Вы можете увидеть эффект, показанный на следующем рисунке:
Поле сообщения на рисунке выше содержит только IP-адрес, и затем Graylog будет расширен в соответствии с этим IP-адресом.message_city_name、message_country_code、 message_geolocationТри поля
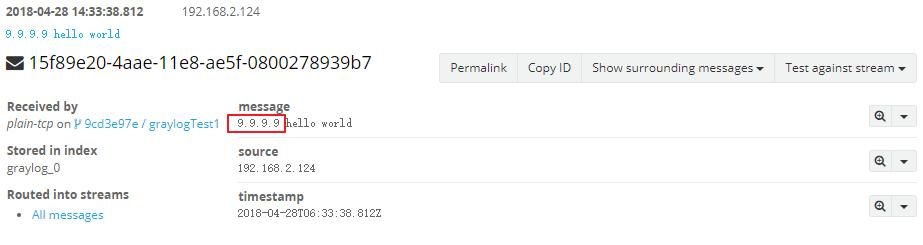
Если ваш IP-адрес не существует один в каком-либо поле, вы можете использовать Extractor для извлечения IP-адреса для сохранения в виде поля, а затем Graylog может определить географическое местоположение. Как показано на рисунке ниже, поле сообщения содержит адрес 9.9.9.9. В это время можно извлечь Extractor для извлечения.
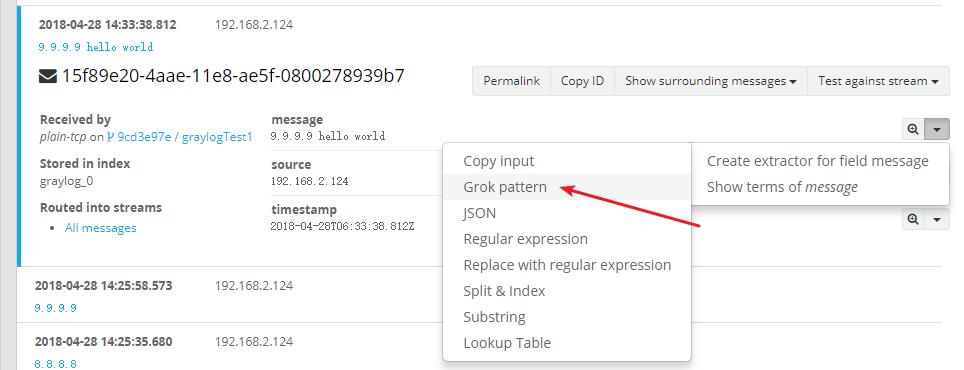
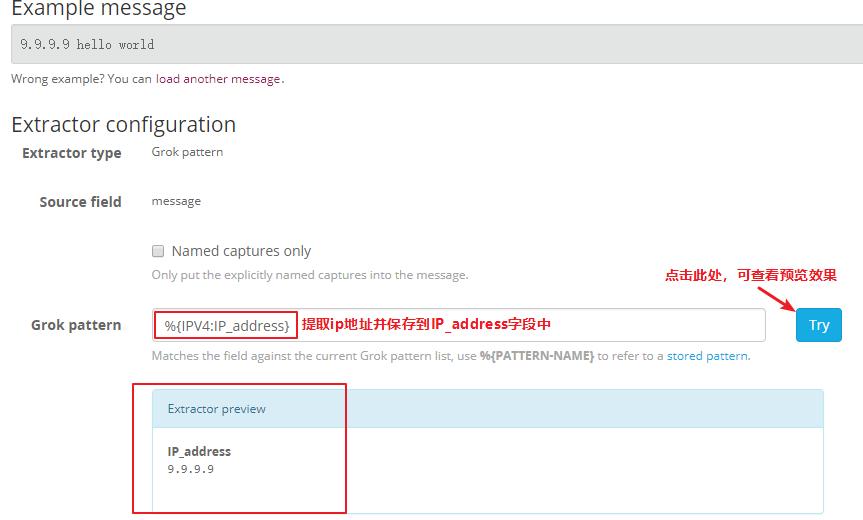
Создать Extractor для извлечения IP Формат адреса ip относительно фиксирован. Мы можем использовать шаблон Grok для сопоставления. Шаблон Grok уже имеет существующие правила сопоставления ip, поэтому нам не нужно писать регулярно.
После завершения, когда мы получаем вышеуказанное сообщение, эффект выглядит следующим образом:
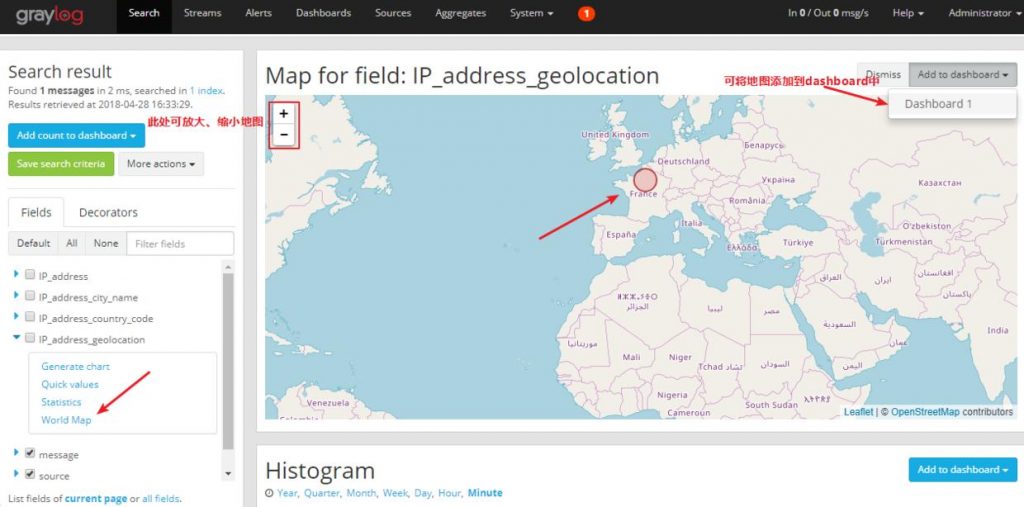
Показать карту
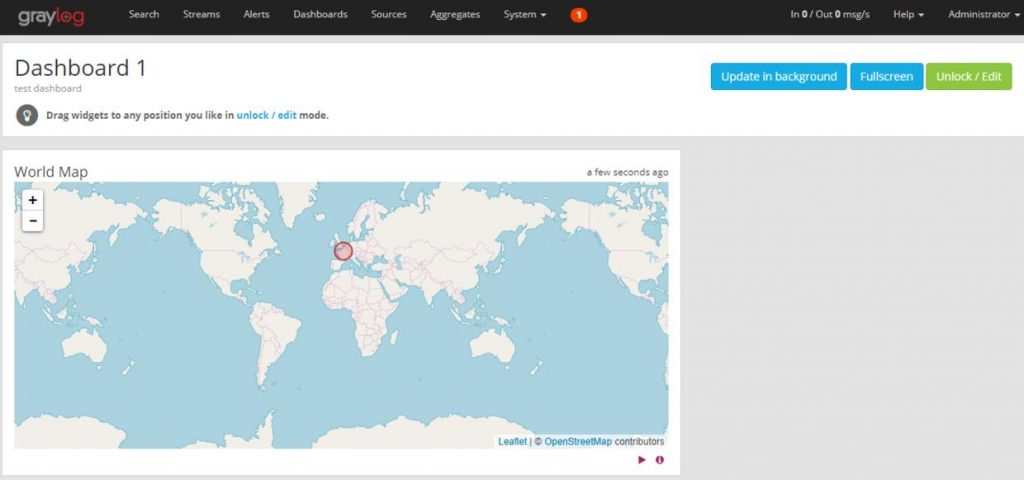
Когда это появляется<field>_geolocationПосле поля нажмите на поле «Карта мира», чтобы увидеть местоположение на карте.
Graylog официальная документацияGeolocationДля подробного ознакомления эта статья является только записью процесса настройки, которая следует за официальной документацией, только для справки.
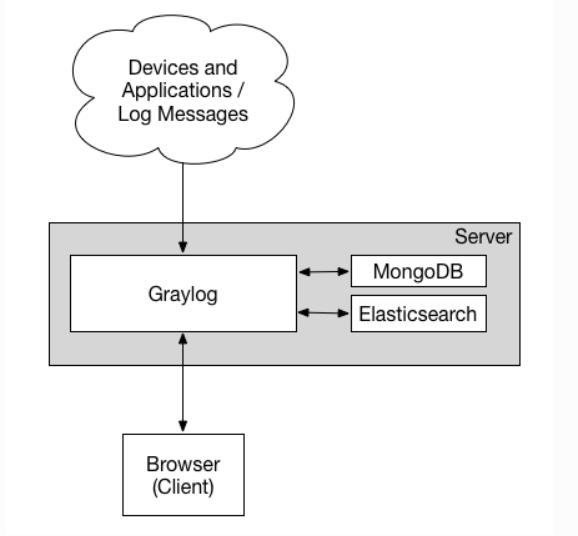
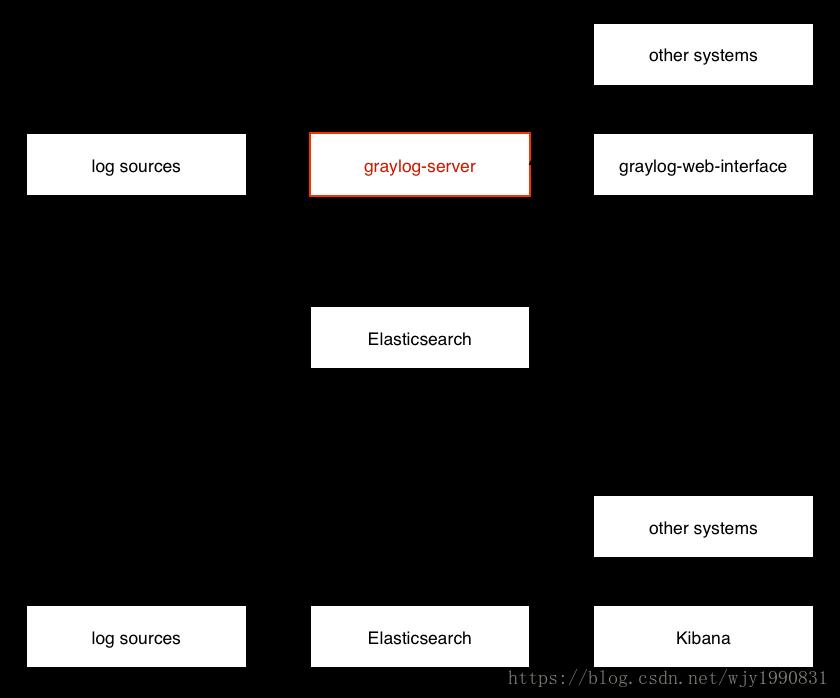
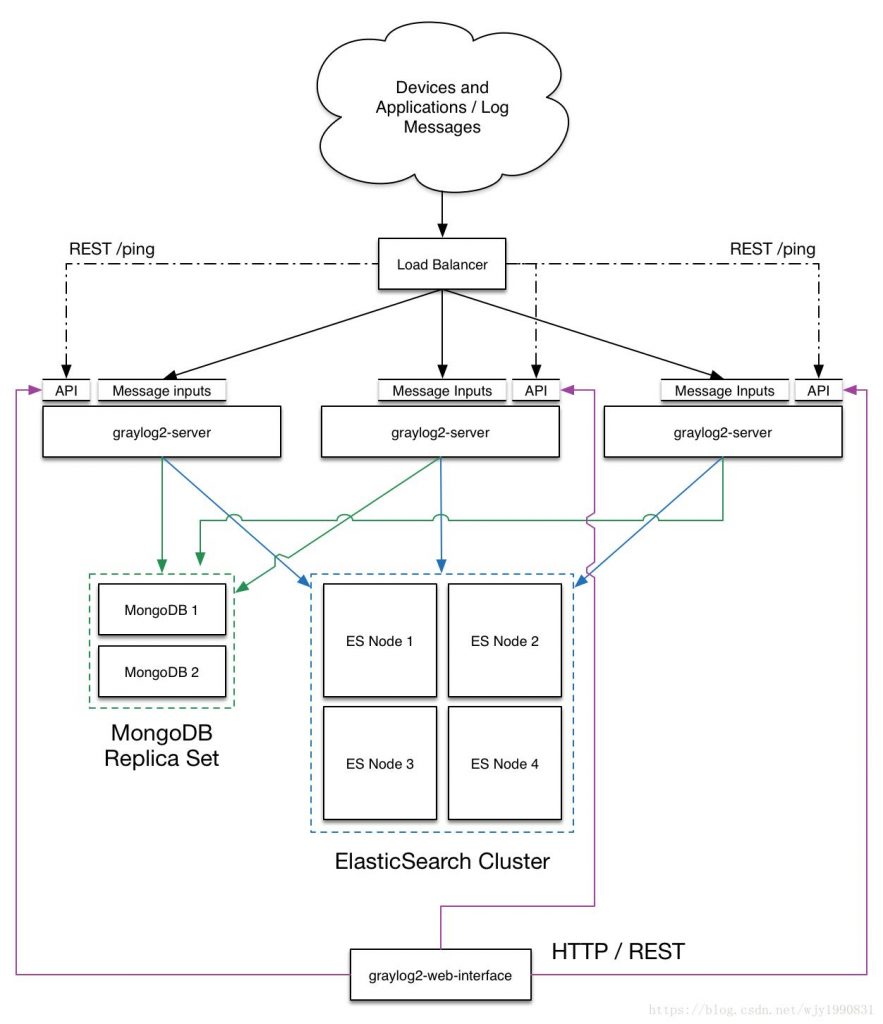
I. Введение в соответствующие компоненты платформы Garylog
Graylog-сервер: Graylog получает журналы от различных внутренних приложений и предоставляет интерфейс веб-доступа
Graylog Collector Sidecar: отвечает за сбор журналов приложений и отправку их на Graylog-сервер
Elasticsearch: используется для индексации и сохранения полученных журналов, производительность зависит от памяти и ввода-вывода жесткого диска
MongoDB: отвечает за сохранение информации о конфигурации Graylog, нагрузка не высокая
GeoIP_CityDatabase: анализ журналов Ngnix через Graylog, получение IP-адреса посетителя, а затем использование базы данных GeoIP2 для анализа географического местоположения IP.
Простота развертывания и обслуживания, простота в использовании и интегрированное решение
По сравнению с синтаксисом json от ES синтаксис поиска относительно прост, и результаты поиска можно выделить
Встроенное простое оповещение можно вспомнить через веб-API или по электронной почте
Может напрямую экспортировать поисковый JSON-файл для облегчения разработки поисковых скриптов, которые вызывают остальные API
Три, диаграмма архитектуры Garylog
Установка одного узла
Подходит для небольшого сбора журналов, установки тестовой среды, без избыточности, но для быстрой установки и развертывания, в данной статье используется этот метод установки
Кластерная установка
Это подходит для производственных сред. Балансировка нагрузки добавляется до того, как несколько узлов Graylog развернуты в кластере. ElasticSearch и MongoDB развернуты. Балансировщик нагрузки может проверить, является ли узел нормальным. Если узел отключен, вы можете удалить узел
В-четвертых, установка и настройка Graylog
1.jdk установка
Версия установки jdk1.8.0_161, процесс установки (опущен)
Установка 2.ElasticSearch
Установочная версия —asticsearch-5.6.11, установлен плагин x-pack, а также инструмент управленияasticsearch-head
Плагин для сегментации китайского словаasticsearch-analysis-ik-5.6.11 ,asticsearch-analysis-pinyin-5.6.11
Обратите внимание, что версия ElasticSearch, соответствующая Graylog2.4, не может быть выше 5.x, иначе она не может быть установлена
Обратите внимание, что версия ElasticSearch, соответствующая Graylog 2.3 и более ранним версиям, не может быть выше 4.x, в противном случае она не может быть установлена
(1) Установить эластичный поиск-5.6.11
Распаковать эластичный поиск-5.6.11.tar.gz, tar -zxf эластичный поиск-5.6.11.tar.gz -C / usr / local
Измените конфигурациюasticsearch.yml следующим образом
Elasticsearch не может быть запущен пользователем root, вам нужно создать новый эластичный пользователь, переключиться на эластичный и запустить
./elasticsearch -d
Посетите http://10.10.10.1:9200/ через браузер и верните информацию, относящуюся кasticsearch, что означает, что запуск прошел успешно
(2) Установите x-pack
bin /asticsearch-plugin установите x-pack, следуйте инструкциям и нажмите Next для установки
(3) установить китайское слово segmenter ik и пиньинь
Перейдите в /usr/local/elasticsearch-5.6.11/plugins и распакуйте файлasticsearch-analysis-ik-5.6.11.zip в каталог ik
Перейдите в /usr/local/elasticsearch-5.6.11/plugins, разархивируйте файлasticsearch-analysis-pinyin-5.6.11.zip в каталог pinyin и перезапустите эластичный поиск
Введите в браузере следующий адрес: если появляется слово сегментация, настройка выполнена успешно.
Prometheus server настраивается через два места: жопу и голову аргументы запуска и конфигурационный файл. Настройку через переменные окружения в Prometheus не завезли и не планируют.
Это зависит от того, как вы будете их использовать. В идеале надо иметь два набора метрик: краткосрочные на пару недель и долгосрочные на несколько месяцев. Первые нужны, чтобы оперативно отслеживать ситуацию, вторые — чтобы видеть тенденцию на больших промежутках времени. Но это большая тема, заслуживающая отдельной статьи, а пока сделаем по-простому. Длительность хранения метрик указывается в аргументах запуска Prometheus. Есть две опции:
--storage.tsdb.retention.time=... определяет как долго Prometheus будет хранить собранные метрики. Длительность указывается так же, как и в PromQL для диапазонного вектора: 30d — это 30 дней. По умолчанию метрики хранятся 15 дней, потом исчезают. К сожалению нельзя одни метрики хранить долго, а другие коротко, как, например, в Graphite. В Prometheus лимит общий для всех.
--storage.tsdb.retention.size=... определяет сколько дискового пространства Prometheus может использовать под метрики. По-моему эта опция удобнее предыдущей: можно указать всё свободное место на диске и получить настолько долгие метрики, насколько это возможно при любом их количестве. На практике однако нельзя указывать свободное место впритык. Дело в том, что у БД метрик есть журнал упреждающей записи (WAL), который в этом лимите не учитывается. Я не понял от чего зависит максимальный размер WAL, поэтому какие-то рекомендации по запасу не могу дать. У меня максимальный размер WAL был 8 ГБ.
Если вы устанавливали Prometheus по моей инструкции без докера, то аргументы запуска вам надо прописать в /etc/systemd/system/prometheus.service в параметре ExecStart, после чего выполнить две команды:
scrape_interval — периодичность опроса экспортеров (scrape дословно с английского — это соскабливать, соскребать). В отличие от длительности хранения метрик, может быть разной для разных метрик. Во всех мануалах я встречал цифру в 15 секунд, но почему-то никто не объяснял эту магическую константу. Почему не 2, 5 или 10? В целом так: чем меньше интервал, тем выше будет разрешение графиков и тем больше места потребуется для хранения метрик. Видимо 15 секунд — это золотая середина, найденная опытным путём.
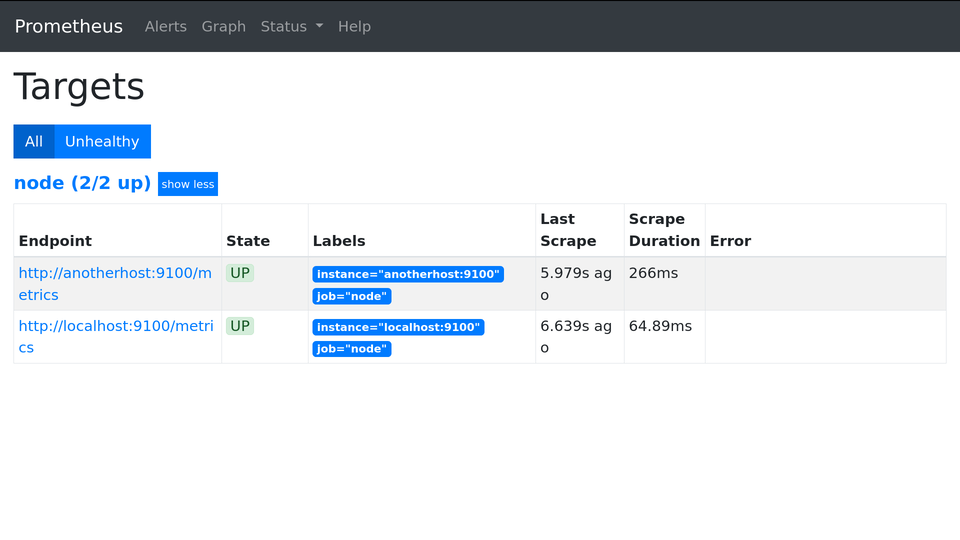
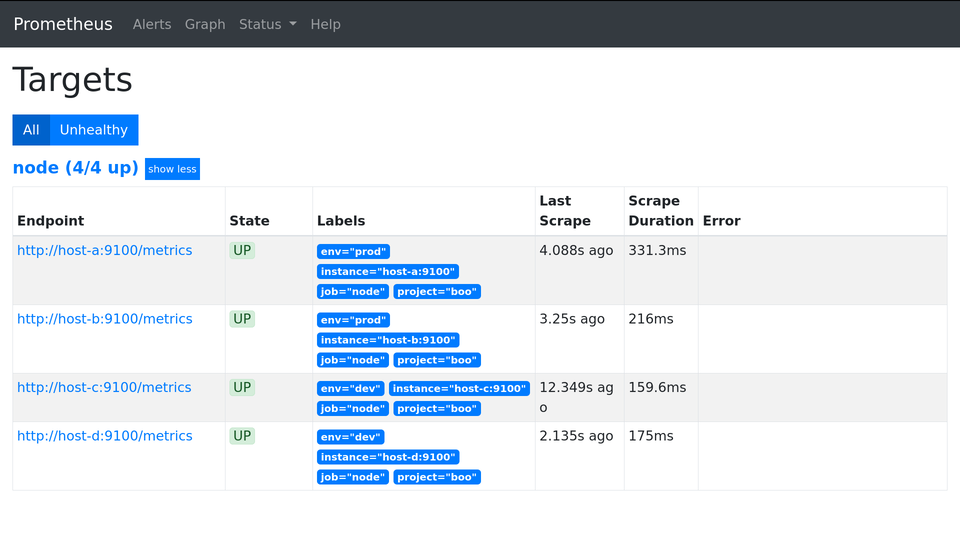
job_name — имя (для Prometheus’а) для данной группы метрик. job_name будет светиться в интерфейсе Prometheus’а на вкладке Targets, а также попадёт в метку job для группы метрик c этих машин:
Как правильно подобрать имя для job_name ? Я пробовал разные варианты и в итоге остановился на простом правиле: называть job’ы в соответствии с экспортерами: node для node_exporter, cadvisor для cadvisor’а и т.д.
После редактирования конфига надо попросить Prometheus’а перечитать свой конфиг. Для этого надо послать ему сигнал SIGHUP одним из способов:
# systemctl reload prometheus
или
$ docker kill --signal=SIGHUP prometheus
Метки можно вешать любые на ваш вкус, не только project и env.
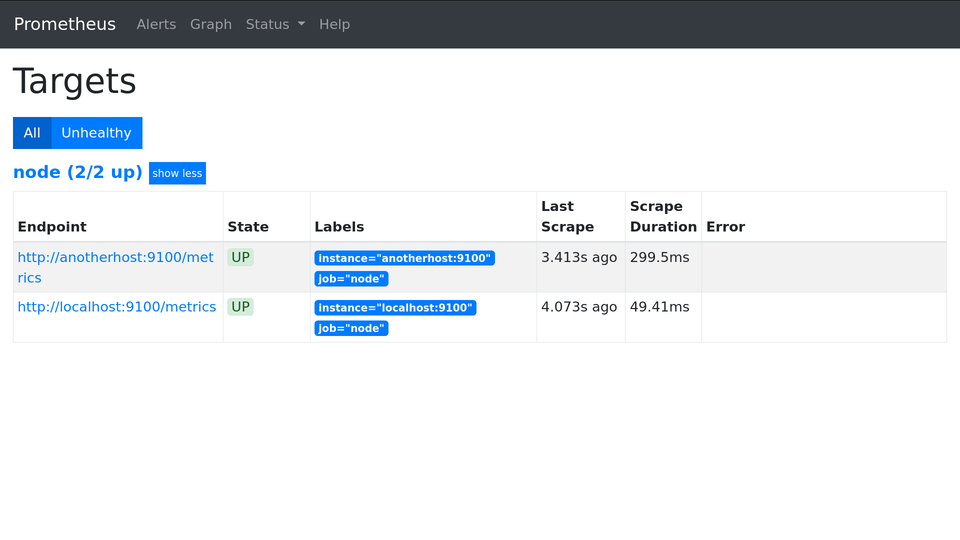
Как убрать номер порта из таргетов
Я не люблю лишнее. Вот зачем мне номер порта в метке instance? Какая от него польза? Он только сообщает, что node_exporter работает на порту 9100, но является ли эта информация полезной? Нет. Поэтому порт надо скрыть:/etc/prometheus/prometheus.yml
Expression: up
1up{instance="localhost:9100",job="node"}
1up{instance="anotherhost:9100",job="node"}
Service discovery
Service discovery — это автоматическое обнаружение целей. Суть в том, что Prometheus будет получать список целей из какого-то внешнего источника: consul, openstack или что-то ещё. Service discovery — удобная штука, особенно если у вас инфраструктура развёрнута в облаке и машины регулярно рождаются и умирают.
Самый простой service discovery работает на файликах. В конфиге пишем так:/etc/prometheus/prometheus.yml
Prometheus засунет в джобу node все таргеты из файлов, которые лежат в /etc/prometheus/sd_files/ и оканчиваются на _nodeexporter.yml. Всё это будет работать без перечитывания конфига.
Пример файла с таргетами:/etc/prometheus/sd_files/boo_nodeexporter.yml
Удобно держать таргеты разных проектов в разных файлах. В моём примере лишь один проект с названием “boo”, остальные делаются по аналогии. Думаю разберётесь.
Чем отличается перечисление таргетов непосредственно в prometheus.yml от перечисления в отдельных файлах? В первом случае надо давать команду перечитывания конфига при редактировании, а во втором нет.
В прошлой статье я говорил, что Prometheus — это не готовое решение, а скорее фреймворк. Чтобы использовать его возможности полноценно, надо разбираться. Что ж, начнём.
PromQL — это про то, как вытаскивать метрики не из экспортеров, а уже из самого Prometheus’а. Например, чтобы узнать сколько ядер у процессора, надо написать:
count(count(node_cpu_seconds_total) without (mode)) without (cpu)
PromQL дословно расшифровывается как Prometheus query language, т.е. язык запросов. Он не имеет ничего общего с SQL, это принципиально другой язык. Поначалу он казался мне каким-то запутанным, а документация не особо помогала. Потихоньку разобрался и мне даже понравилось.
Prometheus server хранит все данные в виде временных последовательностей (time series). Каждая временная последовательность определяется именем метрики и набором меток (labels) типа ключ-значение (key-value). Давайте сразу посмотрим несколько примеров в Prometheus web UI. Напомню, он работает на localhost:9090. Чтобы не городить скриншотов, я буду показывать запросы в своём псевдо-терминале, а вы не ленитесь и пробуйте у себя.
Prometheus разрабатывался так, чтобы наблюдать за группой машин было так же легко, как за одной. И метки этому способствуют. Прежде всего они позволяют фильтровать вывод:
Кроме = и != есть ещё совпадение и несовпадение с регулярным выражением: =~, !~. Лирическое отступление: мне не нравится одинарное равно для точного сопадения. Это против правил. Должно быть двойное! Эх, молодёжь… А вот разницы в кавычках я не заметил: одинарные и двойные работают одинаково. Да, если задать несколько условий, они будут объединяться логическим И.
Возьмём другой пример. Посмотрим свободное место на дисках:
Не обязательно указывать одинаковый фильтр для всех операндов, как я только что сделал. Достаточно одного, а дальше Prometheus сам возьмёт пересечение по меткам. Следовательно, последний запрос можно с чистой совестью сократить до такого:
Как видите, можно умножать или делить на скаляр и не важно что это: константа или результат вычисления. Вообще я заметил, что в PromQL действует правило: пиши осмысленные запросы и всё будет хорошо. Не надо пытаться сложить диск с процессором и делить на память.
Агрегация
По меткам можно делать агрегацию. Смысл агрегации в том, чтобы объединить несколько однотипных метрик в одну. Например, посчитать максимальный (или средний) load average среди машин определённой группы.
Expression: foo by (label) (some_metric_name)
или
Expression: foo(some_metric_name) by (label)
Синтаксис непривычный, но вроде ничего. Все эти скобочки являются обязательными, без них работать не будет. Пробуем на нашем load average:
Expression: avg by (job)(node_load1)
0.7{job="node"}
Expression: max by (job)(node_load1)
0.96{job="node"}
Expression: min by (job)(node_load1)
0.44{job="node"}
Expression: sum by (job)(node_load1)
1.4{job="node"}
Expression: count by (job)(node_load1)
2{job="node"}
Метки работают как измерения в многомерном пространстве. Агрегация с использованием by как бы схлопывает все измерения, кроме указанного. В примере с node_load1 это не очень заметно, потому что у меня мало меток и хостов. Ок, вот пример получше:
Эта метрика показывает сколько времени каждое ядро работало в каждом режиме. В сыром виде от неё никакого толку, но сейчас это не важно. Важно, что у неё куча меток: cpu, instance, job, mode.
Expression: max by (instance) (node_cpu_seconds_total)
18309.45{instance="localhost:9100"}
3655352.98{instance="anotherhost:9100"}
Expression: max by (instance, cpu) (node_cpu_seconds_total)
17623.34{cpu="3",instance="localhost:9100"}
18295.97{cpu="0",instance="localhost:9100"}
3529407.76{cpu="0",instance="anotherhost:9100"}
18252.21{cpu="1",instance="localhost:9100"}
3655379.15{cpu="1",instance="anotherhost:9100"}
18334{cpu="2",instance="localhost:9100"}
Expression: max without (mode) (node_cpu_seconds_total)
3655736.46{cpu="1",instance="anotherhost:9100",job="node"}
18752.74{cpu="2",instance="localhost:9100",job="node"}
18022.19{cpu="3",instance="localhost:9100",job="node"}
18716.18{cpu="0",instance="localhost:9100",job="node"}
3529779.38{cpu="0",instance="anotherhost:9100",job="node"}
18670.74{cpu="1",instance="localhost:9100",job="node"}
Оператор without работает как by, но в другую сторону, по принципу: “что получится, если убрать такую-то метку”. На практике лучше использовать именно without, а не by. Почему? Дело в том, что Prometheus позволяет навесить кастомных меток при объявлении таргетов, например разный env для машин тестового и боевого окружений (как это сделать). При составлении запроса вы заранее не знаете какие дополнительные метки есть у метрики и есть ли они вообще. А если и знаете, то не факт, что их число не изменится в будущем… В любом случае при использовании by все метки, которые не были явно перечислены, пропадут при агрегации. Это скорее всего будет некритично в дашбордах, но будет неприятностью в алертах. Так что лучше подумать дважды, прежде чем использовать by. Попробуйте самостоятельно поиграться с агрегациями и понять как формируется результат. Полный список агрегирующих операторов вы найдёте в документации.
Считаем ядра
В принципе у вас уже достаточно знаний, чтобы самостоятельно посчитать ядра процессора, но я всё равно покажу. Для решения задачи нам нужна метрика node_cpu_seconds_total и оператор count, который показывает сколько значений схлопнулось при агрегации:
Результат получился правильный, но хочется видеть лишь две строчки: одну для localhost и вторую для anotherhost. Для этого предварительно надо избавиться от метки mode любым из способов:
Expression: count(node_cpu_seconds_total) without (mode)
или
Expression: max(node_cpu_seconds_total) without (mode)
Итоговый запрос:
Expression: count(count(node_cpu_seconds_total) without (mode)) without (cpu)
4{instance="localhost:9100",job="node"}
2{instance="anotherhost:9100",job="node"}
Да, мне тоже кажется, что получение простой по смыслу метрики (число ядер) выглядит как-то заковыристо. Как будто мы ухо ногой чешем. Привыкайте.
Мгновенный и диапазонный вектор
Простите, я не смог придумать лучшего перевода. В оригинале это называется instant and range vector. Сейчас мы смотрели только мгновенные вектора, т.е. значения метрик в конкретный момент времени. Почему вообще результат запроса называется вектором? Вспоминаем, что Prometheus ориентирован на работу с группами машин, не с единичными машинами. Запросив какую-то метрику, в общем случае вы получите не одно значение, а несколько. Вот и получается вектор (с точки зрения алгебры, а не геометрии). Возможно, если погрузиться в исходный код Prometheus, всё окажется сложнее, но, к счастью, в этом нет необходимости.
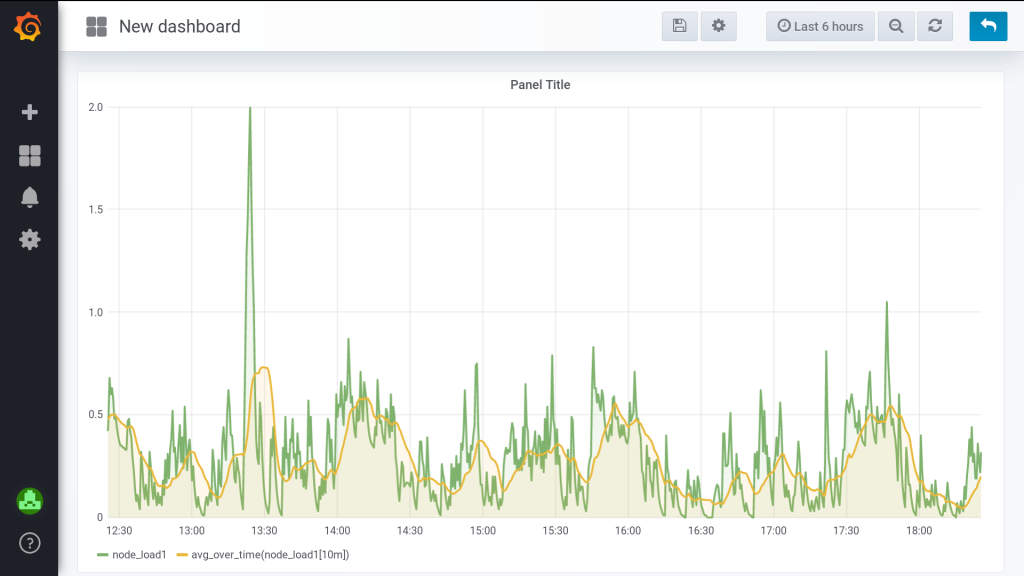
Диапазонный вектор (range vector) — это вектор, который хранит диапазон значений метрики за определённый период времени. Он нужен, когда этого требует арифметика запроса. Проще всего объяснить на графике функции avg_over_time от чего-нибудь. В каждый момент времени она будет вычислять усреднённое значение метрики за предыдущие X минут (секунд, часов…). По-научному это называется “скользящее среднее” (moving average). На словах как-то сложно получается, лучше взгляните на эти 2 графика:
Оранжевый получен из зелёного усреднением за 10 минут. Да, это был мой любимый load average:
Собственно, диапазонный вектор — это когда мы дописываем временной интервал в квадратных скобочках. Интервал времени для диапазонного вектора указывается очень по-человечески: 1s — одна секунда, 1m — одна минута, 1h — один час, 1d — день. А что, если нужно указать полтора часа? Просто напишите 90m.
Домашнее задание: посмотрите на графики max_over_time и min_over_time.
Типы метрик
Метрики бывают разных типов. Это важно, потому что для разных типов метрик применимы те или иные запросы.
Шкала (gauge). Самый простой тип метрик. Примеры: количество свободной/занятой ОЗУ, load average и т.д.
Счётчик (counter). Похож на шкалу, но предназначен совершенно для других данных. Счётчик может только увеличиваться, поэтому он подходит только для тех метрик, которые по своей природе могут только увеличиваться. Примеры: время работы CPU в определённом режиме (user, system, iowait…), количество запросов к веб-серверу, количество отправленных/принятых сетевых пакетов, количество ошибок. На практике вас не будет интересовать абсолютное значение счётчика, вас будет интересовать первая производная по времени, т.е. скорость роста этого счётчика, например количество запросов в минуту или количество ошибок за день.
Гистограмма (histogram). Я пока не сталкивался с таким типом, поэтому ничего путного не скажу.
Саммари (summaries). Что-то похожее на гистограммы, но другое.
Сырое значение счётчика не несёт никакого смысла, его надо оборачивать функцией rate или irate. Эти функции принимают на вход диапазонный вектор, поэтому правильный запрос выглядит так:
В чём разница между rate и irate? Первая функция для вычисления производной берёт весь диапазон (5 минут в нашем случае), а вторая берёт лишь два последних сэмпла из всего диапазона, чтобы максимально приблизиться к мгновенному значению (первоисточник). Собственно, её название расшифровывается как instant rate.
Почему мы берём диапазонный вектор за 5 минут, а не за 1 или 10? Не знаю. Почему-то так делают во всех примерах и в дашборде Node exporter full тоже так. Для rate получается, что чем меньше интервал, тем больше пиков, а чем больше интервал, тем сильнее их сглаживание. Ну, с математикой не поспоришь. Для irate величина диапазона не имеет значения. На самом деле при определённых обстоятельствах всё-таки имеет, но это настолько тонкий нюанс, что на него можно забить.
Другой вопрос: 1210 — это в каких попугаях? Во-первых смотрим исходную метрику, там явно написано bytes. Функция rate делит исходную размерность на секунды, получается байт в секунду. Вообще Prometheus предпочитает стандартные единицы измерения: секунды, метры, ньютоны и т.п. Как в школе на уроках физики.
Считаем загрузку процессора
С памятью, диском и трафиком понятно, а как посмотреть загрузку процессора? Отвечаю. То, что мы привыкли считать загрузкой процессора в процентах на самом деле вот какая штука: сколько времени (в процентном отношении) процессор не отдыхал, т.е. не находился в режиме idle.
Итак, всё начинается с метрики node_cpu_seconds_total. Сначала посмотрим сколько времени процессор отдыхал:
Любопытно, что сумма всех режимов работы процессора никогда не доходит до 100% времени:
Expression: sum (irate(node_cpu_seconds_total[5m])) without (mode)
{cpu="0",instance="anotherhost:9100",job="node"} 0.9739999999999347
{cpu="0",instance="localhost:9100",job="node"} 0.9991578947368495
{cpu="1",instance="anotherhost:9100",job="node"} 0.9083157894731189
{cpu="1",instance="localhost:9100",job="node"} 0.9985964912280734
{cpu="2",instance="localhost:9100",job="node"} 0.998456140350873
{cpu="3",instance="localhost:9100",job="node"} 0.9983508771929828
Почему так? Хороший вопрос. Я подозреваю, что оставшаяся часть времени уходит на переключение контекста процессора. Получается, что загрузка процессора, полученная по формуле выше, будет чуть-чуть завышенной. В действительности можно не переживать по этому поводу, потому что погрешность получается незначительная. Это просто у меня anotherhost работает на старом процессоре Intel Atom. На нормальных взрослых процессорах погрешность не превышает десятые доли процента.
И это всё?
Думаю, на сегодня достаточно. Да, я рассказал не про все возможности PromQL. Например, за кадром остались операторы ignoring и on, логические and и or а также сдвиг offset. Есть всякие интересности типа производной по времени deriv или предсказателя будущего predict_linear. При желании вы сможете почитать про них в документации: операторы и функции. Я же вернусь к ним, когда мы будем решать практические задачи мониторинга.