В этом посте описаны шаги, которые можно предпринять для установки дополнительных пакетов программного обеспечения в Ubuntu Linux.
Когда вы устанавливаете Ubuntu и выбираете обычную установку, она поставляется с пакетами или программами, которые вы можете использовать для выполнения своих повседневных задач. Эти пакеты по умолчанию не являются полным списком, который вам нужен.
Возможно, вам потребуется установить дополнительное программное обеспечение, которое еще не установлено. Приложения в Ubuntu Linux доступны в двух форматах: пакеты Snap и Debian.
Пакет snap будет называться snap. Пакеты Debian — это те, которые заканчиваются расширениями.DEB. Если приложение доступно в обоих форматах, Ubuntu Software сначала перечисляет приложения snap.
Ниже описано, как установить дополнительное программное обеспечение в Ubuntu Linux.
Как установить программное обеспечение в Ubuntu Linux
Как описано выше, если вам нужны дополнительные программы, которые еще не установлены в Ubuntu Linux, вы можете легко сделать это из приложения Ubuntu Software.
Ниже описано, как это сделать.
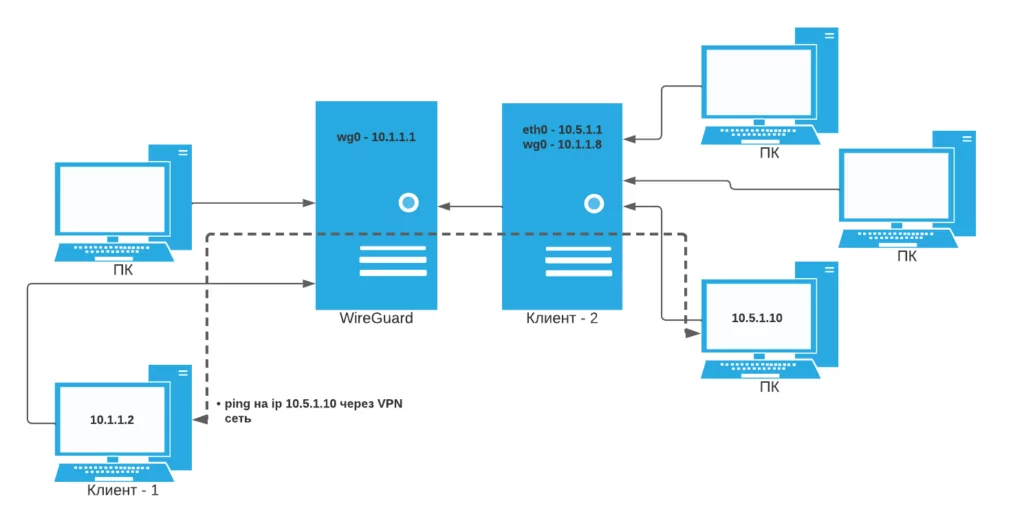
Щелкните значок Ubuntu Software на панели Dock или выполните поиск программного обеспечения в строке поиска «Обзор действий».
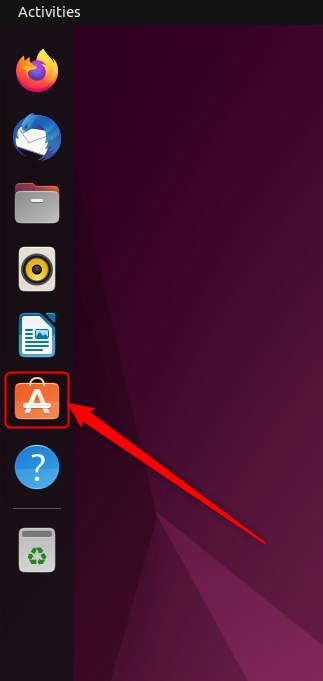
При запуске Ubuntu Software выполните поиск приложения или выберите категорию и найдите приложение из списка.
По умолчанию он открывается на вкладке «Обзор». Вкладка «Установленные» включает в себя все установленное программное обеспечение. На вкладке «Обновления» отображается список программного обеспечения, для которого доступны обновления.
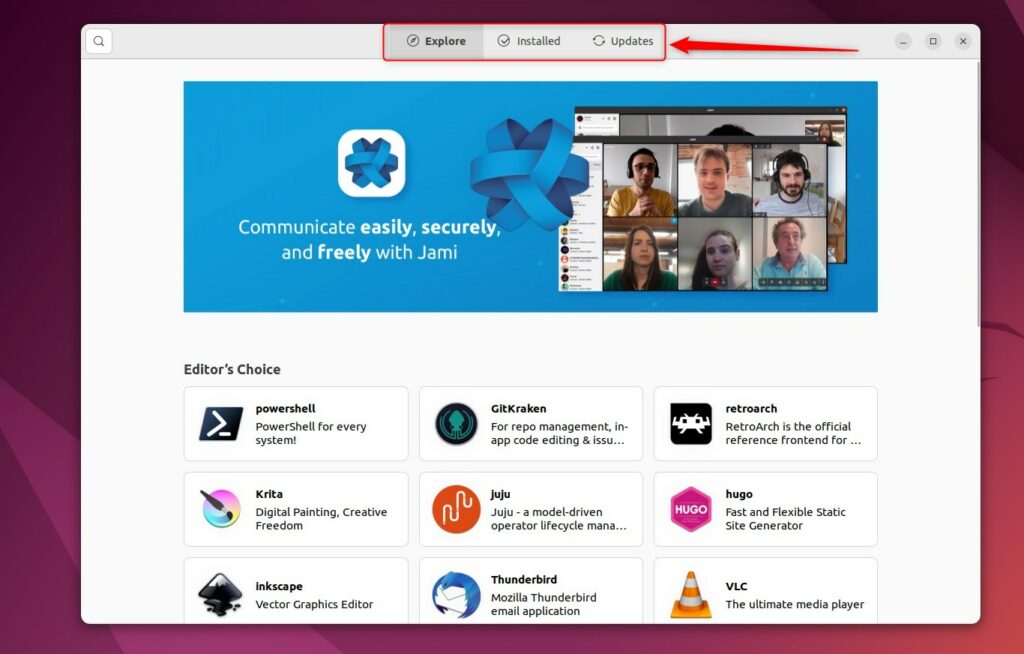
Если вы прокрутите немного вниз, вы увидите раздел «Категории», где программное обеспечение сгруппировано по категориям.
Чтобы установить программное обеспечение, выберите приложение, которое вы хотите установить, и нажмите « Установить».
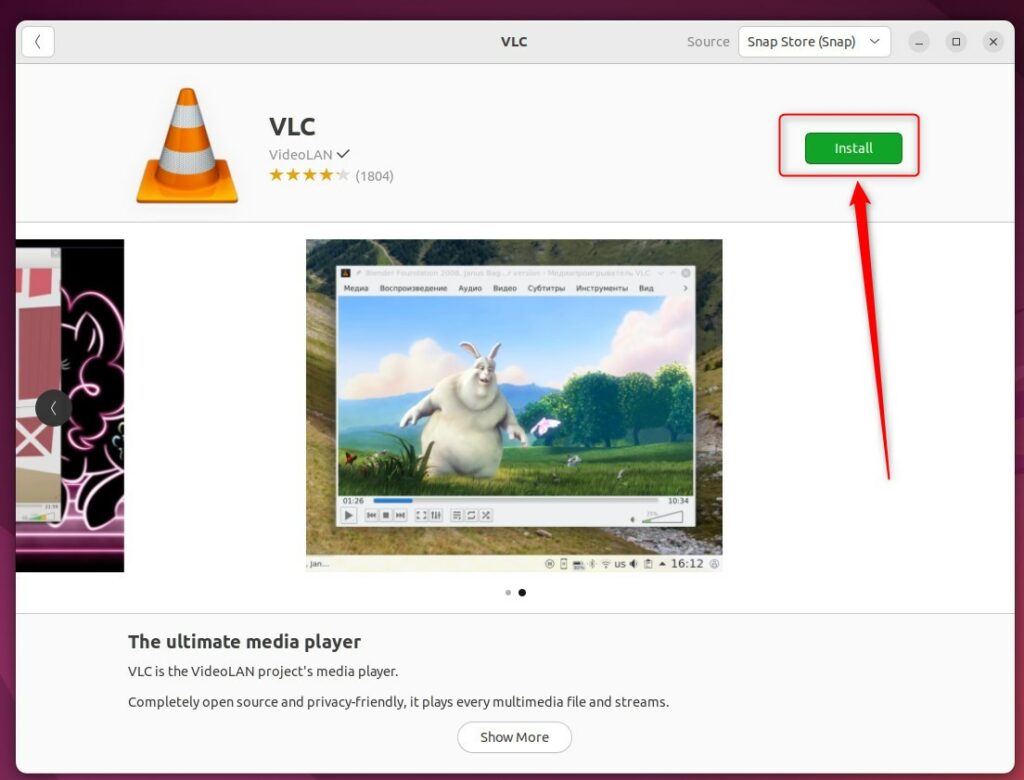
Вам будет предложено пройти аутентификацию, введя свой пароль. Как только вы это сделаете, начнется установка.
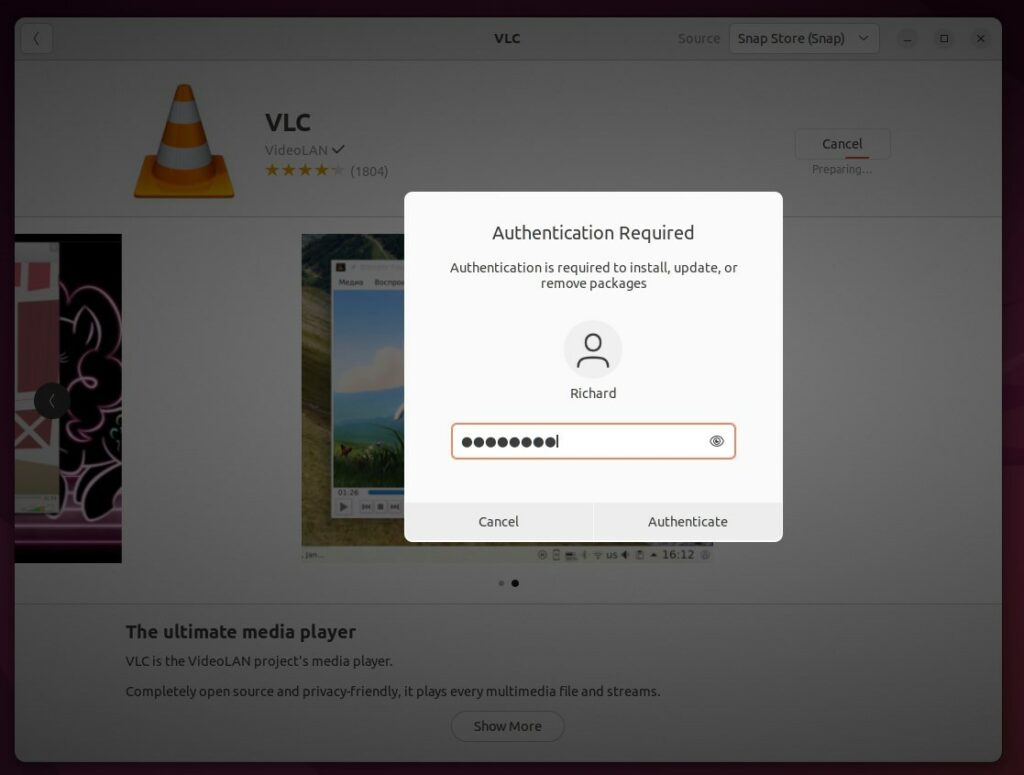
Установка обычно завершается быстро, но может занять некоторое время, если у вас медленное подключение к Интернету.
После этого программное обеспечение должно быть установлено и готово к использованию.
Сделайте это с другими приложениями, которые вы хотите установить.
Это должно сделать это!
Вывод:
В этом посте показано, как установить дополнительные пакеты программного обеспечения в Ubuntu Linux. Если вы нашли какую-либо ошибку выше или хотите что-то добавить, пожалуйста, используйте форму комментария ниже.