Публикуя статьи о резервном копировании я достаточно подробно описал как «готовить бэкапы» на серверах, но обошел стороной персональные компьютеры (далее ПК). А ведь данные на них не менее важны и так же нуждаются в резервировании. Тем более, что серверы есть не у всех, а ноутбук или компьютер у большинства — либо дома, либо на работе. Читать
Архив рубрики: Публикации
Выбираем провайдера спутникового телевидения
Спутниковое телевидение – это специфическая ТВ-система, где сигнал от источника к абоненту поступает, благодаря искусственным спутникам. Расположенные на орбите спутники обеспечивают довольно качественные сигналы, а зона покрытия охватывает практически всю страну. Подробно о технологии читайте здесь https://internetsim.ru/kak-sputnikovoe-televidenie-luchshe-vybor-dlya-doma-i-dachi/.
Для установки спутникового ТВ на даче, в частном или загородном доме понадобится комплект специального оборудования. Обычно в такие наборы входит спутниковая антенна, ресивер, конвертер и смарт-карта. Пользователи отмечают хорошее качество сигнала и высокое разрешение видео. Подключить такой комплект можно в любой точке страны. Для подключения, помимо покупки и установки оборудования, нужно выбрать провайдера.
Спутниковое ТВ: какое выбрать
В России работает много провайдеров, которые продвигают спутниковое телевидение. Но есть крупные компании, услугами которых пользуются миллионы граждан:
- Телекарта. У компании разработано множество предложений. Пользователи могут выбирать как минимальные, так и максимально полные пакеты. К преимуществам относят: высокое качество телетрансляций, каналы в HD-формате, качественная техподдержка абонентов. Минусы: дорогое оборудование и не совсем хорошее покрытие в некоторых регионах.
- Континент ТВ. Провайдер предлагает бесплатные каналы, а также предоставляет возможность не оплачивать телеканалы, которые не интересны пользователю. Это позволяет существенно уменьшать размер абонентской платы. Достоинства выбора: можно выбирать ресиверы, экономить на оплате услуг. Но в некоторых местах России покрытие Континент ТВ низкокачественное.
- Ростелеком. Существует компания достаточно давно, постоянно модернизирует услуги, разрабатывает новые предложения. Преимущество спутникового ТВ от РТК – простая установка и стоимость оборудования. Абоненты могут самостоятельно установить и настроить систему. Минусы: совсем небольшое покрытие, куда попадают лишь некоторые регионы России.
- Триколор. Один из крупнейших поставщиков спутникового телевидения. Стоимость комплектов устройств в среднем составляет около 5–7 тыс. р. тарифные планы также доступны. Можно подобрать вариант до 2 тысяч рублей в год. Оборудование Триколор разнообразное, можно подключать и отключать разные дополнительные услуги.
- НТВ Плюс. Еще один популярный спутниковый оператор, который разрабатывает массу тарифов и пакетов. Пользователи отмечают стабильный прием сигнала по всей РФ, простые настройки и множество телеканалов.
- МТС. Оператор сотовой связи вот уже несколько лет выступает в качестве поставщика спутникового ТВ. МТС транслирует некоторые каналы в HD и UHD, но только при подключении специального CAM-модуля.
Перед подключением желательно изучить предложения всех провайдеров.
2022-02-11T13:14:10
Сети
Популярные способы подключения интернета в Одинцовском районе
Для жителей Одинцовского района доступны разные технологии подключения интернета. Узнать о самом популярном способе можно здесь https://altclick.ru/moskovskaya-oblast/odintsovskiy/. Доступ к сети нужен каждому из нас. Интернет – это масса возможностей для развлечений, досуга, работы и учебы. Можно смотреть фильмы, слушать музыку, заниматься серфингом и выполнять ряд других задач. Провайдеры предлагают разные технологии организации доступа к сети.
Прежде чем искать провайдера и оставлять заявку на подключение, нужно подумать, для каких целей он вам нужен. От этого будет зависеть выбор технологии соединения, тарифного плана и скорости передачи данных. Самую высокую скорость предлагают провайдеры оптоволоконного интернета. В этом случае скоростной показатель может достигать 1 Гбит/с. Но далеко не каждый дом может быть подключен к такой сети.
Как подключить интернет в Одинцовском районе
Ниже рассмотрим популярные варианты организации доступа к сети:
- Телефон. Если в доме установлен стационарный телефонный аппарат, абонент может подключиться через эти линии. В районе обязательно должна быть АТС. Технология Dial Up уже ушла в прошлое, сейчас используют чаще ADSL. В доме придется установить модем и сплиттер для разделения сигналов. Преимущества: стабильность связи, невысокая абонентская плата. Но скорость передачи данных устроит не каждого.
- Wi-Fi от провайдера. Иногда в дачных поселках, коттеджных городках провайдеры устанавливают собственное мощное оборудование и раздают сеть сразу на несколько домов по улице. Многоканальный роутер обеспечивает все устройства стабильной сетью. В этом случае не понадобится дорогое абонентское оборудование. Но нужно учитывать, что скорость и трафик будут ограничены.
- WiMax. Абоненты могут пользоваться интернетом через радиодоступ. Пользователю понадобится только антенна для приема сигналов, специальный модем. Радиус действия WiMax гораздо больше по сравнению с Wi-Fi. Но размер абонентской платы, а также стоимость подключения подходят не каждому.
- Спутник. Спутниковая связь работает автономно от наземных коммуникаций. Потребуется покупка, установка, а также настройка антенны-тарелки, ресивера и некоторых других устройств. Настроить самостоятельно оборудование сможет не каждый, поэтому на объект придется приглашать мастера. Преимущества технологии: автономность, универсальность, стабильный сигнал. Минус – высокая стоимость комплекта устройств.
Некоторые интернет провайдеры в Одинцовском районе предлагают уже готовые решения. Это специальные комплекты оборудования для организации беспроводного высокоскоростного интернета. Абонент может пользоваться качественным соединением через сети операторов 3G и 4G.
2022-02-11T13:08:27
Сети
Резервирование роутеров Mikrotik с помощью VRRP
В статье, на примере роутеров Mikrotik, разберём сетевой протокол VRRP предназначенный для резервирования роутеров.
17 отличий между iPhone и Android-смартфонами
Что лучше: iPhone или Android-смартфоны? Споры никогда не заканчиваются, и большинство людей предпочитают быть поклонниками iOS или Android, несмотря ни на что. За последнее десятилетие у меня было несколько iPhone и как минимум десять Android-смартфонов, и я даже не считаю те, которые регулярно проверяю по работе. Хотя в этой статье я постараюсь не выбирать победителя и проигравшего, вот основные различия, которые я заметил между iPhone и Android-смартфонами:
Аппаратное обеспечение
Во-первых, давайте посмотрим на аппаратные различия. Хотя многие производители Android-устройств пытались копировать дизайн iPhone, верно и обратное, хотя и менее очевидным образом. В чем тогда отличия? Посмотрим…
1. Форматы и дизайн
Каждый год выпускаются буквально сотни Android-смартфонов. Например, в 2021 году их было более 500. айфоны? Четыре. Не четыреста, а четыре. Apple выпускает 3-5 моделей смартфонов каждый год, и все они имеют очень похожий дизайн.
Это приводит к абсолютно огромному количеству дизайнов, доступных каждый год для телефонов Android, от традиционных дизайнов до складных смартфонов и от телефонов, предназначенных для заядлых энтузиастов фотографии и видеосъемки, до телефонов, разработанных для того, чтобы выдерживать удары и погружение в воду. С другой стороны, пользователям iPhone приходится делать то, что Apple считает модным в этом году.

Кроме того, поскольку Apple не заинтересована в конкуренции на рынке начального уровня, если вы хотите совершенно новый смартфон, но не можете позволить себе 399 долларов США за iPhone SE (2020), ваши варианты ограничены только смартфонами Android. Не беспокойтесь, однако, только в 2021 году было выпущено более 350 моделей стоимостью менее 400 долларов США, так что есть из чего выбирать.
Что касается фактического дизайна устройства, Android-смартфоны начинают следовать той же схеме: качелька громкости, кнопка питания и все. Лишь некоторые смартфоны для энтузиастов, вроде Sony PRO-I, имеют дополнительные, вроде кнопки спуска затвора камеры. iPhone еще более строг: после удаления кнопки «Домой» каждый iPhone следовал одному и тому же рецепту: кнопка питания (или боковая кнопка), качелька регулировки громкости и довольно рудиментарный переключатель «Без звука».
Но в то время как кнопки iPhone редко меняют положение от одного поколения к другому, на телефонах Android больше разнообразия с точки зрения расположения и размера кнопок, тем более что некоторые из них используют кнопку питания в качестве считывателя отпечатков пальцев.

2. Энергоэффективность и необработанная мощность
Удивительно, но с таким количеством компаний, конкурирующих на рынке Android, именно Apple лидирует с точки зрения чистой вычислительной мощности. Новейший чипсет Apple A15 Bionic превосходит практически любой другой мобильный чипсет, будучи значительно более энергоэффективным. Вот сравнение результатов Geekbench между процессором A14 Bionic (выпущенным в 2020 году для серии iPhone 12) и процессором Qualcomm SM8350 Snapdragon 888 (на одном из самых быстрых и дорогих Android-смартфонов Sony PRO-I, выпущенном в конце 2021 года):
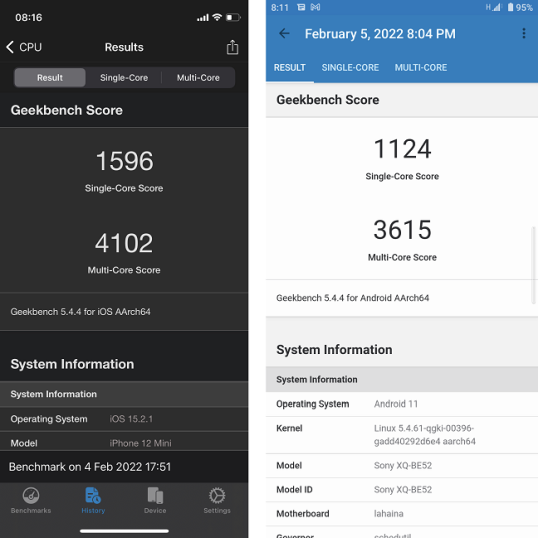
Это несколько компенсируется тем, что в айфонах аккумуляторы меньшей емкости. Это было особенно верно до серии iPhone 13. Например, у iPhone 12 батарея емкостью 2815 мАч по сравнению с 4000 мАч у Samsung Galaxy S21. Однако тенденция обратная. Хотя многие пользователи жаловались на время автономной работы iPhone, это уже не так с линейкой iPhone 13.
3. Особенности и инновации
В экосистеме Android инновации всегда были в центре внимания. Многие производители даже рискуют внедрять новые, непроверенные функции, чтобы выделиться на фоне конкурентов. Напротив, Apple медленно внедряла функции, внедряя их только тогда, когда была полностью уверена, что эта функция будет успешной. Возьмем экраны с высокой частотой обновления: хотя первые телефоны Android с дисплеями с частотой 120 Гц вышли в 2017 году, Apple реализовала эту функцию только четыре года спустя, на iPhone 13 Pro и Pro Max.

Хотя пользователи iPhone могут чувствовать себя обделенными, такая задержка также обеспечивает гораздо лучшую реализацию любой конкретной функции. Например, первая итерация складного дисплея Samsung была ужасной с точки зрения долговечности и продолжительности жизни, и только теперь, с третьим поколением Galaxy Z Fold, мы можем сказать, что нам комфортно с этой технологией. С iPhone вам не нужно бояться, что экспериментальные функции испортят ваш опыт.
4. Аутентификация
Если внедрение функций на смартфонах Apple происходит медленно, то по удалению функций они лидируют. Многие телефоны Android используют распознавание лиц, но большинство из них по-прежнему используют отпечатки пальцев в качестве метода аутентификации. iPhone, с другой стороны, убрали аутентификацию по отпечатку пальца еще в 2018 году! В основном это связано с тем, что их система распознавания лиц Face ID — лучшая из существующих. Он может распознать ваше лицо в темноте, он может уловить ваши черты даже под экстремальным углом, и делает это в мгновение ока.
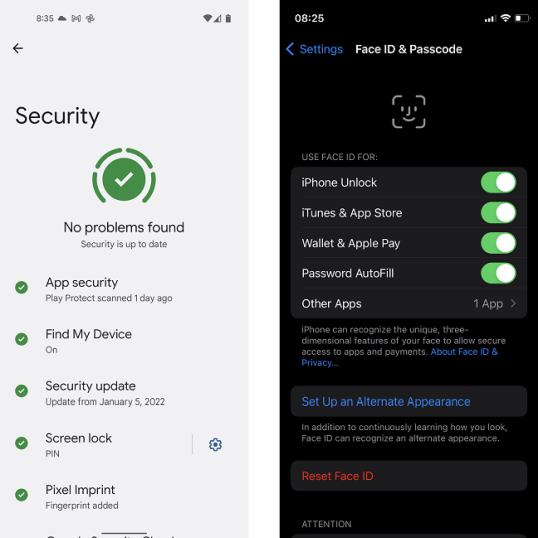
Еще более впечатляет то, что, несмотря на то, что маски для лица препятствуют аутентификации по лицу, Apple нашла решение, которое будет реализовано в iOS 15.4 на всех iPhone с поддержкой Face ID.
На Android-устройстве отсутствие сканера отпечатков пальцев поначалу может показаться странным, но как только вы попробуете и привыкнете к блестящей реализации распознавания лиц на iPhone, вам, скорее всего, уже никогда не захочется возвращаться к аутентификации по отпечаткам пальцев.
5. Связь
Android-смартфоны имеют широкий спектр возможностей подключения. Инфракрасный порт, Bluetooth, физические разъемы для наушников, USB-C — все это широко используется и совместимо с современными устройствами. Apple, с другой стороны, стремясь к инновациям, удаляя функции, удалила разъем для наушников из iPhone более пяти лет назад, начиная с iPhone 7. iPhone имеет самые современные возможности подключения, такие как Bluetooth, NFC, и Wi-Fi.

Что касается инфракрасных бластеров, то айфоны даже не удосужились их иметь. И причина такого отношения к подключению вполне логична, если прочитать следующую разницу между Android-смартфонами и iPhone:
6. Аксессуары
На устройствах Android большинство аксессуаров и носимых устройств взаимозаменяемы. Вы можете использовать умные часы Samsung со смартфонами Huawei, наушники Sony с устройствами Xiaomi и так далее. Да, некоторые из них могут иметь немного меньшую функциональность. Но в целом вы не вынуждены входить в экосистему, как на iPhone. Да, вы можете использовать AirPods, например, на смартфонах Android, но взамен вы потеряете многие функции. Но у вас есть пара качественных проводных наушников, которые вы хотите использовать на современном iPhone? Это будет 9 долларов США, спасибо. И в этом загвоздка. Аксессуары, предназначенные для iPhone, обычно намного дороже, чем их аналоги для Android.

Вы хотите купить сторонний зарядный кабель после того, как ваша кошка перегрызла тот, что шел в комплекте с устройством? Для телефонов Android вы можете найти кабель USB-C буквально везде за несколько долларов, и большинство из них будут совместимы с вашим устройством. На iPhone проприетарный порт Lightning принимает только небольшой набор сторонних кабелей. Если вы покупаете несертифицированный кабель, вы получите сообщение об ошибке «Этот кабель или аксессуар не сертифицирован». Стоимость оригинального кабеля Apple? 19 долларов, большое спасибо.
7. Долговечность, обслуживание и ремонт
Одна из самых больших проблем, которые у меня есть с Apple, — это ее отношение к обслуживанию и ремонту. И я не говорю о абсурдных ценах на ремонт, хотя это тоже вопрос. До недавнего времени ремонт современного iPhone за пределами сертифицированных официальных сервисных центров был кошмаром, в основном из-за искусственных препятствий, которые Apple ввела, чтобы помешать вам ремонтировать ваш iPhone. Такие вещи, как использование фирменных винтов, сопряжение экрана с другими частями смартфона, чтобы его нельзя было просто заменить и т. д., — это совершенно искусственные препятствия, не связанные ни с какими техническими ограничениями. Из-за негативной реакции общественности отношение Apple к самостоятельному ремонту в последнее время улучшилось: детали стали доступны для отдельных потребителей, начиная с iPhone 12 и далее.

Сломанный айфон? В большинстве случаев затраты на ремонт не оправдывают себя.
При этом срок службы iPhone больше, чем у аналогичных Android-смартфонов, благодаря более высокому качеству материалов, лучшей инженерии и лучшей поддержке программного обеспечения. Срок службы батареи быстро снижается после 2-3 лет интенсивного использования, независимо от того, какой смартфон вы покупаете.
8. Физическое хранилище
Все больше и больше смартфонов отходят от этого, но до недавнего времени большинство Android-устройств имели расширяемую физическую память. Айфоны, с другой стороны, поставляются с фиксированным хранилищем, и если вы, как я, храните фотографии или вам нравится записывать видео, вы можете столкнуться с проблемами места для хранения в будущем.
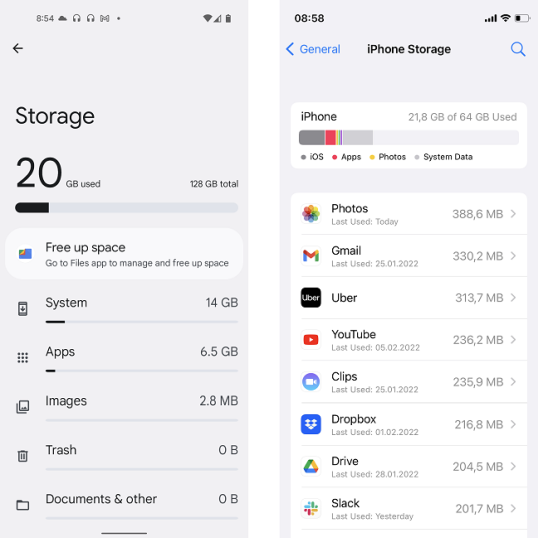
Конечно, вы можете периодически загружать свои медиафайлы на компьютер, но, как вы увидите в следующем разделе (Программное обеспечение), даже это не так просто на iPhone.
Программное обеспечение
Хотя вы можете возразить, что экран на iPhone изготовлен на том же заводе, что и экран для Samsung Galaxy, или что заводы по производству чипов для iPhone и Android-устройств расположены в одном городе или даже принадлежат одному и тому же владельцу, программное обеспечение совершенно разные на смартфонах Android по сравнению с iPhone. Давайте рассмотрим несколько основных различий между iOS и Android:
9. «Открытый исходный код» против закрытой операционной системы
В 2003 году компания Android Inc. начала разработку операционной системы для цифровых камер. Впоследствии компания была куплена Google, и с тех пор она вошла в историю. Android основан на Linux и, таким образом, является операционной системой с полностью открытым исходным кодом. iOS, с другой стороны, разрабатывается самой Apple и имеет только части кода с открытым исходным кодом. Существует множество статей о преимуществах и недостатках открытого исходного кода, но главный вывод заключается в том, что программное обеспечение с открытым исходным кодом является более прозрачным, более легкодоступным и гораздо более надежным с точки зрения безопасности (уязвимости обнаруживаются и устраняются быстрее, чем в закрытом). -исходные системы). Но он также менее регламентирован, что оказывает большое влияние на пользовательский опыт.
10. Обновления
При строгом рассмотрении обновлений безопасности Android, похоже, имеет явное преимущество перед iOS, поскольку новые обновления безопасности выпускаются для смартфонов Android каждый месяц. Однако, если учесть задержку с распространением (каждый производитель решает, когда выпустить обновление, обычно после завершения внутреннего тестирования) и ограниченный период поддержки некоторых устройств, мы можем сказать, что большинство устройств Android (кроме смартфонов Pixel, которые всегда получают обновления, как только они выпускаются) на самом деле работают с относительно устаревшим программным обеспечением. Это верно и для обновлений операционной системы или новых версий. Хотя Android 12 был выпущен в октябре 2021 года, огромное количество других совместимых смартфонов еще не получили новую версию на момент написания этой статьи, в феврале 2022 года.
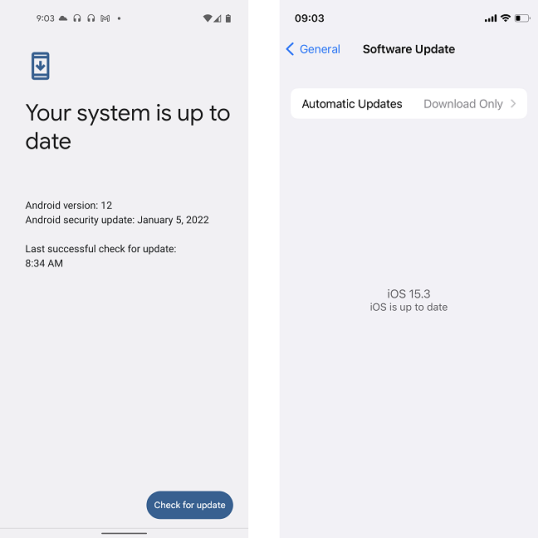
Для iPhone процесс проще и в то же время строже: обновления безопасности выпускаются гораздо реже и отправляются на все поддерживаемые iPhone одновременно. Что касается обновлений операционной системы, то они одновременно доступны и для всех поддерживаемых iPhone. Кроме того, устройства Apple имеют отличную поддержку программного обеспечения: iPhone SE, выпущенный в 2016 году, можно без проблем обновить до последней версии iOS 15.3. Флагманские Android-устройства того же года уже устарели в 2018 году.
11. Интерфейс
Интерфейс устройств Android сильно различается от одного производителя к другому. Это означает, с одной стороны, что вы обязательно найдете скин операционной системы, которым вам понравится пользоваться, но, с другой стороны, затрудняет переход с Android-смартфона на смартфон другого производителя.
Тем не менее, нет предела совершенству, когда дело доходит до настройки внешнего вида интерфейса Android. Вы можете сделать интерфейс своего телефона похожим на трикодер из «Звездного пути» или персонализировать телефон Android вашей второй половинки с помощью темы «День святого Валентина».
Интерфейс идентичен для всех iPhone с одинаковой версией iOS. Переход с iPhone 2016 года на iPhone 2022 года почти не вызывает затруднений, но у этого также есть недостаток, поскольку возможности настройки для iPhone гораздо более ограничены. И мы говорим не только о внешнем виде: несмотря на то, что на дворе 2022 год, на устройствах Apple до сих пор нет подходящего ящика приложений, поэтому приложения выгружаются на главный экран (экраны).
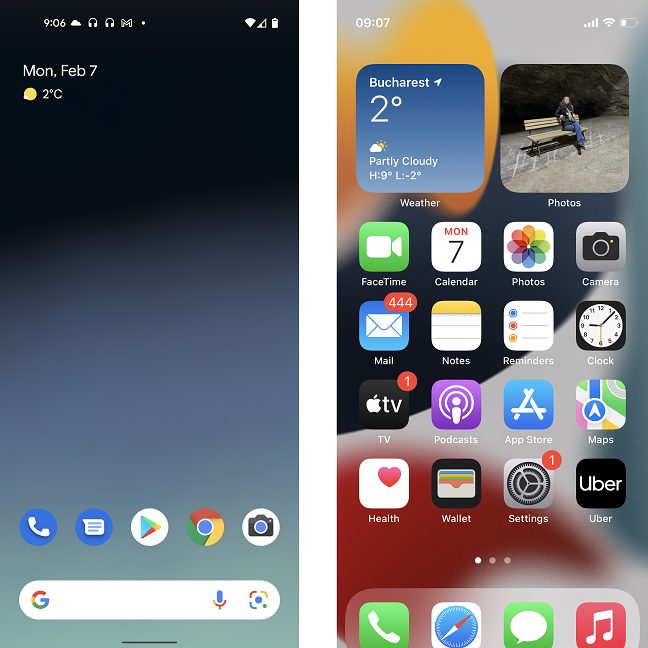
Конечно, есть библиотека приложений, но она по-прежнему неуклюжа и труднодоступна по сравнению с простым ящиком приложений, присутствующим почти на всех смартфонах Android.
12. Магазины
Google Play — официальный магазин приложений для Android-смартфонов. В нем примерно 3,5 миллиона приложений по сравнению с 2,3 миллионами в Apple App Store. Тем не менее, Apple лучше справляется с монетизацией своих приложений: глобальные потребительские расходы в третьем квартале 2020 года составили около 19 миллиардов долларов США. Расходы Google Play за тот же период времени составили «всего» 10,3 миллиарда долларов США. Однако цифры не рисуют всей картины.
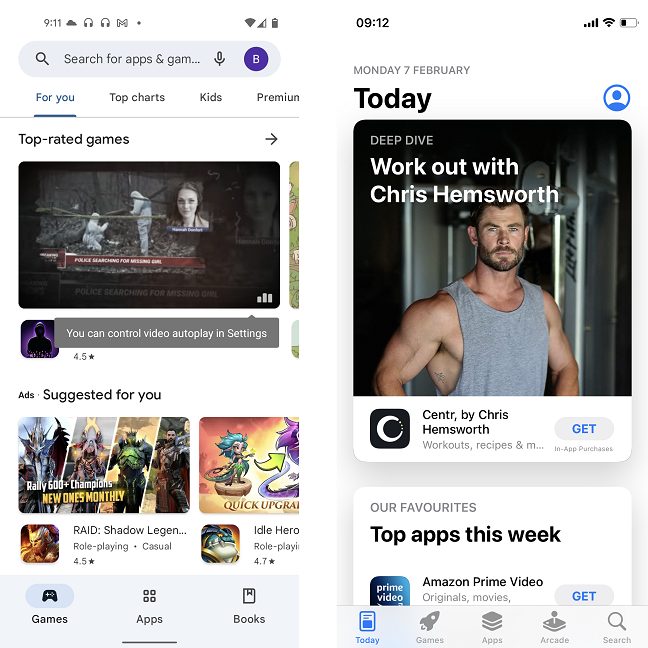
Разнообразие приложений в Play Store невероятно, и благодаря более гибкой природе Android приложения в Google Play могут делать то, к чему у пользователей iPhone нет доступа. Подавляющее большинство приложений в Google Play Store бесплатны, но в большинстве из них также есть реклама (некоторые из них очень навязчивы). Несмотря на более ограниченные возможности приложений, вредоносные приложения почти никогда не обходят строгую фильтрацию, установленную Apple, поэтому в целом вы в большей безопасности и получаете лучший опыт в App Store.
Наконец, загрузка приложений на iPhone практически невозможна, в то время как на Android все, что вам нужно сделать, чтобы установить приложение, которого нет в Google Play, — это переключить переключатель и подтвердить установку.
13. Приложения
Отчасти благодаря более строгому регулированию и более высоким затратам на разработку сторонние приложения для iPhone просто лучше, чем их аналоги для Android. По-другому и не скажешь: сторонние приложения для iOS меньше вылетают, имеют больший функционал и (из-за другого подхода к монетизации) меньше рекламы. Это также побуждает разработчиков сначала запускать свои приложения и обновления на устройствах iOS.
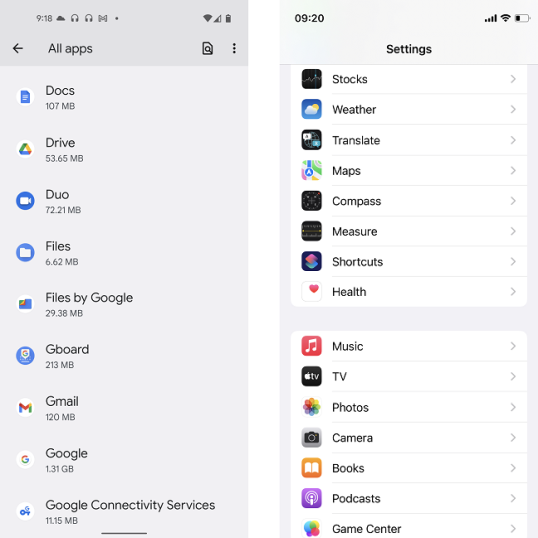
Количество и качество приложений по умолчанию, предустановленных на смартфонах Android, сильно различаются: от минимально необходимого до огромного количества вредоносных программ. Приложения, которые поставляются с каждым iPhone, хотя, возможно, менее совершенны, чем их аналоги Google (Chrome против Safari, Google Maps против Apple Maps), по-прежнему превосходны и идеально интегрированы с операционной системой.
14. Конфиденциальность
Вот вопрос для вас: Google зарабатывает на показе целевой рекламы, основанной на местоположении каждого пользователя, просмотре, покупках и предпочтениях просмотра. Apple зарабатывает деньги на продаже iPhone и предоставлении услуг своим пользователям. Какой из двух компаний вы бы больше доверяли в отношении конфиденциальности?
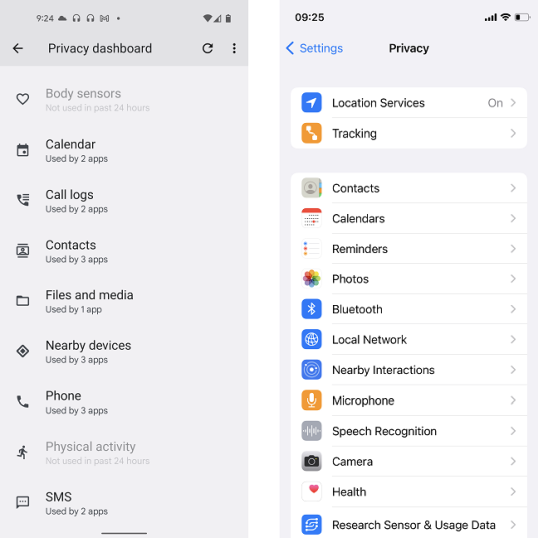
Хотя ответ может показаться очевидным, в большинстве случаев вы можете получить одинаковый уровень конфиденциальности в обеих операционных системах. Разница в том, что вам придется больше копаться в меню на Android-устройствах. В целом Apple собирает меньше данных о пользователях, а сторонние приложения, представленные в App Store, имеют более строгие правила в отношении конфиденциальности.
15. Резервное копирование и передача файлов
И iPhone, и Android-смартфоны по умолчанию имеют надежные облачные решения для резервного копирования. Но в то время как Google предлагает 15 ГБ хранилища бесплатно (чрезвычайно полезно, если вы создаете резервные копии своих медиафайлов), Apple предлагает только 5 ГБ в своем iCloud. Пространство заполняется довольно быстро, что, в свою очередь, отключает резервное копирование приложений и настроек.
Перенос файлов на компьютер с большинством Android-смартфонов тривиален: после подключения с помощью USB-кабеля вы можете смонтировать хранилище смартфона как диск, а затем перетаскивать или копировать и вставлять файлы в любое место. Вы также можете установить накопитель в качестве медиаплеера, что позволит вам легко загружать и скачивать медиафайлы.
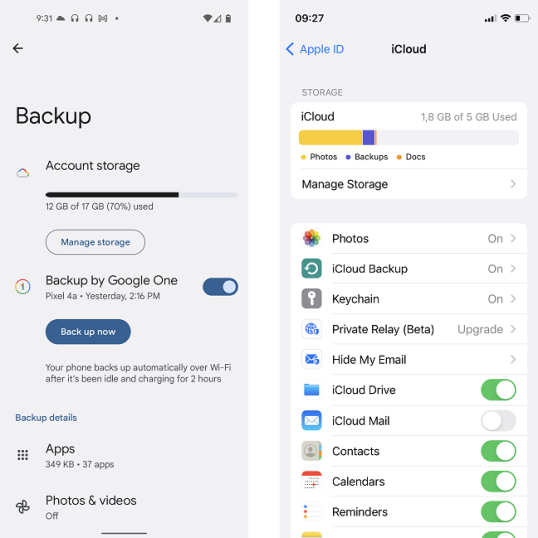
На iPhone передача файлов так же проста… если ваш компьютер Mac. В Windows нужно установить iTunes, да и то доступ к содержимому хранилища iPhone в лучшем случае ограничен. Поскольку у iPhone нет расширяемой памяти, вы не можете просто извлечь SD-карту и вставить ее в устройство чтения карт, как это делается на многих телефонах Android.
Позиция на рынке
Это не только оборудование или программное обеспечение. Я заметил еще два отличия, которые я бы отнес к категории более общих, являющихся следствием всех других аспектов, представленных выше.
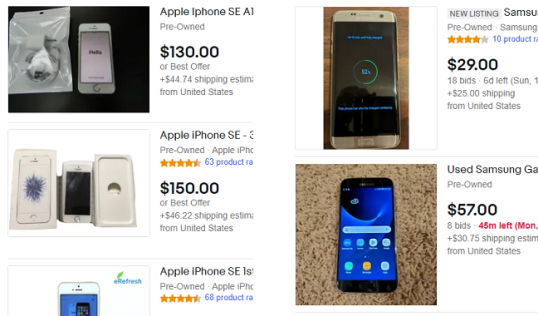
16. Стоимость перепродажи
Из-за своей повсеместной распространенности смартфоны Android, как правило, дешевеют быстрее, чем их аналоги iPhone. Это также связано с надежностью устройств и поддержкой программного обеспечения. Например, в то время как подержанный iPhone SE 2016 года можно купить за 100-200 долларов США, флагманский Android-смартфон того же года Samsung Galaxy S7 сейчас будет стоить вам половину этой суммы. Это делает iPhone лучшим вложением, если учесть, что его стоимость со временем обесценивается.
17. Целевая группа
iPhone ориентирован на менее технических пользователей. Это становится очевидным, когда вы смотрите на уровень настройки и интерфейс iPhone. Смартфоны Apple предназначены для работы с максимальной эффективностью «из коробки» с минимальной конфигурацией. Программное обеспечение просто работает, камера делает потрясающие снимки без необходимости возиться с настройками, приложения просто делают именно то, для чего они предназначены. Интерфейс iOS идеально подходит для людей, которые не хотят много менять, но хотят иметь надежные и эффективные функции на своих телефонах.

Android-смартфоны ощущаются не столько как гаджеты, сколько как технологии — больше вариантов конфигурации, больше контроля со стороны пользователя, больший выбор. Это здорово, если вы хотите настроить свое устройство, если хотите повысить эффективность, качество и скорость и точно знаете, что и где искать. Однако, если вам нужен смартфон флагманского уровня, который просто делает все очень хорошо, вы не ошибетесь с iPhone.
Вы перешли со смартфона Android на iPhone или наоборот? Каким был ваш опыт?
Если вы перешли с Android на iOS или наоборот, что вам понравилось, а что разочаровало? Довольны ли вы переходом или с удовольствием вернулись бы? Не стесняйтесь поделиться своим мнением в разделе комментариев ниже и рассказать нам о своем опыте.
2022-02-10T23:16:11
Вопросы читателей
Что делать, если я столкнулся с ошибкой IRQL_NOT_LESS_OR_EQUAL?
Каждый хотя бы раз сталкивался с ошибкой BSOD (синий экран смерти). К сожалению, IRQL_NOT_LESS_OR_EQUAL — одна из них. Обычно одним из главных виновников этого стоп-кода являются неисправные драйверы.К счастью, есть несколько решений для решения этой проблемы. Однако причиной этой ошибки также может быть несовместимое или неисправное оборудование. При этом, если проблема связана с программным обеспечением, вы сможете решить ее довольно легко.
Теперь, прежде чем приступить к устранению проблемы, давайте разберемся, что именно представляет собой эта ошибка и все вероятные причины, которые могут вызвать эту проблему.
Что такое ошибка IRQL_NOT_LESS_OR_EQUAL и каковы ее основные причины?
Ошибка IRQL_NOT_LESS_OR_EQUAL в основном связана с памятью. Часть IRQL означает «строка запроса на прерывание», которую Windows использует для сигнализации о событиях, требующих срочного внимания. IRQL обычно возникает, когда драйвер устройства запрашивает доступ к адресу памяти, для которого у него нет необходимых разрешений или прав доступа.
Поскольку выделение памяти для процессов обычно имеет установленную границу, часть «NOT_LESS_OR_EQUAL» в ошибке означает, что драйвер попытался получить доступ к адресу, который находится за пределами или превышает граничное значение.
Для вашего лучшего понимания ниже приведен список наиболее вероятных причин этой ошибки. Вы также можете использовать список в качестве ориентира и искать любые недавние изменения в том же духе:
- Поврежденные системные файлы.
- Несовместимые, неисправные или устаревшие драйверы.
- Неисправное или несовместимое оборудование. Если вы недавно меняли модули оперативной памяти, рассмотрите возможность перехода на старые и посмотрите, сохраняется ли проблема.
- Иногда причиной проблемы может быть даже поврежденная или неполная установка программного обеспечения.
Теперь, когда вы немного познакомились с проблемой, с которой столкнулись на своем ПК, давайте начнем с того, как ее исправить, чтобы вернуть компьютер в нормальное состояние.
Способ 1: запустить диагностику памяти
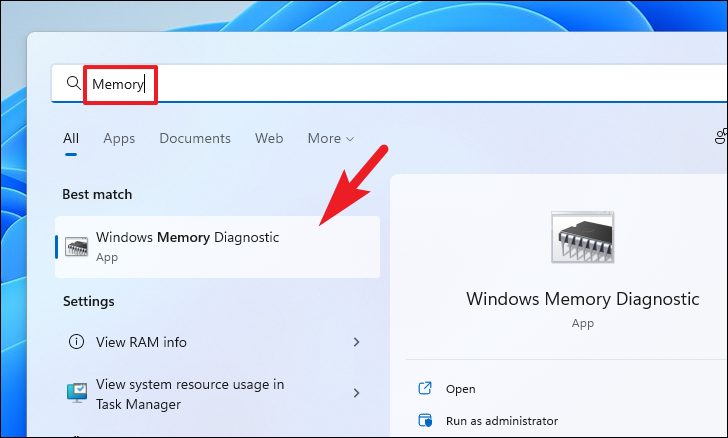
Поскольку ошибка обычно возникает при наличии проблемы с системной памятью, имеет смысл запустить диагностику встроенной памяти, чтобы исключить возможные причины.
Сначала перейдите в меню «Пуск» и введите «Диагностика памяти», чтобы выполнить поиск. Затем в результатах поиска щелкните плитку «Диагностика памяти Windows», чтобы запустить приложение на своем компьютере.
Затем нажмите «Перезагрузить сейчас и проверьте наличие проблем», чтобы перезагрузить компьютер и запустить диагностику.
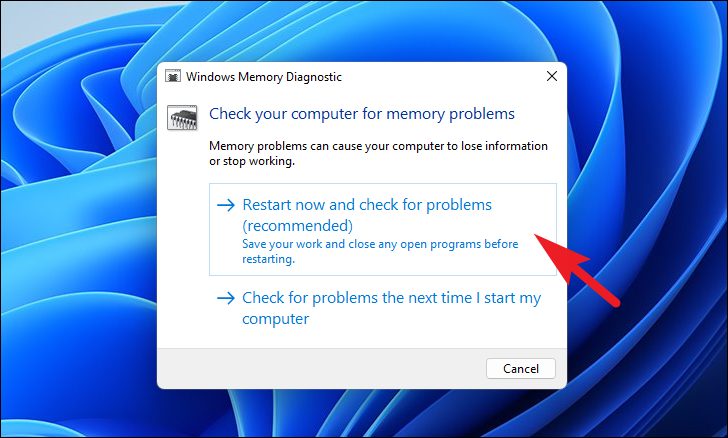
Ваш компьютер не будет перезагружаться и выполнять необходимые проверки вашей памяти, после завершения вы получите исчерпывающий отчет после перезагрузки, если обнаружится какая-либо проблема.
Способ 2: исправить ошибку с помощью DISM и сканирования SFC
Возможно, проблема связана с основными системными файлами вашего ПК. Это означает, что некоторые из системных файлов могли быть повреждены или повреждены, что вызывает проблему.
Этот метод представляет собой двухэтапный процесс. Во-первых, вам нужно будет запустить инструмент DISM (Deployment Image and Servicing Management), чтобы исправить любые проблемы с вашим системным образом, который используется для восстановления вашей системы. затем вам нужно будет вызвать команду SFC (Проверка системных файлов), чтобы исправить любые проблемы, присутствующие в ваших установленных файлах Windows.
Поскольку DISM — это команда уровня администратора, вам нужно будет запустить инструмент командной строки от имени администратора.
Для этого щелкните правой кнопкой мыши меню «Пуск» на панели задач. Затем выберите параметр «Терминал Windows (администратор)». Если вы используете более старую систему Windows, нажмите, чтобы выбрать параметр «Командная строка (администратор)» в меню наложения.
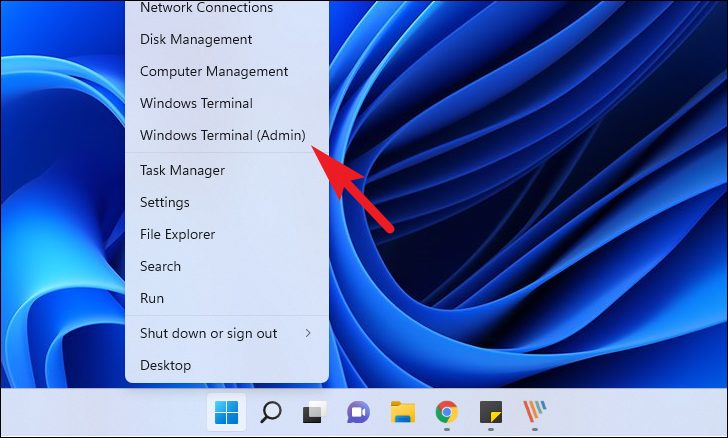
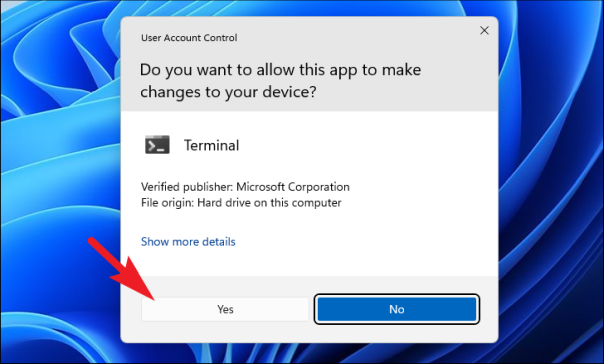
Независимо от выбранного варианта, вы увидите экран UAC (Контроль учетных записей пользователей), предлагающий ввести учетные данные учетной записи администратора. Если вы уже вошли в систему как администратор, просто нажмите кнопку «Да», чтобы запустить инструмент командной строки.
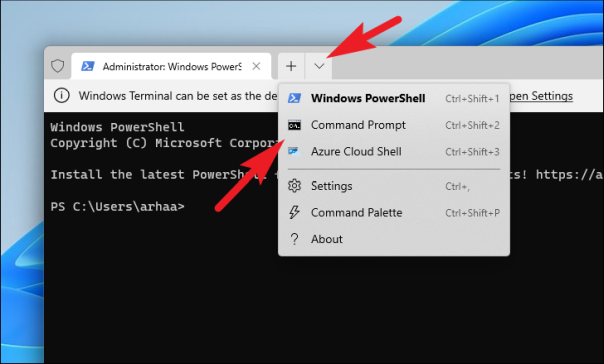
Теперь, если вы выбрали опцию «Терминал Windows», щелкните значок шеврона (стрелка вниз) на панели вкладок. Затем нажмите, чтобы выбрать опцию «Командная строка». Кроме того, вы можете нажать Ctrl+ Shift+ 2 , чтобы открыть вкладку командной строки.
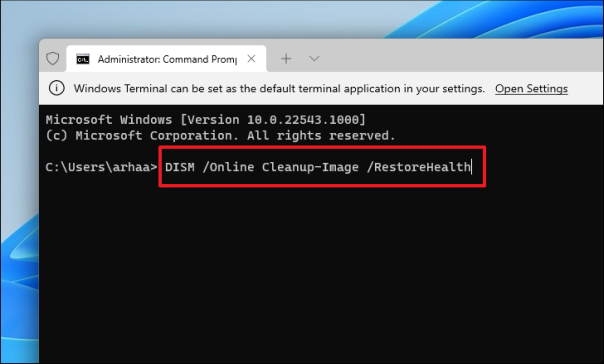
Затем введите или скопируйте+вставьте следующую команду и нажмите Enter, чтобы восстановить образ системы.
DISM /Online Cleanup-Image /RestoreHealth
Примечание. Для восстановления образа системы необходимо подключение к Интернету. Команда также может загружать некоторые файлы в фоновом режиме.
Инструмент DISM может занять несколько минут, чтобы завершить процесс, в зависимости от вашей системы и скорости интернет-соединения. Это нормально, что командная строка иногда зависает во время процесса.
После завершения процесса DISM пришло время запустить сканирование SFC, чтобы исправить проблемы, с которыми вы сталкиваетесь в настоящее время.
Чтобы запустить команду SFC на вашем компьютере, введите или скопируйте и вставьте следующую команду и нажмите Enter.
SFC /scannow
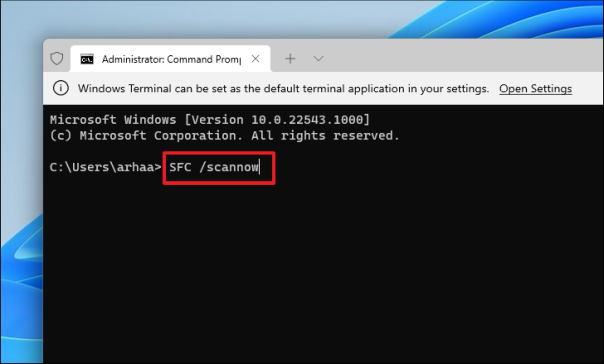
Сканирование SFC может занять несколько минут. Перезагрузите компьютер после сканирования, чтобы проверить, сохраняется ли проблема.
Способ 3: обновить или откатить драйверы
Если вы недавно обновили свои драйверы или не обновляли их какое-то время, это определенно может быть одной из причин, которая может вызвать проблему на вашем ПК.
Если вы недавно обновили драйвер, просто откатите его до предыдущей версии, и ваша проблема должна быть устранена, в противном случае, если ваши драйверы устарели, вам придется вручную убедиться, что каждый драйвер обновлен.
Для этого откройте меню «Пуск» и введите «Диспетчер устройств», чтобы найти его. Затем в результатах поиска щелкните плитку «Диспетчер устройств», чтобы открыть ее.
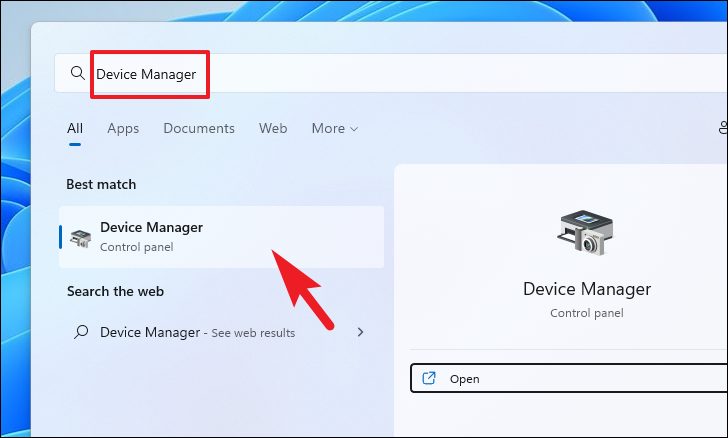
Если вы здесь, чтобы откатить драйвер, найдите категорию компонентов, для которой вы недавно обновили драйвер, и дважды щелкните ее, чтобы развернуть раздел. Затем дважды щелкните компонент, чтобы открыть его свойства. Это откроет отдельное окно на вашем экране.
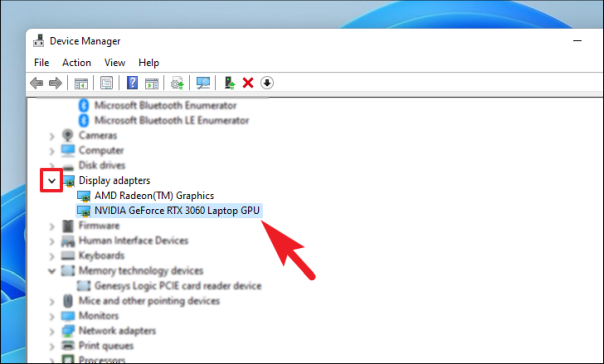
После этого в окне свойств перейдите на вкладку «Драйвер». Затем нажмите кнопку «Откатить драйвер», чтобы откатить последнее обновление. Если кнопка неактивна, драйвер не обновлялся недавно и его нельзя откатить.
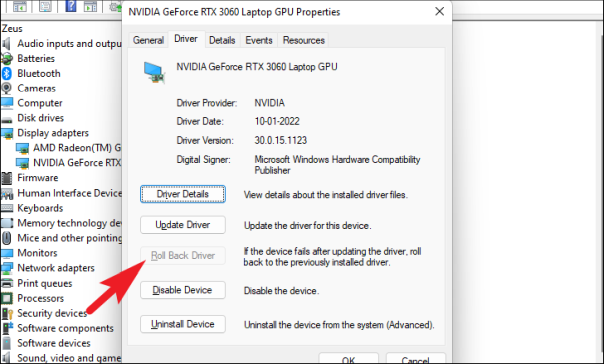
Если вы хотите обновить драйвер, в окне свойств компонента нажмите кнопку «Обновить драйвер». Это откроет отдельное окно на вашем экране.
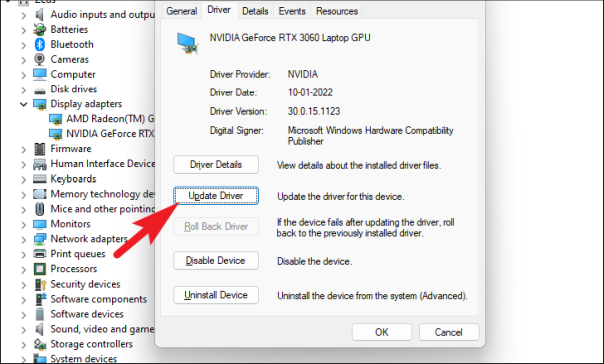
После этого в окне «Обновить драйверы» нажмите «Автоматический поиск драйверов», чтобы позволить Windows автоматически искать драйверы на своих серверах. В противном случае, если на вашем компьютере уже установлена последняя версия драйвера, щелкните параметр «Выполнить поиск драйвера на моем компьютере», чтобы просмотреть файл с помощью Проводника.
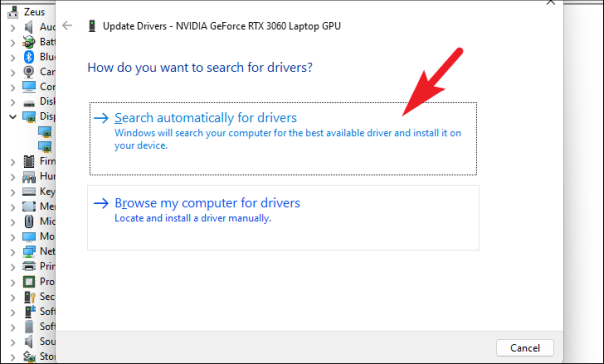
Теперь, если у вас есть более одного устаревшего драйвера или, проще говоря, если у вас есть много компонентов, для которых вы не обновляли драйверы в последнее время, вам придется повторить процесс по отдельности, чтобы исключить возможность столкнуться с этой ошибкой из-за устаревшего драйверы на вашем ПК.
Способ 4: перезагрузите компьютер
Сброс настроек компьютера — один из самых надежных способов решения проблем на вашем компьютере. Вы также можете сохранить или удалить личные файлы в зависимости от ваших предпочтений.
Для этого запустите приложение «Настройки» из меню «Пуск». Кроме того, вы также можете нажать сочетание клавиш Windows+ I на клавиатуре, чтобы запустить приложение.
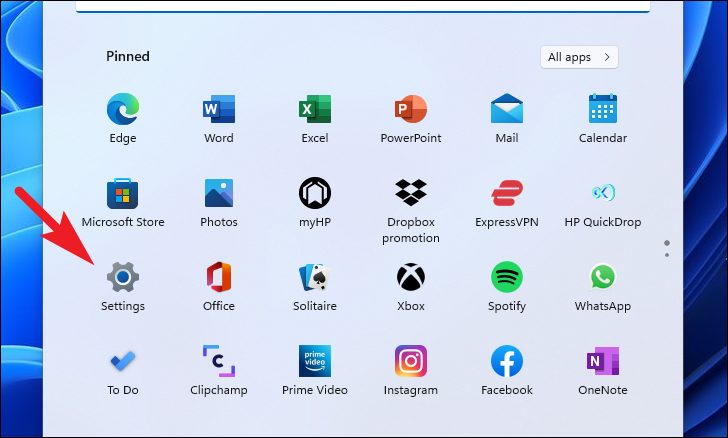
Затем нажмите на вкладку «Система» на левой боковой панели окна «Настройки».
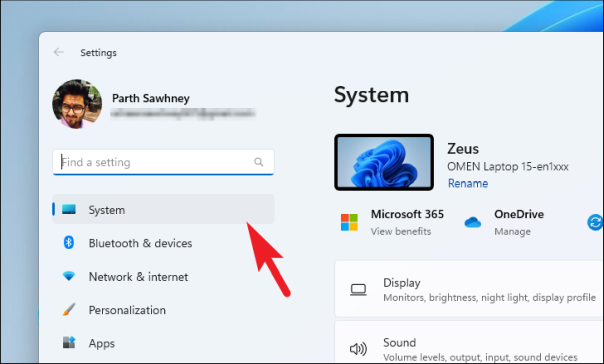
Теперь в правой части окна прокрутите, чтобы найти и выбрать параметр «Восстановление» из списка.
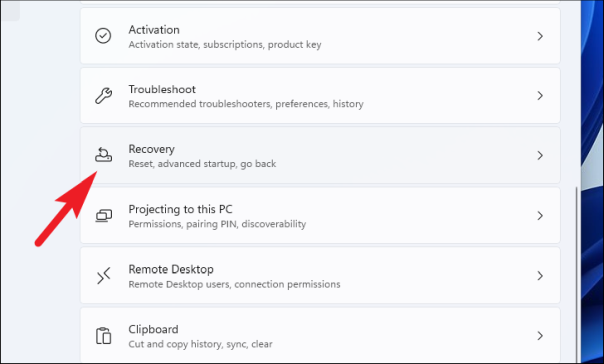
Нажмите «Сбросить ПК»; кнопку в разделе «Параметры восстановления». На вашем экране откроется отдельное окно «Сбросить этот компьютер».
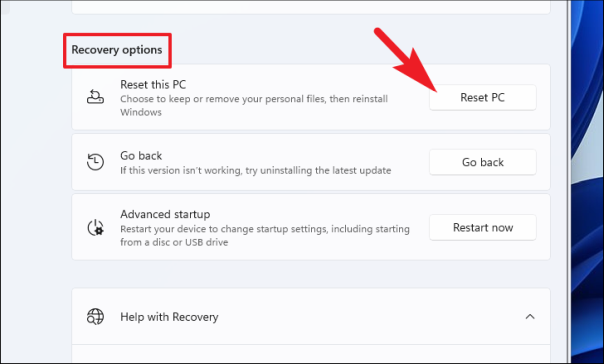
В отдельном появившемся окне «Сбросить этот компьютер» у вас будет два варианта, каждый из которых удалит все системные приложения и вернет системные настройки к новому состоянию. Однако параметр «Сохранить мои файлы» сохранит ваши личные файлы нетронутыми, а параметр «Удалить все» полностью очистит список.
Нажмите, чтобы выбрать предпочтительный вариант на экране «Сбросить этот компьютер».
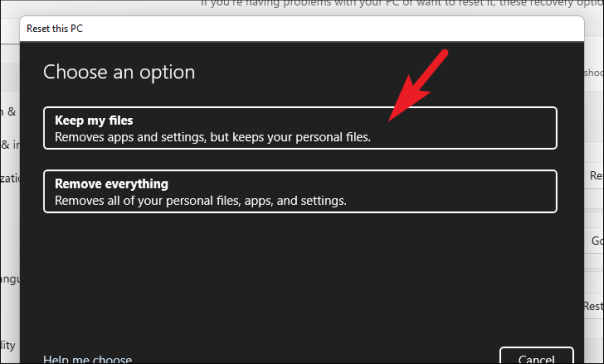
После этого вам нужно будет выбрать между «облачной загрузкой» и «локальной переустановкой». Облачная загрузка считается сравнительно более надежной и стойкой, чем «локальная переустановка», поскольку может быть вероятность повреждения или повреждения локальных файлов. Однако для опции «Облачная загрузка» потребуется активное подключение к Интернету.
Теперь выберите вариант по вашему выбору, чтобы переустановить Windows на вашем компьютере.
Примечание. Ни один из вариантов переустановки не требует подключения каких-либо внешних установочных носителей.
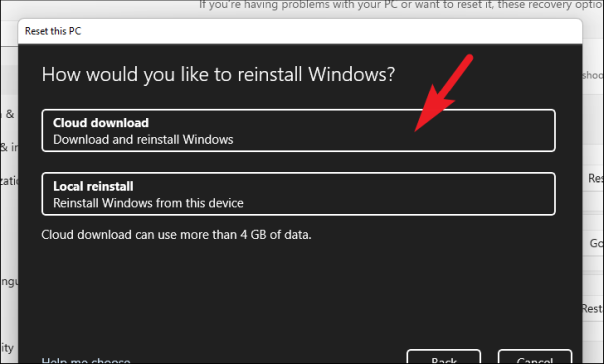
Далее вы увидите текущие настройки сброса вашего ПК. Если вы хотите изменить эти настройки, нажмите «Изменить настройки».
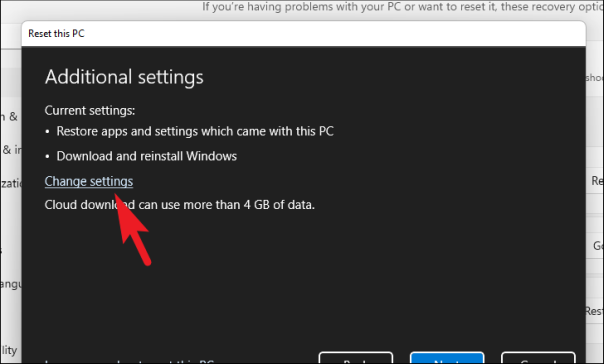
В окне «Выберите настройки» у вас есть три параметра, которые изменят настройки:
- Восстановить предустановленные приложения?: Как следует из названия, эта опция позволяет вам выбрать, хотите ли вы переустановить все приложения, которые были предустановлены на вашем ПК с Windows. Это также вернет системные настройки к заводским значениям по умолчанию и вернет вашу машину в новое состояние.
- Загрузить Windows?: Эта опция позволяет переключиться с «Облачной загрузки» на «Локальный сброс». На случай, если вы почувствуете необходимость изменить метод переустановки до ее начала.
После того, как вы установили дополнительные настройки в соответствии с вашими предпочтениями, нажмите кнопку «Подтвердить», чтобы продолжить.
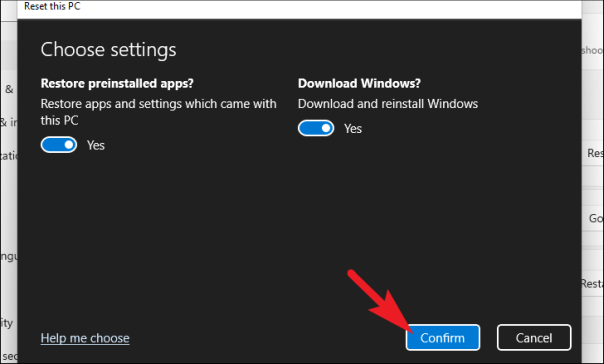
Нажмите кнопку «Далее» в нижней части окна.
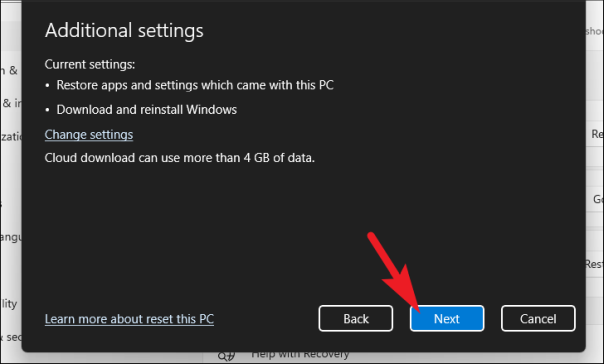
Windows может занять некоторое время, чтобы загрузить следующий экран. Посидите спокойно, пока процесс работает в фоновом режиме.
Затем Windows перечислит все последствия перезагрузки вашего ПК. Прочтите и нажмите кнопку «Сброс», чтобы начать процесс сброса.
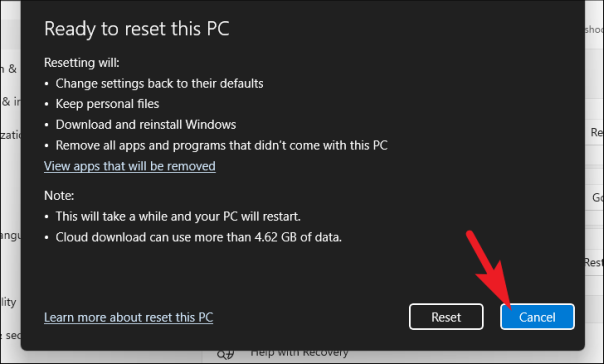 Ваша машина может перезагружаться несколько раз, что совершенно нормально при сбросе настроек. Сброс может занять несколько часов в зависимости от вашего компьютера и выбранных настроек.
Ваша машина может перезагружаться несколько раз, что совершенно нормально при сбросе настроек. Сброс может занять несколько часов в зависимости от вашего компьютера и выбранных настроек.
Вот и все, надеюсь, эти простые инструкции помогут вам избавиться от ошибки и вернуть компьютер в нормальное состояние.
2022-02-10T10:45:25
Вопросы читателей