Проверка орфографии в Word — это встроенная функция, помогающая обнаруживать орфографические и грамматические ошибки при наборе текста. Если инструмент обнаружит какие-либо ошибки или ошибки в вашем документе, он подчеркнет ошибки разными цветами, например, красным для орфографических ошибок, зеленым для грамматических ошибок и синим для контекстных орфографических ошибок.
Однако иногда функция проверки орфографии не работает в Word должным образом. Многие пользователи жаловались на то, что инструмент неправильно помечает орфографические ошибки и пропущенные слова или что программа полностью перестала работать.
Если вы столкнулись с какой-либо проблемой с инструментом проверки орфографии и грамматики Word, есть несколько способов исправить это, и мы рассмотрим каждый из них в этом посте.
Проверьте параметры языка и проверки орфографии
Если проверка орфографии и автокоррекция не работают для определенного документа, проблема может быть вызвана языковыми настройками. Поэтому следите за параметрами языковых настроек. Когда вы вводите документ, Microsoft Word автоматически определяет используемый вами язык и пытается его автоматически исправить. Эта функция может быть полезна во многих случаях, однако иногда она может быть причиной того, что проверка орфографии не работает должным образом. Вот как вы можете решить эту проблему:
Сначала откройте документ Word, в котором не работает проверка орфографии. Затем нажмите Ctrl+, Aчтобы выделить весь текст в документе.

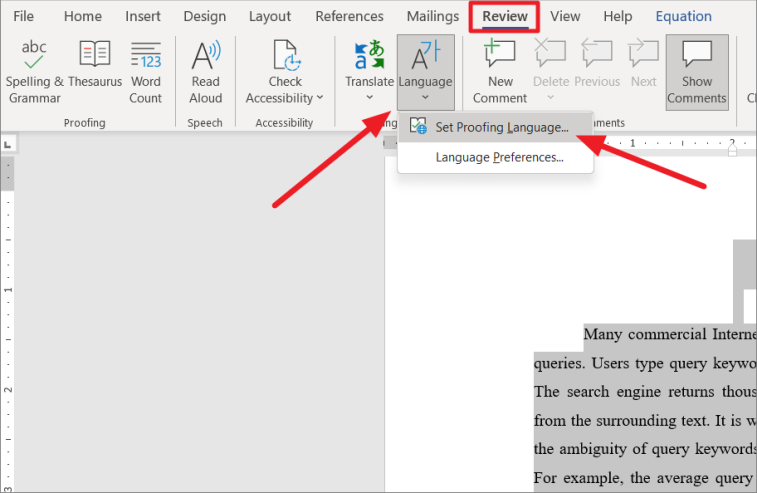
Затем перейдите на вкладку «Обзор», нажмите кнопку «Язык» на ленте и выберите параметр «Установить язык проверки правописания».

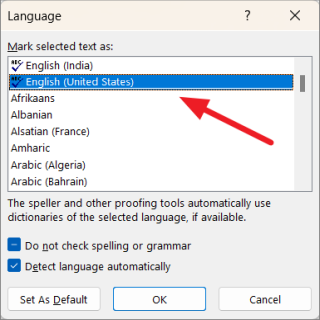
Здесь, во-первых, убедитесь, что для текста выбран правильный язык. Например, если язык установлен как «испанский», но документ на «английском», Word будет выделять каждое английское слово как слово с ошибкой. Кроме того, если ваш язык установлен как английский (США) и вы используете британский английский (например, если вы используете слово «привкус» вместо «вкус»), это будет выделено как ошибка.
Итак, выберите правильный язык в разделе «Пометить выделенный текст как:».

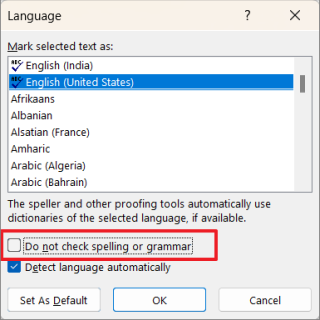
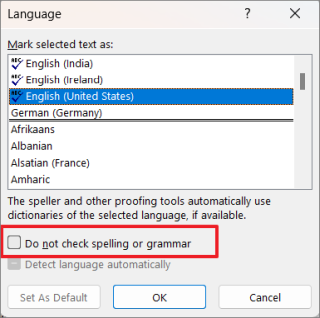
Затем убедитесь, что флажок «Не проверять орфографию или грамматику» не установлен. Если нет, снимите этот флажок.

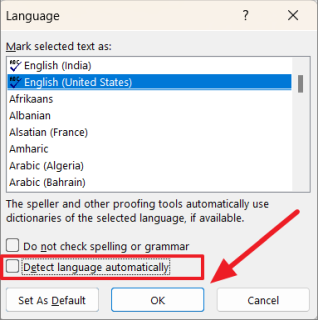
Вы также можете снять флажок «Определять язык автоматически», потому что автоматическое распознавание языка может иногда вызывать ошибки, если вы время от времени используете некоторые слова на другом языке (кроме установленного языка).

Когда вы закончите, нажмите «ОК».
После выполнения вышеуказанных шагов нажмите F7клавишу, чтобы запустить средство проверки орфографии и грамматики, и посмотрите, устранена ли проблема. Если нет, попробуйте следующий метод.
Проверка исключений проверки
В Word есть еще один параметр, который может помешать правильной работе проверки орфографии. Исключение проверки правописания — это параметр, который может освобождать определенные документы от всех проверок правописания и правописания. Убедитесь, что эта опция отключена для правильной работы проверки орфографии. Для этого выполните следующие действия:
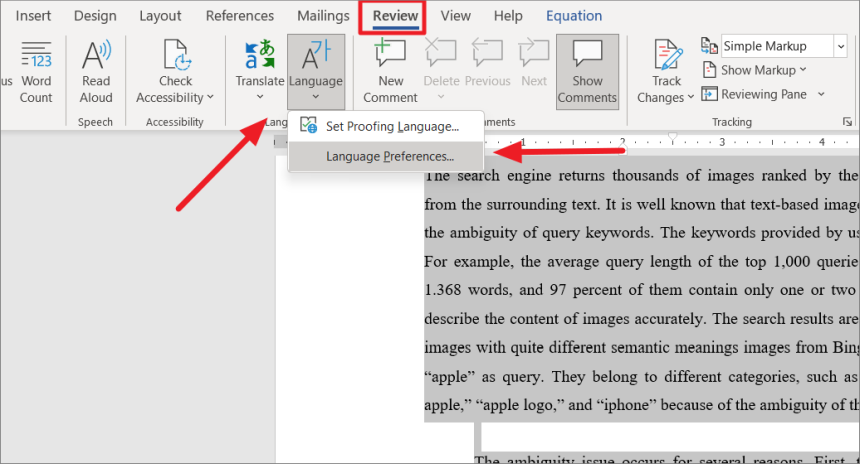
Сначала откройте Microsoft Word или вы можете открыть любой документ Word на компьютере. После этого выберите весь контент, нажав Ctrl+ A, затем перейдите на вкладку «Обзор» и нажмите кнопку «Язык». Затем нажмите «Языковые настройки…».

Кроме того, вы можете перейти на вкладку «Файл» на ленте, затем выбрать «Параметры», чтобы открыть параметры Word.
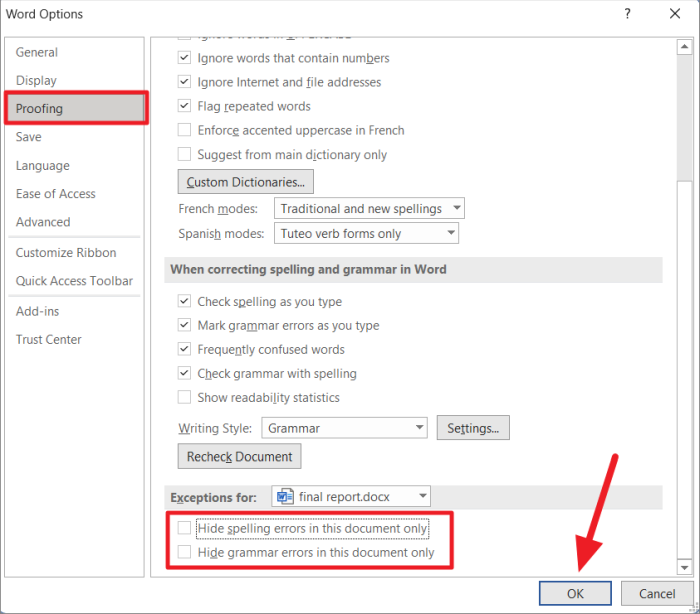
В окне «Параметры Word» перейдите на вкладку «Правописание» на левой панели. На правой боковой панели прокрутите вниз до раздела «Исключения для» внизу. Затем убедитесь, что оба флажка «Скрыть орфографические ошибки только в этом документе» и «Скрыть грамматические ошибки только в этом документе» не отмечены флажками. Затем нажмите «ОК», чтобы сохранить настройки.

Включить проверку орфографии при вводе
Если проверка орфографии не работает в каком-либо документе, это может быть связано с тем, что параметр «Проверять орфографию при вводе» (который проверяет документ на наличие ошибок в режиме реального времени) не включен. Вот как вы можете включить его:
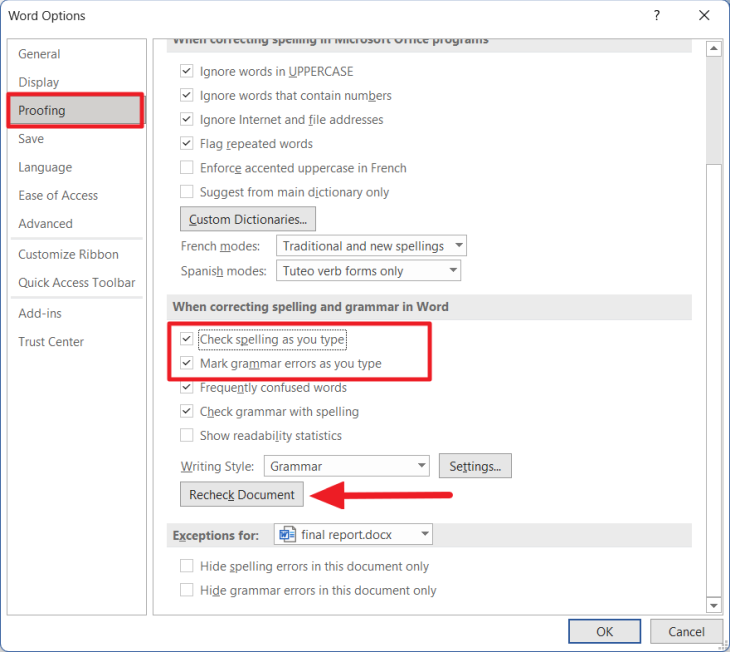
Перейдите на вкладку «Файл», выберите «Параметры» на правой боковой панели в нижней части меню.

Когда откроется диалоговое окно «Параметры Word», щелкните раздел «Правописание». На правой боковой панели перейдите к разделу «При исправлении орфографии и грамматики в Word». Затем обязательно выберите параметры «Проверять орфографию при вводе» и «Отмечать грамматические ошибки при вводе» в этом разделе.
Затем нажмите кнопку «Перепроверить документ», чтобы перепроверить документ.

Нажмите «Да» в окне подтверждения.

После этого нажмите «ОК», чтобы сохранить настройки и проверить документ.
Запустите Microsoft Word в безопасном режиме
Если какая-либо надстройка или другая программа мешает работе средства проверки орфографии и вызывает его сбой, вы можете запустить Microsoft Word в безопасном режиме (загружается без каких-либо надстроек) и выяснить, в чем причина проблемы. Вот как вы можете это сделать:
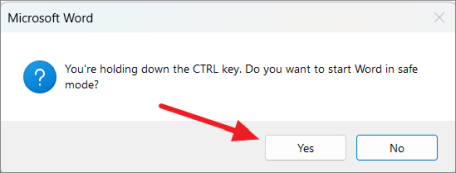
Нажмите и удерживайте Ctrl клавишу, а затем дважды щелкните любой документ Word на вашем компьютере, чтобы открыть его.

В приподнятом окне нажмите «Да».

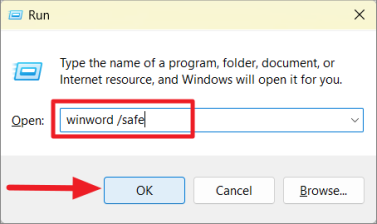
Кроме того, вы можете запустить программу Word в безопасном режиме с помощью команды «Выполнить».
Для этого сначала откройте окно команды «Выполнить» с помощью сочетаний клавиш Ctrl+. RЗатем введите winword /safeкоманду «Выполнить» и нажмите Enterили щелкните «ОК».

Это откроет Word в безопасном режиме.

Теперь нажмите «Файл» и выберите «Создать» или нажмите Ctrl+ N , чтобы открыть новый черный документ. Затем введите текст и проверьте, работает ли проверка орфографии.
Если проверка орфографии работает в безопасном режиме, то проблема должна быть с одной из надстроек. Затем отключите ненужную надстройку, которая вызывает проблему.
Отключить конфликтующие надстройки в Word
В некоторых случаях сторонняя надстройка может работать со сбоями или вызывать конфликт со средством проверки орфографии и грамматики. Если проверка орфографии корректно работала в безопасном режиме с минимальным функционалом, то проблема могла быть в какой-либо из установленных надстроек. Поэтому вам нужно отключить сторонние надстройки одну за другой, чтобы найти, какая из них вызывает конфликт. Или вы можете отключить их все и переустановить их одну за другой, чтобы найти конфликтующую надстройку. Чтобы отключить надстройки, следуйте этим инструкциям:
Откройте вкладку «Файл» и выберите «Параметры» на левой панели.

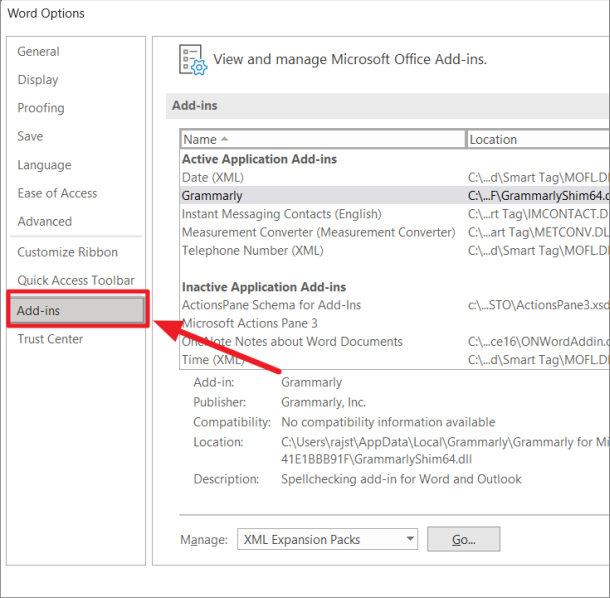
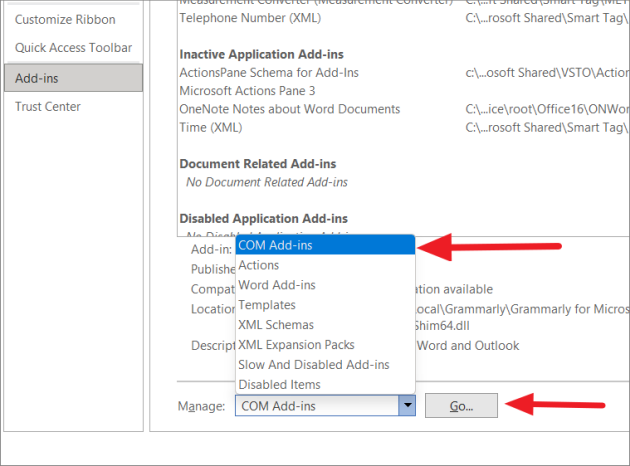
В параметрах Word выберите «Надстройки» на левой панели.

Затем в нижней части экрана выберите параметр «Надстройки COM» в раскрывающемся меню «Управление» и нажмите кнопку «Перейти».

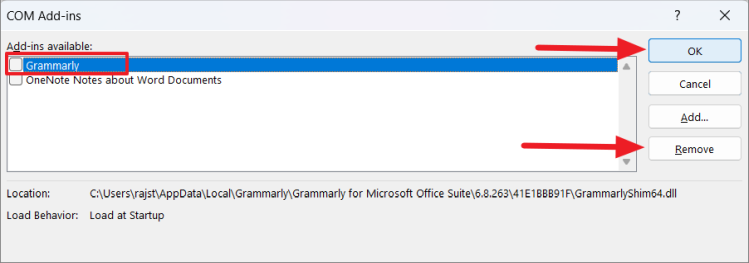
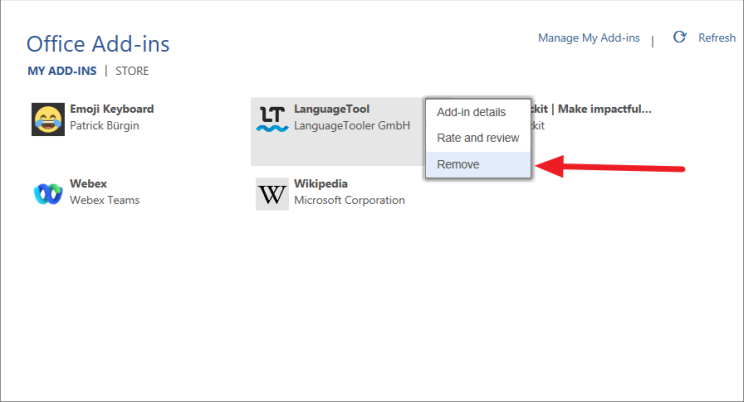
Во всплывающем окне «Надстройки COM» просто снимите флажок с надстройки, которая, по вашему мнению, вызывает проблему, чтобы отключить ее. Если вы хотите удалить надстройку, выберите надстройку и нажмите «Удалить». Затем нажмите «ОК», чтобы закрыть диалоговое окно.

Иногда не все надстройки отображаются в диалоговом окне надстроек COM. Если установленная надстройка недоступна в поле Надстройки COM, сделайте следующее:
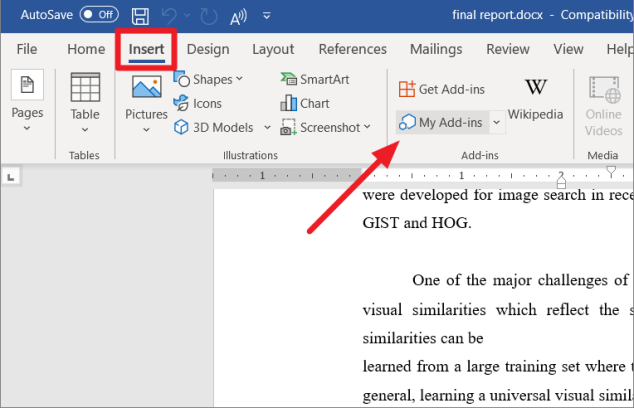
Перейдите на вкладку «Вставка» и нажмите кнопку «Мои надстройки» в группе надстроек.

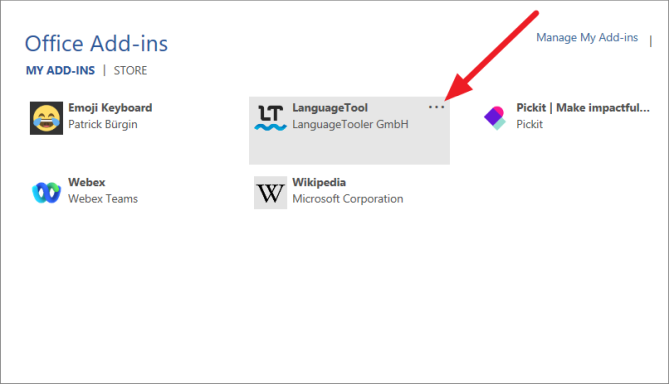
В разделе «Надстройки Office» нажмите кнопку с тремя точками («Параметры») рядом с надстройкой, которую вы хотите удалить.

Затем нажмите «Удалить» в меню.

Теперь проверьте, работает ли проверка орфографии или нет.
Переименовать папку реестра Windows
Некоторые пользователи утверждают, что для решения проблемы необходимо переименовать папку инструментов проверки правописания в редакторе реестра. Следуйте этим инструкциям, чтобы переименовать папку проверки:
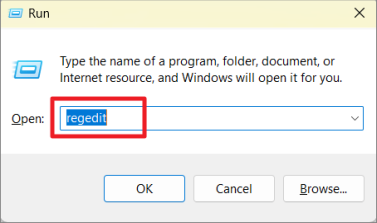
Сначала полностью закройте программу Word, затем запустите окно команды «Выполнить», нажав Win+ R. Введите regedit, чтобы открыть редактор реестра. И, если вы видите диалоговое окно «Контроль учетных записей», нажмите «Да».

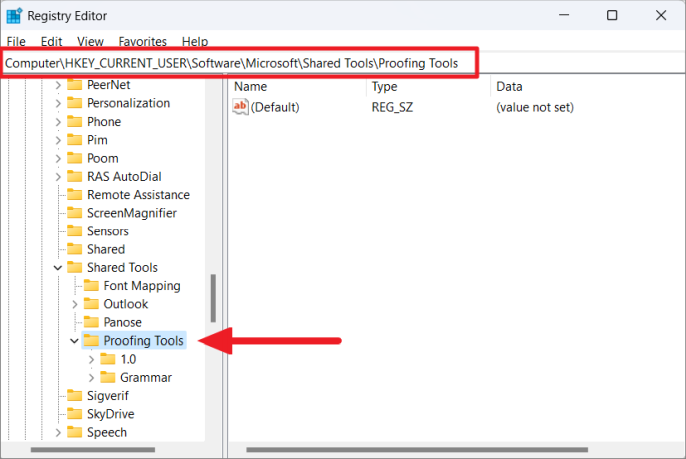
В окнах реестра Windows перейдите по следующему пути, используя левую панель, или скопируйте и вставьте указанный ниже путь в адресную строку:
HKEY_CURRENT_USERSoftwareMicrosoftShared ToolsProofing Tools

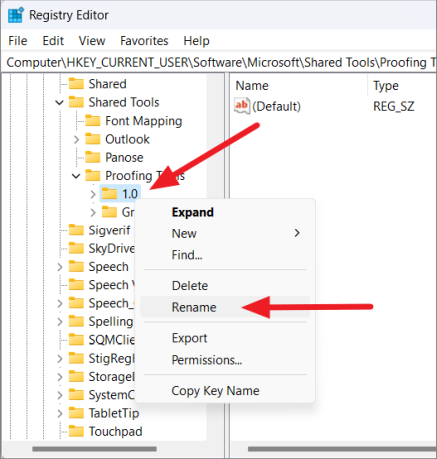
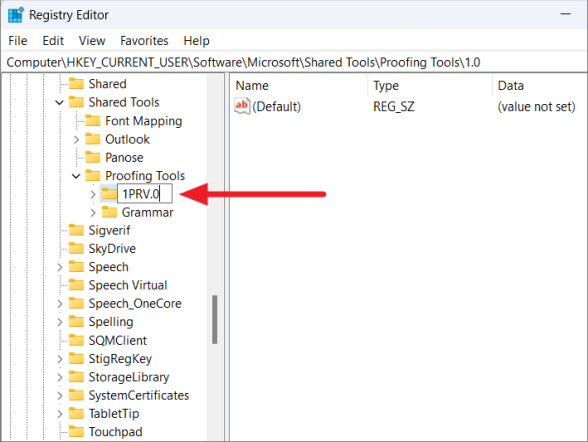
В разделе «Инструменты проверки правописания» щелкните правой кнопкой мыши папку «1.0» и выберите параметр «Переименовать» в контекстном меню.

Переименуйте папку с «1.0» на «1PRV.0».

После этого закройте редактор реестра и перезагрузите компьютер, чтобы изменения вступили в силу. Теперь перезапустите Microsoft Word и еще раз проверьте, работает ли проверка орфографии.
Переименуйте свой шаблон Word
Также возможно, что проверка орфографии не работает из-за поврежденного глобального шаблона. Глобальный шаблон — это «normal.dot» или «normal.dotm» для Word 2007 и более поздних серий соответственно, которые обычно находятся в папке шаблонов Microsoft. Чтобы решить эту проблему, вам нужно переименовать файл глобального шаблона, который вернет MS Word к настройкам по умолчанию. Для этого выполните следующие действия:
Откройте команду «Выполнить» (Win+ R), введите следующее и нажмите Enter:
%appdata%MicrosoftTemplates
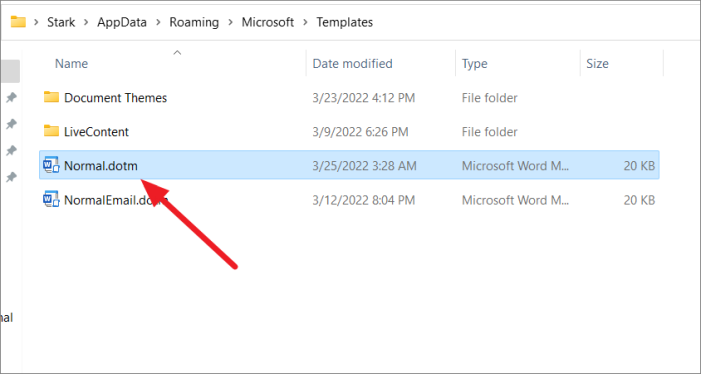
Откроется папка шаблонов Microsoft Word, в которой вы можете найти файл normal.dot или normal.dotm в зависимости от версии Word.

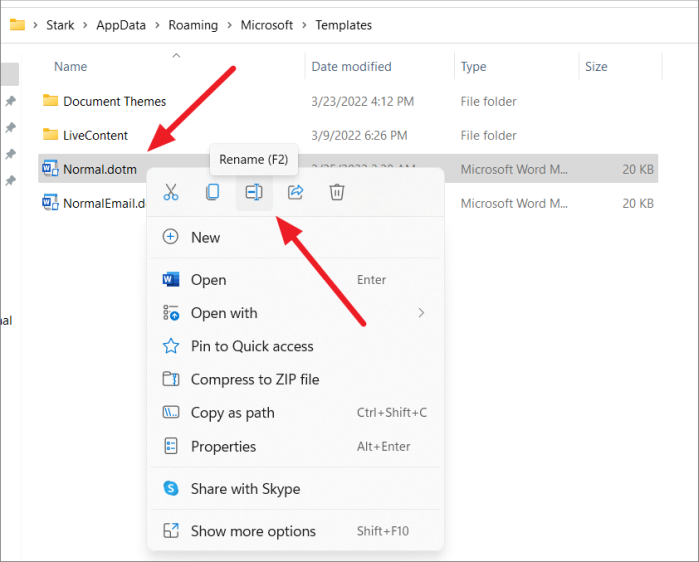
Теперь щелкните файл правой кнопкой мыши и выберите значок «Переименовать» или нажмите F2.

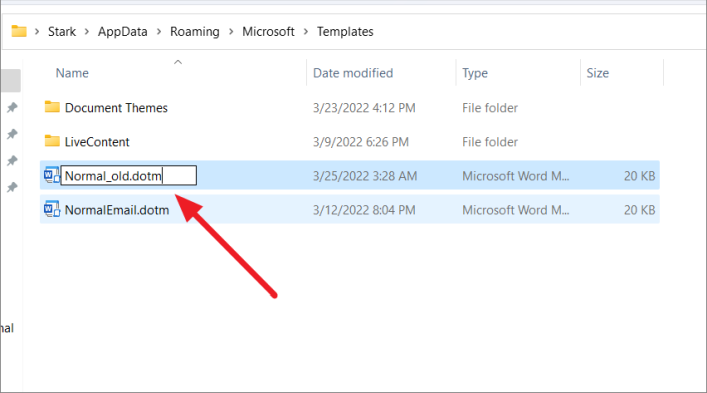
Затем переименуйте файл из Normal.dotm в «Normal_old.dotm».

Это сбросит настройки Word на значения по умолчанию и, надеюсь, решит вашу проблему.
Добавить язык проверки
Хотя вы можете писать или редактировать документ на английском языке, предпочитаемым языком авторства и проверки может быть выбран иностранный язык (например, немецкий). Если вы случайно установили другой язык проверки правописания или удалили английский из списка, проверка орфографии может не работать.
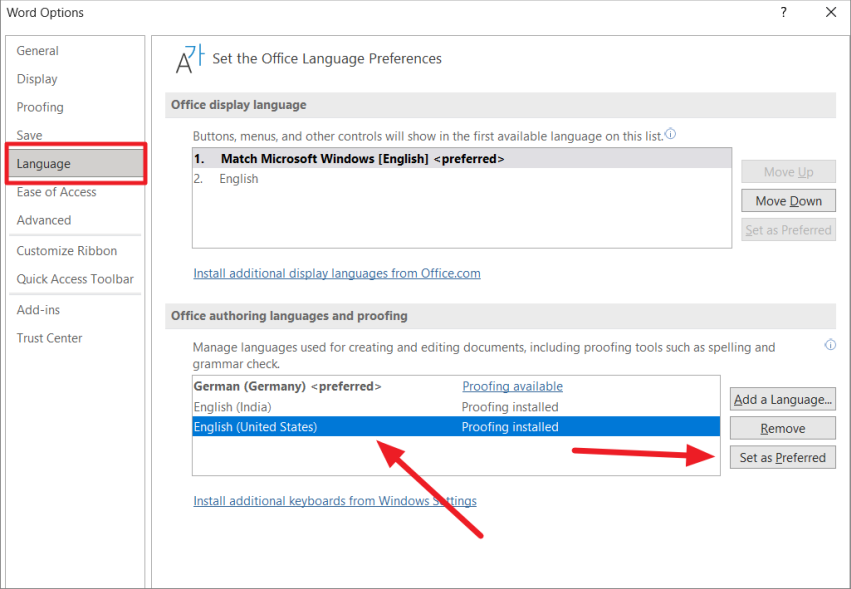
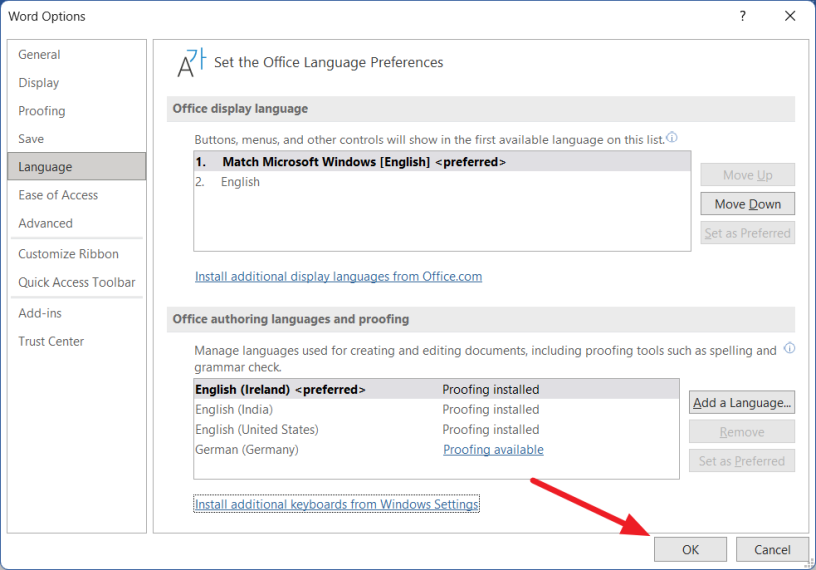
Чтобы исправить это, откройте меню «Файл» и перейдите в «Параметры» в представлении «За кулисами». Затем перейдите в раздел «Язык» слева и убедитесь, что правильный язык установлен и установлен в качестве предпочтительного в разделе «Языки разработки Office и проверка правописания».
Чтобы установить язык проверки, выберите язык и нажмите кнопку «Установить как предпочтительный». В приведенном ниже примере в качестве предпочтительного языка выбран немецкий.

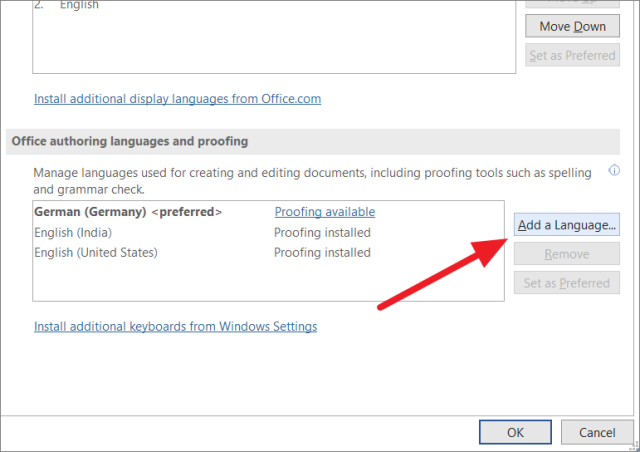
Если ваш язык недоступен в разделе «Языки разработки Office и проверка правописания», нажмите кнопку «Добавить язык», чтобы добавить язык проверки.

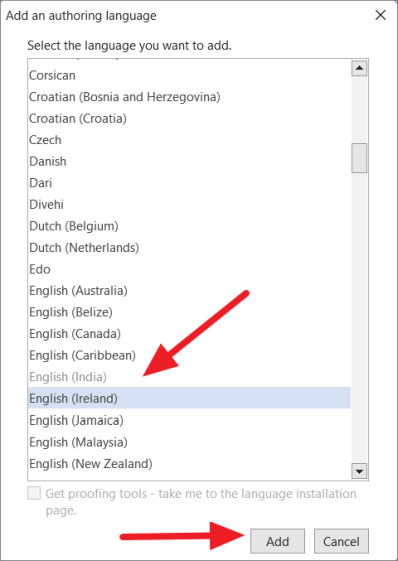
Во всплывающем окне выберите язык, который вы хотите добавить, из списка и нажмите кнопку «Добавить».

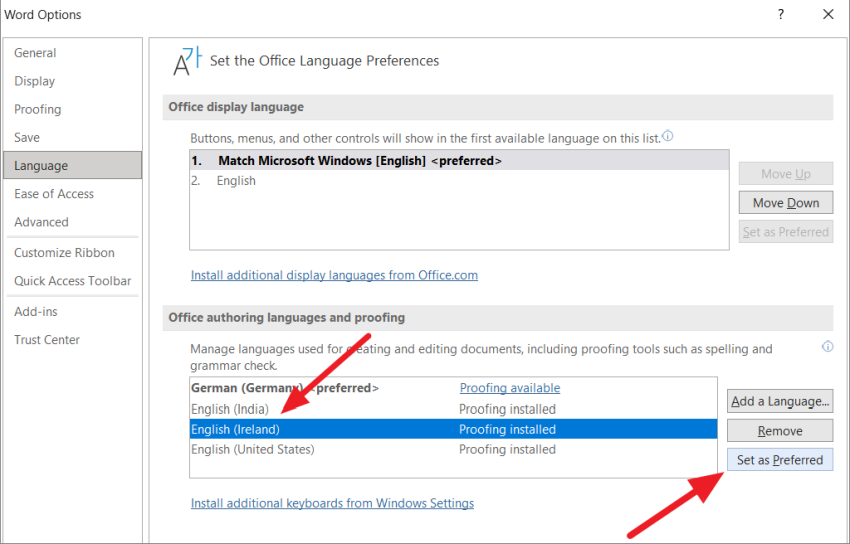
После этого выберите язык из списка и нажмите «Установить как предпочтительный».

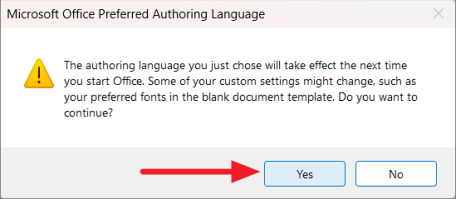
Затем нажмите «Да» во всплывающем окне «Предпочтительный авторский язык Microsoft Office».

После выбора предпочтительного языка нажмите «ОК», чтобы закрыть параметры Word.

Теперь проверьте, работает ли инструмент проверки орфографии и грамматики.
Добавить в пользовательский словарь
Бывают случаи, когда Word не может распознать определенные слова, такие как ругательства, имена и т. д. И программа будет изо всех сил пытаться обнаружить орфографические и грамматические ошибки. В таких случаях вы можете добавить свои слова во встроенный словарь Word, и они не будут отображаться как ошибки в этом документе и во всех будущих документах.
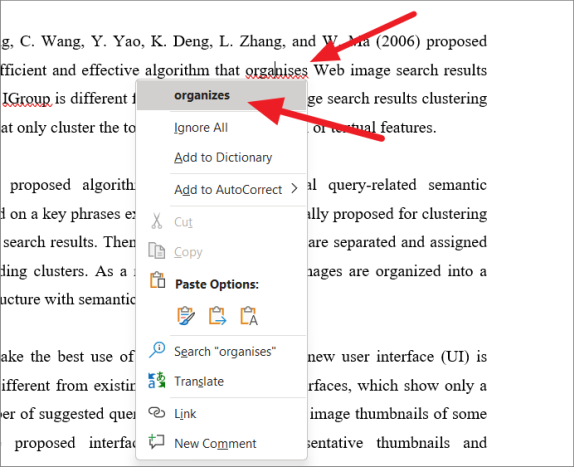
Чтобы добавить слово в словарь, щелкните правой кнопкой мыши слово, которое хотите добавить, и выберите в контекстном меню пункт «Добавить в словарь».

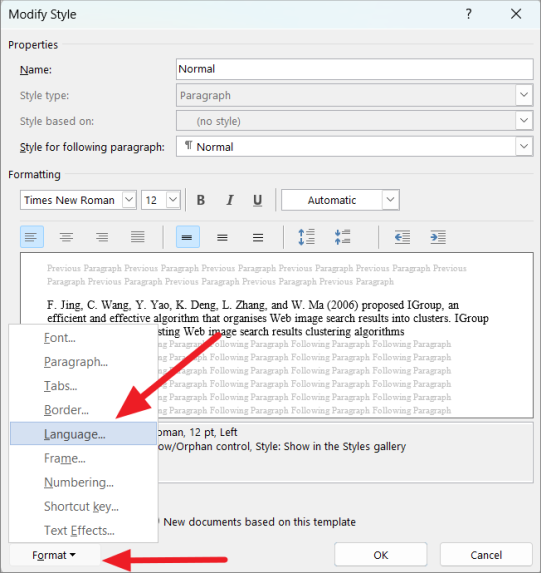
Проверьте настройки стиля документа
Word использует разные языковые настройки для каждого абзаца документа. Если вы используете стиль, который отформатирован неправильно, то каждый новый абзац будет отформатирован на другом языке, даже если вы установите английский язык для всего документа. Следовательно, Word может выделить слова в новом абзаце как орфографические ошибки. Чтобы это исправить, вы должны установить правильный язык в Style.
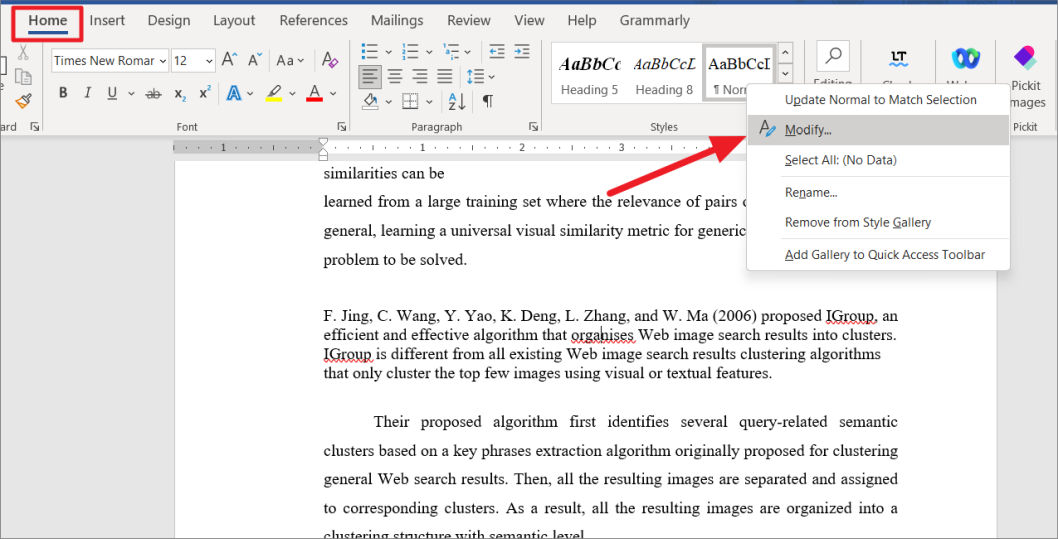
На вкладке «Главная» перейдите в раздел «Стили», затем щелкните правой кнопкой мыши выбранный стиль и выберите «Изменить» в контекстном меню.

В диалоговом окне «Изменить стиль» нажмите кнопку «Формат» в левом нижнем углу и выберите «Язык» в меню.

Затем выберите правильный язык для выбранного стиля и убедитесь, что опция «Не проверять орфографию или грамматику» не отмечена. Затем нажмите «ОК».

Восстановить приложение MS Office
Приложение MS Word могло быть повреждено или, возможно, недавнее обновление повредило установку вашего программного обеспечения. В любом случае, поврежденное или испорченное приложение MS Word также может быть еще одной причиной того, что инструмент проверки орфографии и грамматики не работает. Поэтому восстановление приложения MS Office на вашем компьютере может решить вашу проблему.
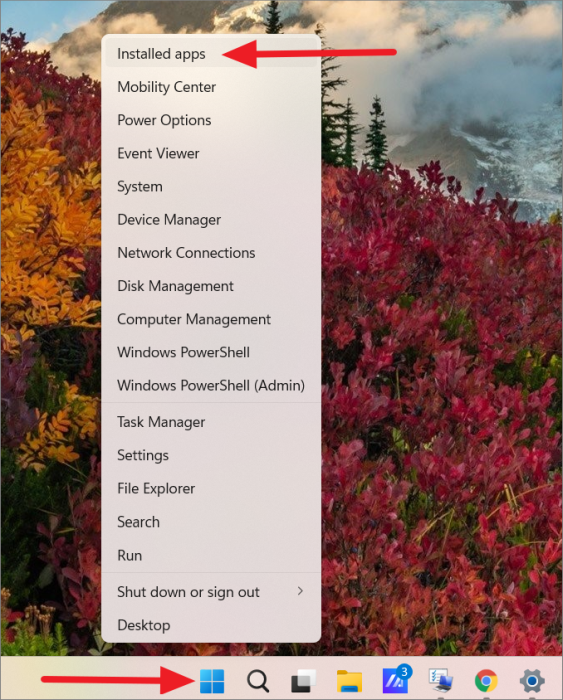
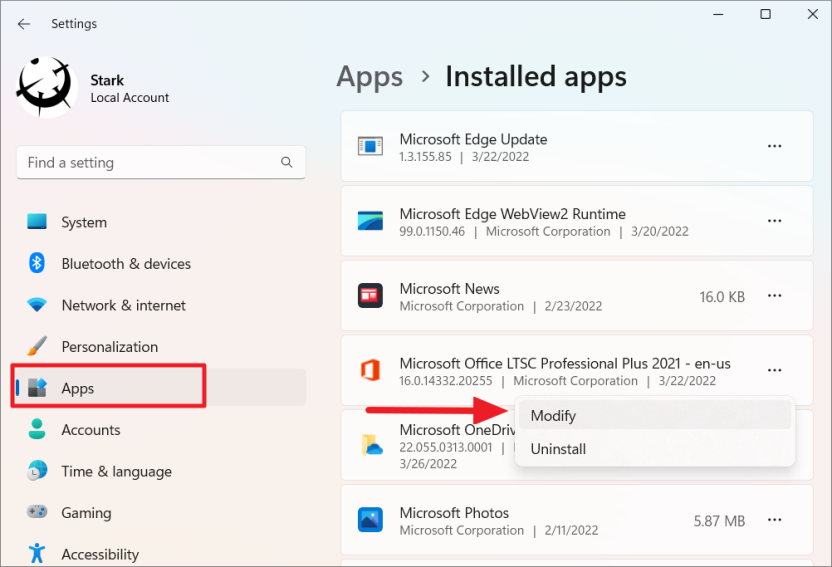
Сначала щелкните правой кнопкой мыши меню «Пуск» Windows и выберите в меню пункт «Установленные приложения». или Перейдите в «Настройки Windows» (Win+ I) и перейдите в «Приложения», а затем «Приложения и функции».

В списке установленных приложений найдите установленную версию Microsoft Office. Затем нажмите кнопку с тремя точками и выберите «Изменить».

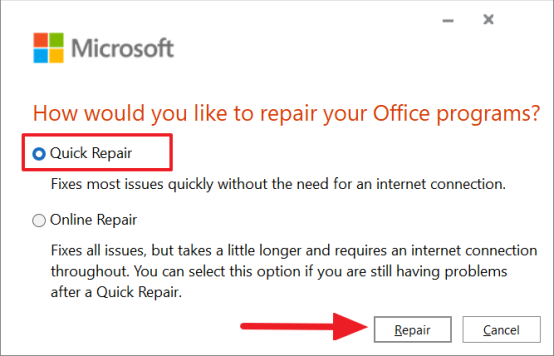
И нажмите «Да» для контроля учетных записей пользователей, если будет предложено. В окне восстановления Microsoft у вас будет два варианта. Сначала выберите опцию «Быстрое восстановление» и нажмите кнопку «Восстановить».

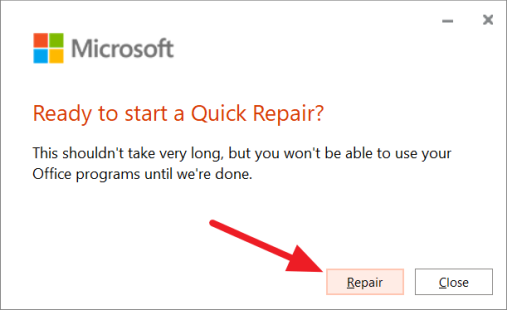
В следующем диалоговом окне снова нажмите кнопку «Восстановить».

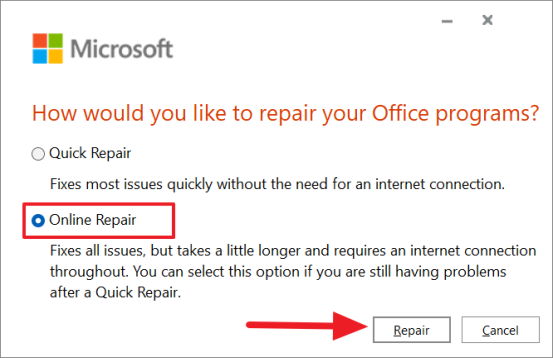
Если указанный выше вариант не устраняет проблему, выберите вариант «Онлайн-восстановление» и нажмите кнопку «Восстановить».

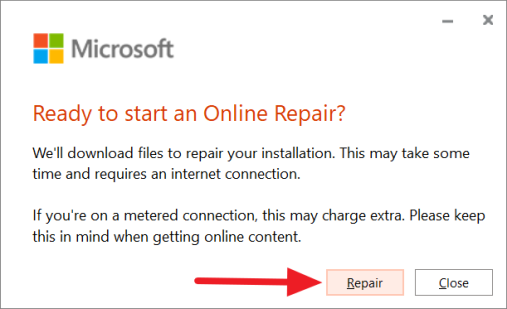
Затем снова нажмите «Восстановить».

После завершения ремонта перезагрузите устройство и посмотрите, устранена ли проблема.

Отключите параметр « Не проверять орфографию или грамматику».
Иногда, когда вы пытаетесь проверить орфографию, появляется сообщение об ошибке «Текст, помеченный как «Не проверять орфографию или грамматику», был пропущен». Word обычно показывает это сообщение, когда вы используете параметр «Не проверять орфографию» в языковых настройках, чтобы игнорировать определенные слова из средства проверки орфографии. Однако, если этот параметр настроен неправильно, Word пропустит проверку орфографии для всех слов в документе. Вот как вы можете отключить эту опцию:
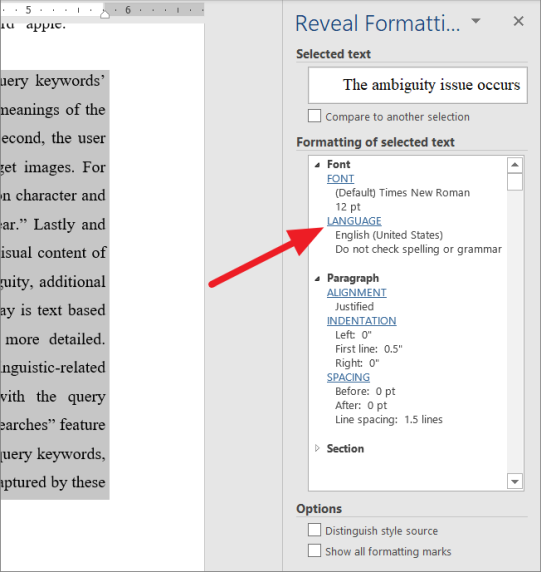
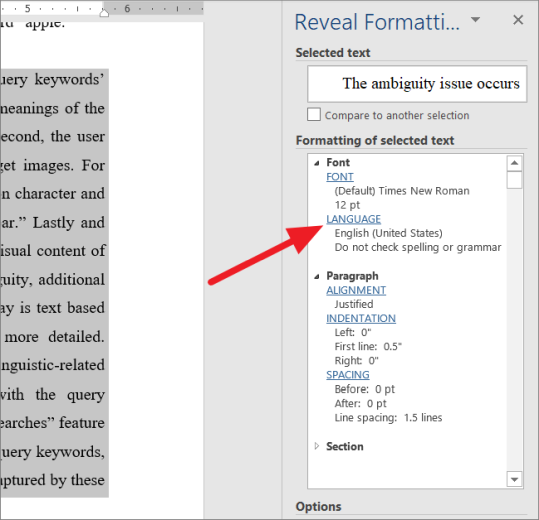
Откройте документ Word и выделите абзац или конкретное слово, которое не отображается в средстве проверки орфографии. Далее нажмите клавиши быстрого доступа Shift+.F1

Это покажет вам панель «Показать форматирование» в правой части окна Word.

На панели «Показать форматирование» щелкните параметр «Язык» в разделе «Форматирование выбранного текстового поля».

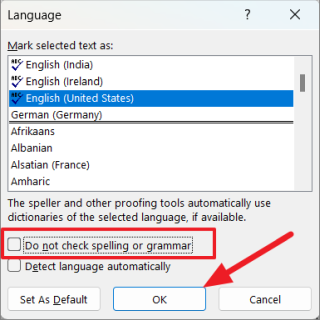
Когда появится диалоговое окно «Язык», обязательно снимите флажок «Не проверять орфографию или грамматику». После этого нажмите «ОК» и перезапустите программу Word.
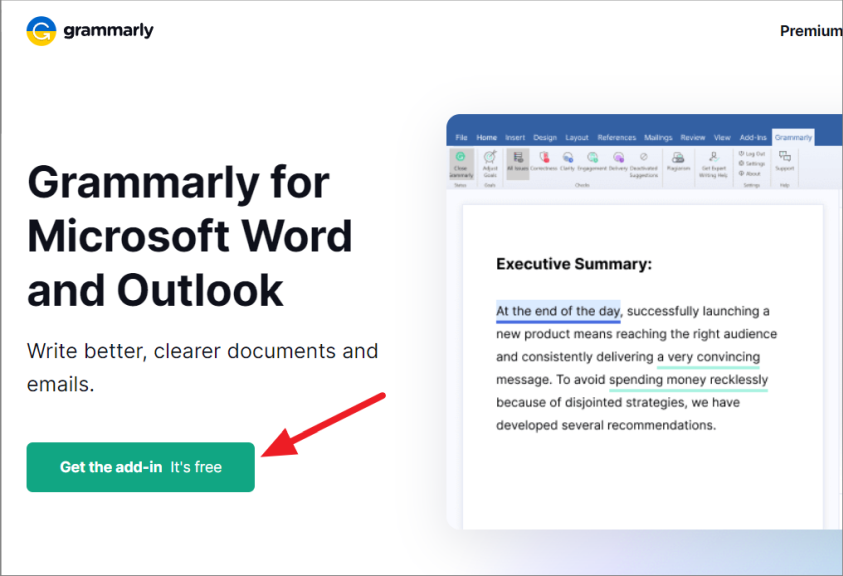
Используйте плагин Grammarly
Если инструмент проверки орфографии и грамматики Word не работает, в качестве альтернативы можно использовать подключаемый модуль Grammarly. Grammarly — это облачный помощник по набору текста, который помогает обнаруживать и исправлять орфографические ошибки, несовершенную грамматику и пунктуационные ошибки. Кроме того, Grammarly легко интегрируется с Microsoft Word и Outlook.
Чтобы загрузить Grammarly для Word и Outlook, перейдите на этот веб- сайт и нажмите кнопку «Получить надстройку. Это бесплатно». После загрузки надстройки установите ее.

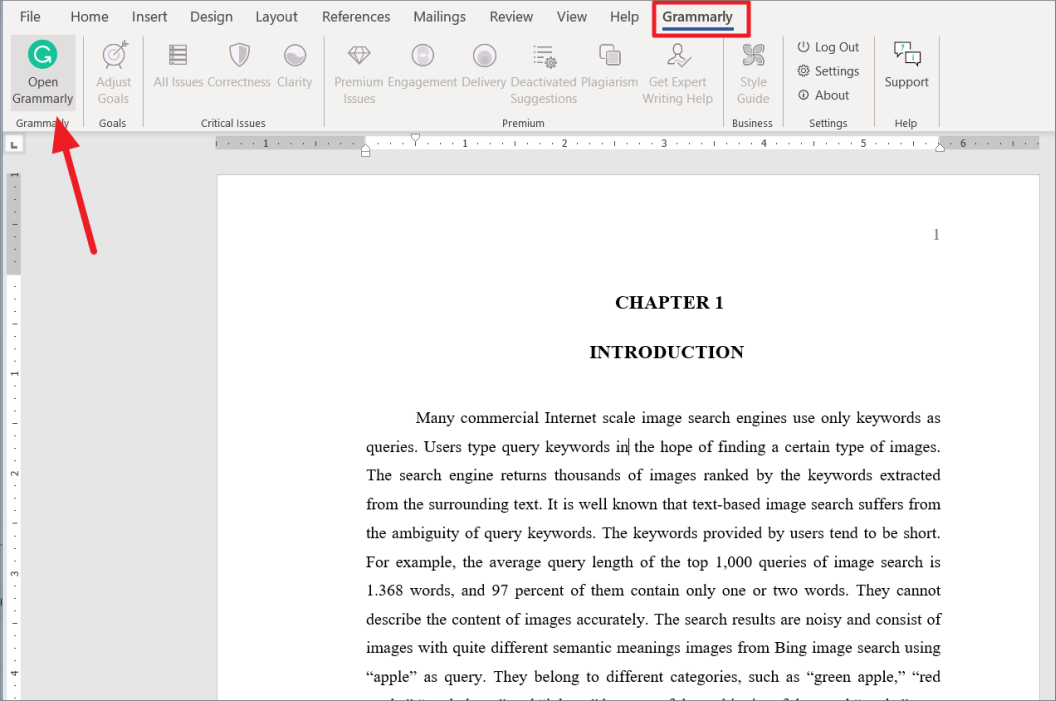
Затем перезапустите приложение Word, и вы увидите новую вкладку под названием «Грамматика» на ленте.
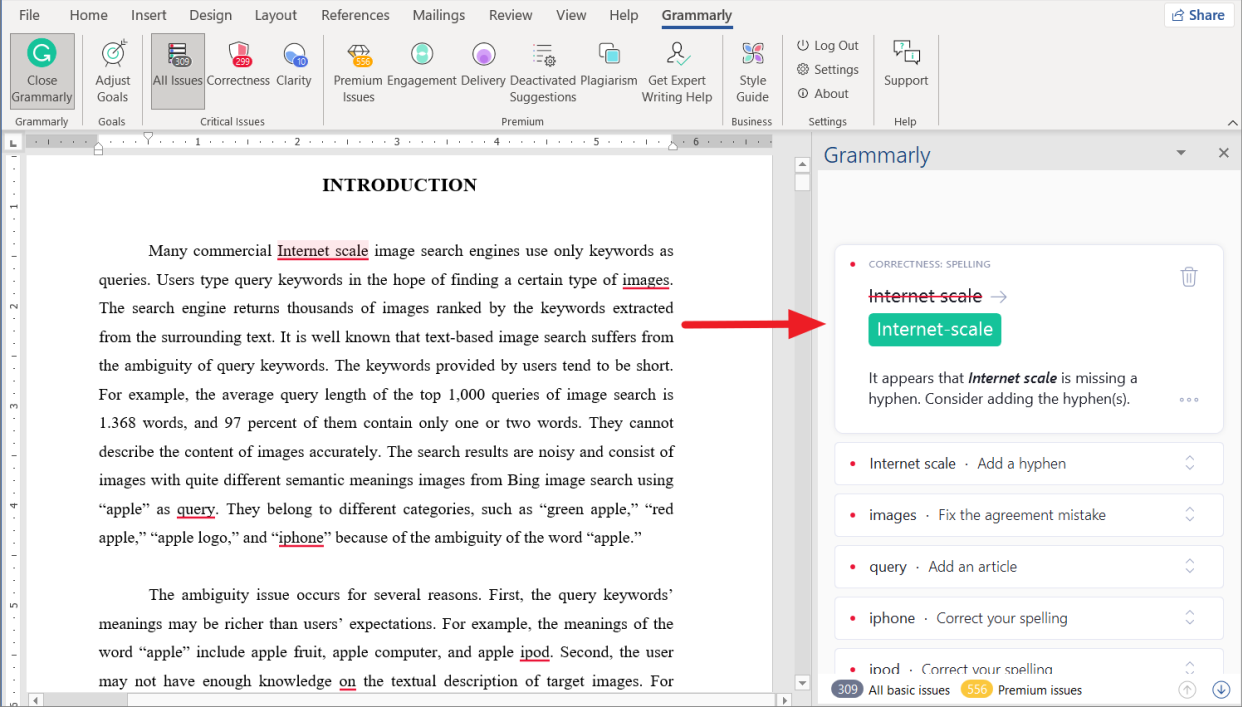
Теперь вы можете открыть любой документ, перейти на вкладку «Grammarly» и нажать «Открыть Grammarly».

Откроется панель Grammarly справа, где будет отсканирован документ и показаны предложения по исправлению орфографических и грамматических ошибок.

Вы также можете использовать веб-приложение Microsoft Word для быстрой проверки орфографии в документе. Если у вас есть подписка на Microsoft 365, вы можете открыть тот же документ в веб-приложении и быстро проверить наличие орфографических и грамматических ошибок в Интернете.
Вот и все.
2022-03-28T10:35:33
Вопросы читателей