Для вывода сервиса из изолированной сети в Docker, можно использовать несколько подходов в зависимости от конкретной задачи. Вот несколько способов, которые могут быть полезными в такой ситуации: Читать
7 основных исправлений для Microsoft PowerPoint, не воспроизводящего аудио в Windows
Интеграция звука в презентацию PowerPoint может сделать ее более динамичной и увлекательной. Будь то повествование, фоновая музыка или легкие звуковые эффекты, есть много веских причин добавлять звук в презентации PowerPoint. Но что, если Microsoft PowerPoint перестанет воспроизводить звук на вашем компьютере с Windows 10 или 11?
Устранить эту проблему может быть так же просто, как использование совместимого формата файла, или так же утомительно, как идентификация проблемной надстройки. В этом руководстве представлены все возможные решения для устранения проблем с воспроизведением звука в Microsoft PowerPoint для Windows.
1. Проверьте уровень громкости в PowerPoint и Windows.
Ваш первый шаг — перепроверить уровень громкости в PowerPoint и на компьютере с Windows. Если громкость слишком низкая или отключен звук, может сложиться впечатление, что звук не работает в PowerPoint.
Шаг 1. Откройте презентацию PowerPoint и выберите любой аудио- или видеофайл.
Шаг 2. Перейдите на вкладку «Воспроизведение», нажмите «Громкость» и выберите параметр «Средний» или «Высокий».
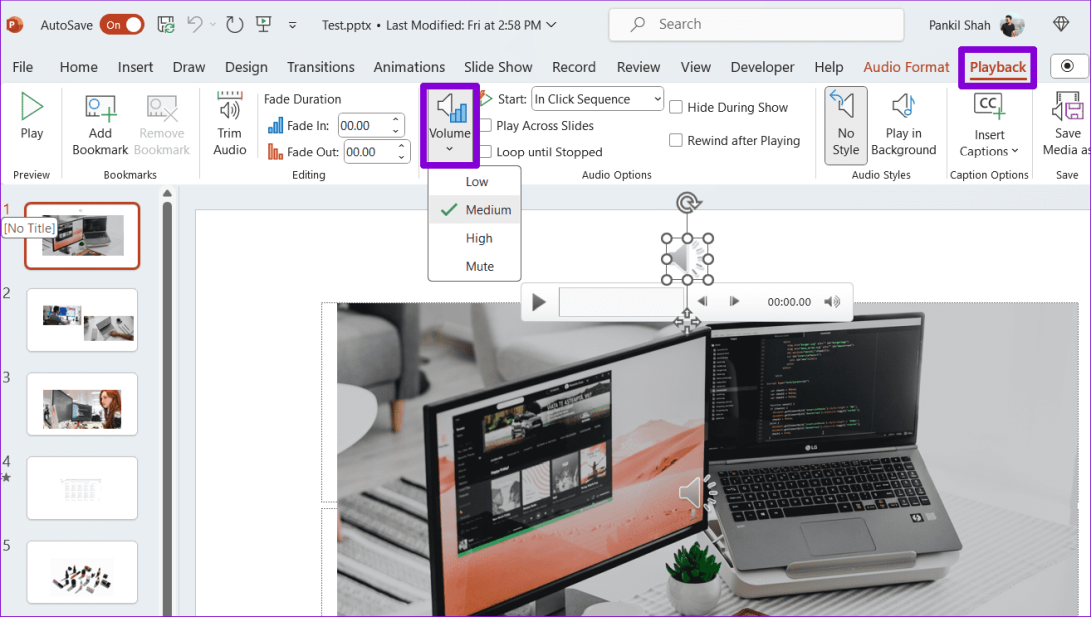
Шаг 3: Щелкните правой кнопкой мыши значок динамика на панели задач и выберите «Открыть микшер громкости».
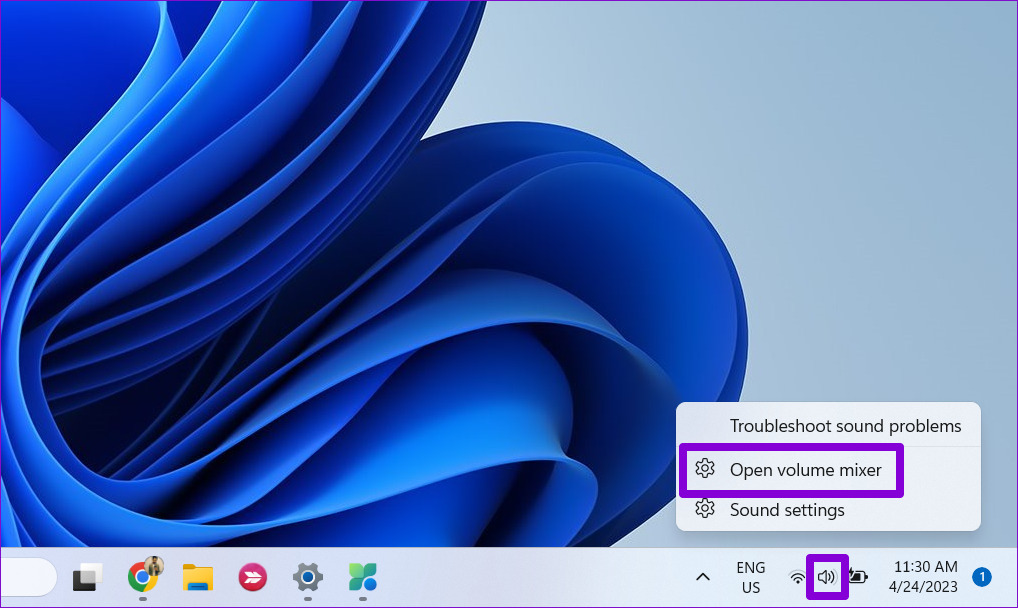
Шаг 4. Переместите ползунок PowerPoint вправо, чтобы увеличить громкость.
Вернитесь в PowerPoint и проверьте, нормально ли воспроизводится звук.
2. Убедитесь, что аудиофайл совместим с PowerPoint.
Хотя Microsoft PowerPoint поддерживает множество популярных форматов аудиофайлов, таких как AIFF, AU, MP3, WAV, WMA и другие, он поддерживает не все из них. Если ваш аудиофайл имеет неподдерживаемый формат, PowerPoint может отображать ошибку «Невозможно воспроизвести мультимедиа». В этом случае вам нужно будет конвертировать файл в поддерживаемый формат с помощью онлайн-инструмента конвертации аудио.
3. Используйте опцию оптимизации медиа-совместимости.
Еще одна вещь, которую вы можете сделать, чтобы решить проблему отсутствия звука в режиме презентации, — это оптимизировать медиафайлы в PowerPoint для обеспечения совместимости. Это особенно полезно, если вы планируете поделиться презентацией или использовать ее на другом устройстве.
Шаг 1. Откройте презентацию PowerPoint и щелкните меню «Файл» в верхнем левом углу.
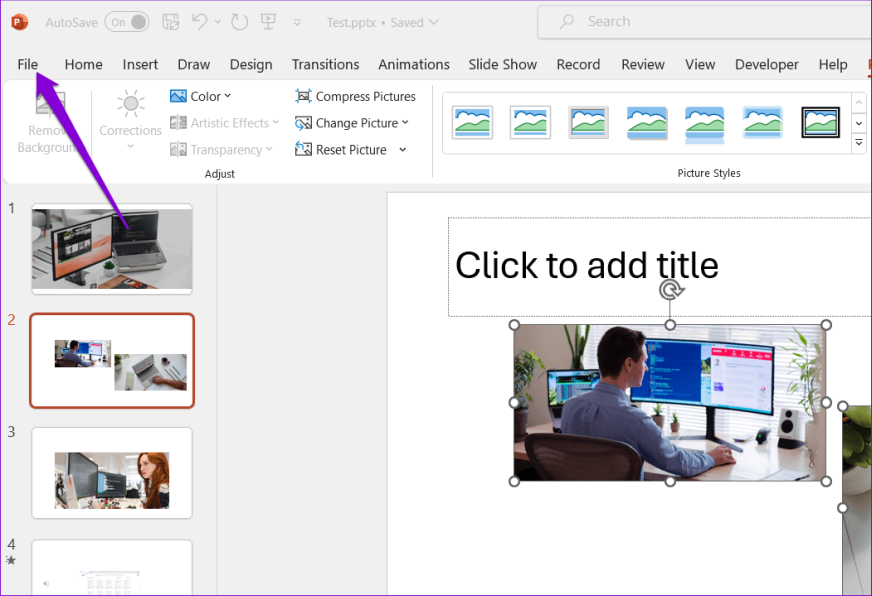
Шаг 2. Перейдите на вкладку «Информация» и нажмите кнопку «Оптимизировать совместимость».
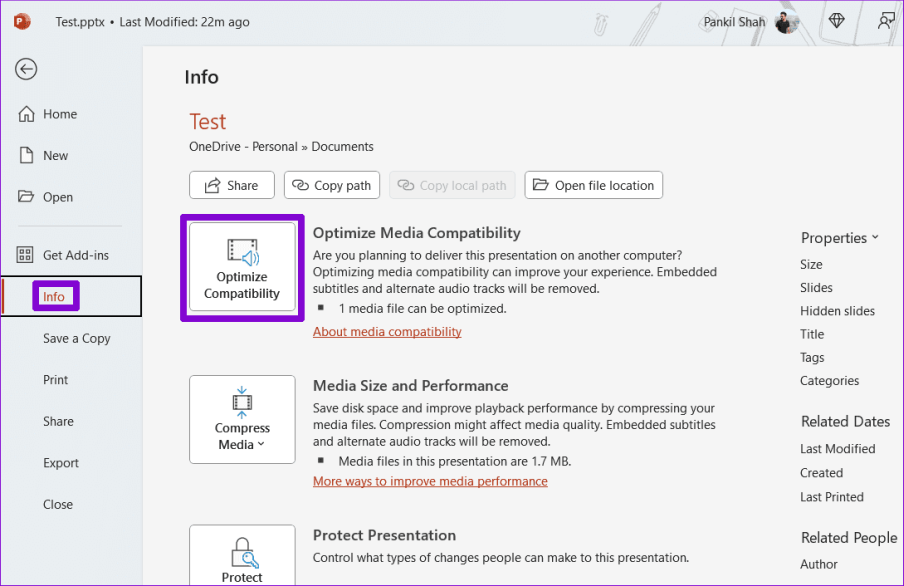
Шаг 3. Подождите, пока PowerPoint оптимизирует все аудио- и видеофайлы в вашей презентации, и нажмите «Закрыть».
4. Вставьте аудиофайл вместо того, чтобы связывать его
Возникли ли у вас проблемы с воспроизведением звука со связанными аудиофайлами в презентации? Хотя связывание аудиофайлов может уменьшить размер файла презентации, иногда это может вызывать проблемы, поскольку PowerPoint вынужден использовать внешний файл для воспроизведения звука.
Чтобы избежать каких-либо проблем, лучше всего встраивать аудиофайлы в презентацию, а не связывать их. Вот как:
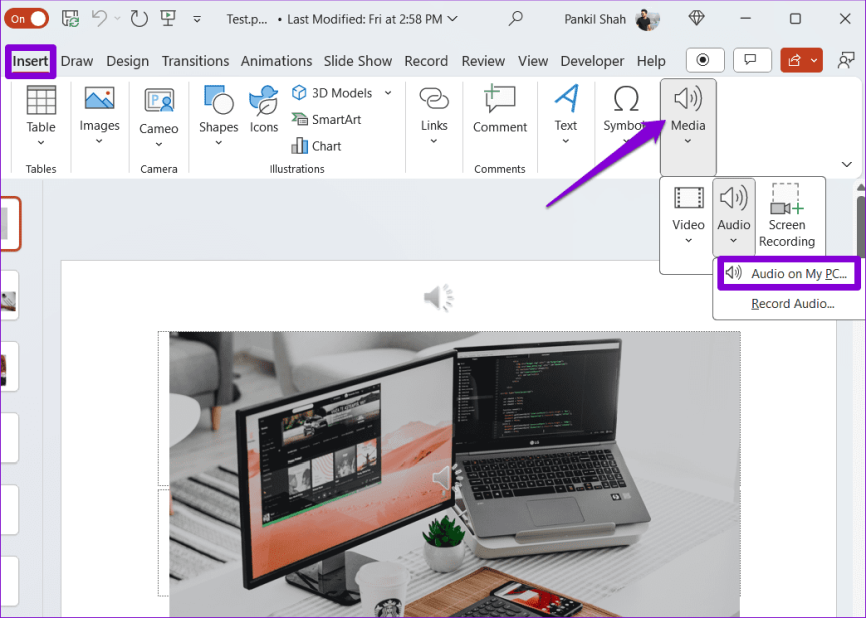
Шаг 1. Откройте презентацию PowerPoint и перейдите на вкладку «Вставка». Нажмите «Медиа», выберите «Аудио» и выберите «Аудио на моем компьютере».
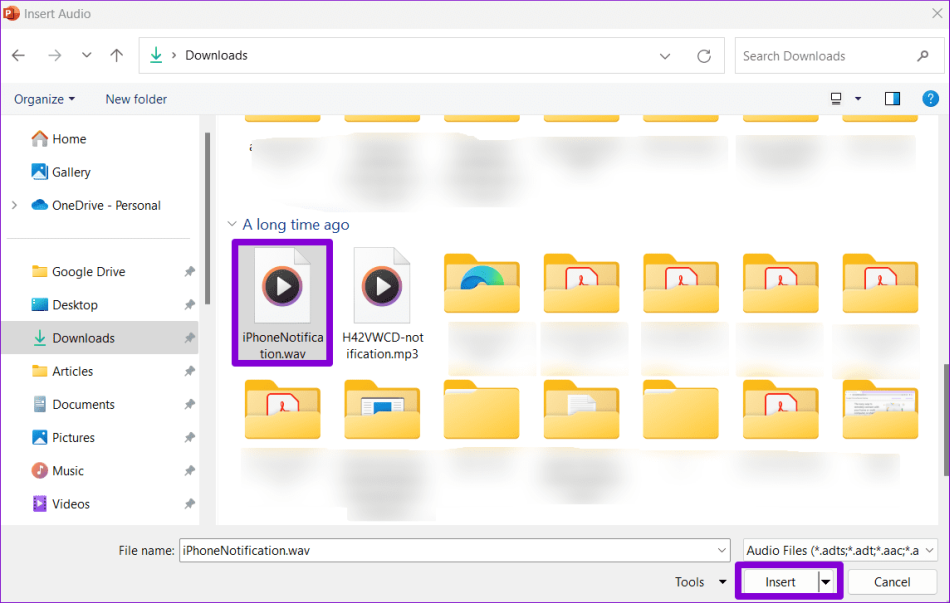
Шаг 2: Выберите аудиофайл и нажмите «Вставить». После этого проверьте, все ли в порядке.
5. Очистить временные файлы
Иногда временные файлы на вашем компьютере с Windows могут привести к замедлению работы и сбоям в работе приложений Office, таких как PowerPoint. Попробуйте удалить временные файлы с вашего компьютера и посмотрите, решит ли это проблему.
Шаг 1. Нажмите сочетание клавиш Windows+R, чтобы открыть диалоговое окно «Выполнить». Введите %temp% в поле и нажмите Enter.
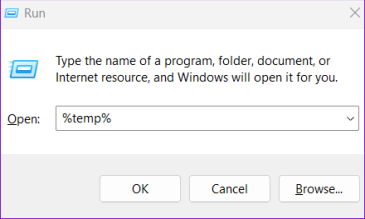
Шаг 2. В окне проводника выберите все файлы и папки и щелкните значок корзины вверху.
6. Откройте PowerPoint в безопасном режиме.
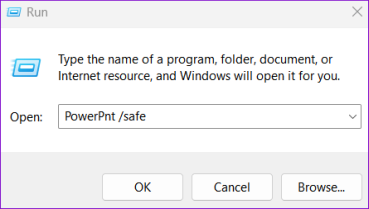
PowerPoint может не воспроизводить звук автоматически из-за неисправной сторонней надстройки. Чтобы проверить эту возможность, вы можете открыть PowerPoint в безопасном режиме. Нажмите сочетание клавиш Windows+R, чтобы открыть диалоговое окно «Выполнить». Введите powerpnt /safe в поле «Открыть» и нажмите Enter.
Когда PowerPoint откроется в безопасном режиме, проверьте, может ли он воспроизводить звук. Это означает, что одна из ваших надстроек вызывает проблему, если это возможно. Чтобы определить причину проблемы, вам необходимо отключить все надстройки и снова включить их по одной. Вот как:
Шаг 1. Откройте PowerPoint и щелкните меню «Файл» в верхнем левом углу.
Шаг 2: Выберите «Параметры» на левой панели.
Шаг 3. В окне «Параметры PowerPoint» перейдите на вкладку «Надстройки». Щелкните раскрывающееся меню рядом с пунктом «Управление» и выберите «Надстройки COM». Затем нажмите кнопку «Перейти» рядом с ним.
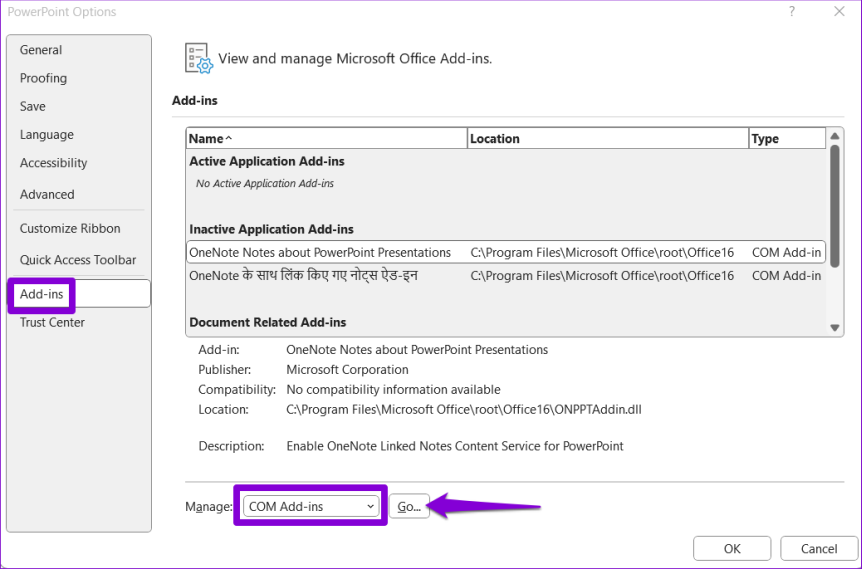
Шаг 4. Снимите все флажки, чтобы отключить надстройки, и нажмите «ОК».
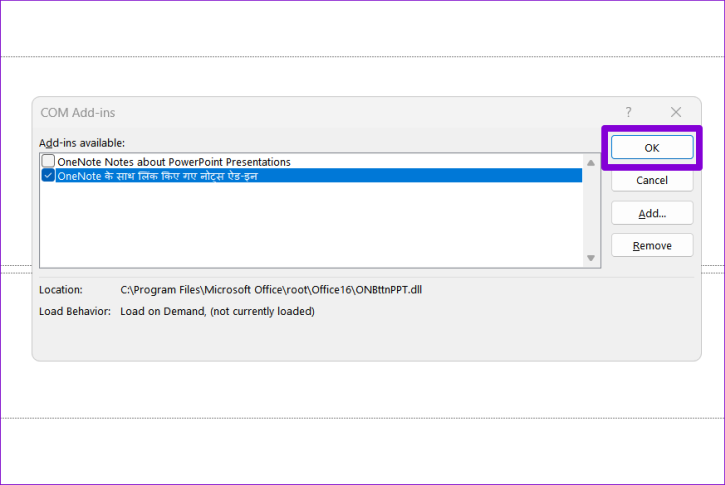
После этого перезапустите PowerPoint и включите надстройки по одной. Вам нужно будет проверить наличие проблем со звуком после включения каждой надстройки. Как только вы обнаружите проблемную надстройку, лучше удалить ее, чтобы избежать подобных проблем в будущем.
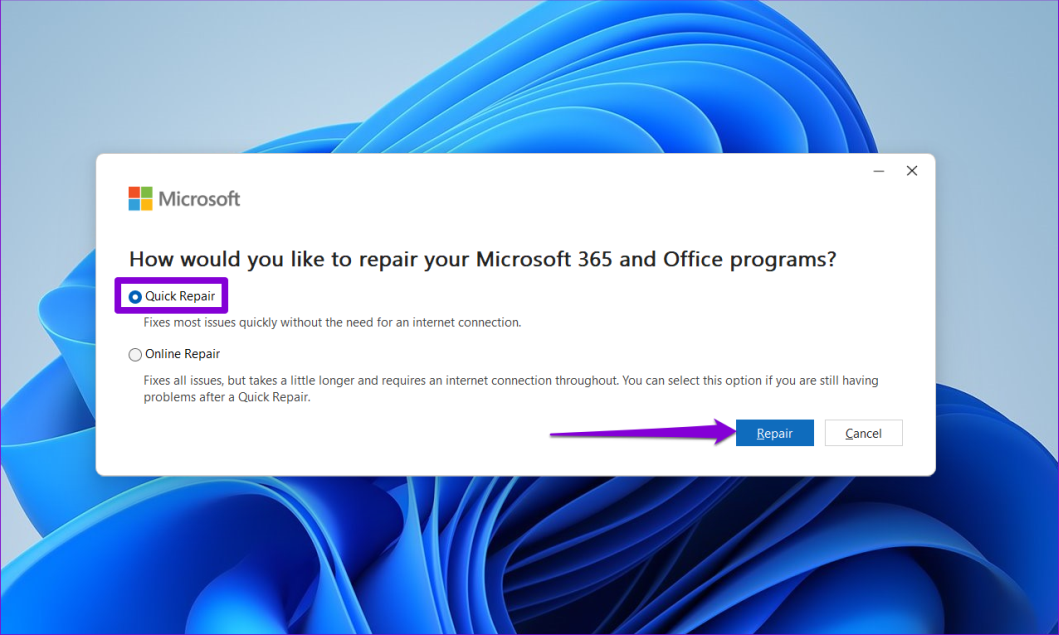
7. Запустите средство восстановления Office.
Если ничего не помогает, рассмотрите возможность запуска инструмента восстановления Office. Этот инструмент поможет вам устранить все проблемы с приложениями Office, такими как Word, Excel, PowerPoint и другими. Вот как его запустить.
Шаг 1. Нажмите сочетание клавиш Windows+R, чтобы открыть диалоговое окно «Выполнить». Введите appwiz.cpl в поле и нажмите Enter.
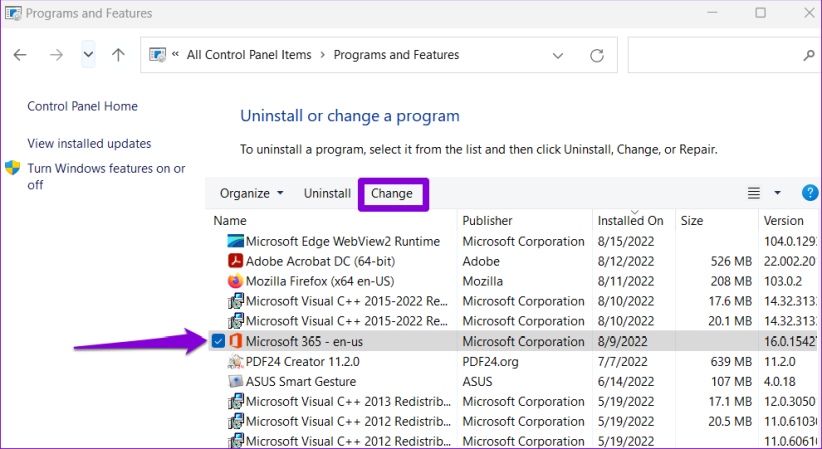
Шаг 2. В окне «Программы и компоненты» выберите пакет Office и нажмите кнопку «Изменить» вверху.
Шаг 3. Выберите вариант онлайн-восстановления и нажмите «Восстановить».
Включите звук в своих презентациях
Визуальные и звуковые элементы вашей презентации могут не привлечь чье-либо внимание, если PowerPoint не воспроизводит звук на вашем компьютере с Windows. Применение приведенных выше советов должно помочь вам решить проблему и оживить ваши презентации PowerPoint.
2024-01-11T14:12:21
Вопросы читателей
6 основных исправлений, когда мышь продолжает щелкать сама по себе в Windows 11
Мышь – важная часть вашего компьютера. Вы используете его для направления курсора и выполнения множества операций, включая нажатие, перетаскивание, прокрутку и т. д. Это отличная альтернатива использованию трекпада на ноутбуке. Однако, как и у всех технологий, у него могут иногда возникать проблемы. Фактически, многие пользователи жаловались на то, что их мышь щелкает сама по себе.
При возникновении этой проблемы вы можете случайно открыть приложения или выполнить действия, которые не планировали. В большинстве случаев данное явление может быть вызвано физическим повреждением мыши. Однако иногда это может быть связано с заражением вредоносным ПО, повреждением портов, конфликтом программного обеспечения или незначительными ошибками и сбоями. Решения, которые мы рассмотрим в этом руководстве, помогут вам эффективно устранить проблему.
1. Перезагрузите компьютер.
Прежде чем погружаться в сложные решения, стоит попробовать простую перезагрузку. Перезагрузка компьютера приведет к завершению работы всех запущенных процессов и служб. Это может эффективно устранить случайный щелчок мышью/случайный щелчок мышью, поскольку причиной проблемы может быть незначительная ошибка в некоторых запущенных процессах.
После перезагрузки компьютера проверьте, устранена ли проблема; если нет, вам следует ознакомиться с решениями, указанными ниже.
2. Проверьте мышь на наличие повреждений.
Проблема с неправильным щелчком также может быть связана с аппаратным обеспечением. В связи с этим это может быть вызвано повреждением в результате регулярного износа или физического воздействия, например падения. Вам следует провести физический осмотр и при этом обратить внимание на следующие моменты:
- Осмотрите кнопки на наличие трещин и ослаблений, нажимая каждую кнопку, чтобы проверить реакцию.
- Осмотрите колесо прокрутки мыши на наличие мусора. Возможно, вы захотите продуть через него сухой воздух.
- Внимательно осмотрите кабель на наличие порезов.
- Если он использует разъем USB, проверьте его на предмет погнутых контактов.
3. Переключите USB-порт.
Вышеупомянутые решения будут отличным решением, если проблема связана с мышью. Однако ваше компьютерное устройство также может иметь неисправные порты, что приводит к автоматическому щелчку мышью. Самый простой способ проверить наличие плохих портов — подключить мышь через другой порт или протестировать ее на другом компьютере.
Если порт неисправен, это может привести к случайному отключению и подключению USB-устройств, что приведет к возникновению проблемы.
4. Удалите устройство из диспетчера устройств.
Драйверы являются неотъемлемой частью вашего компьютера. Они помогают осуществлять связь между аппаратными устройствами, такими как мышь, и операционной системой. Неисправный драйвер мыши приведет к нестабильному поведению устройства. Возможно, вам придется удалить устройство, когда мышь щелкнет сама по себе.
После удаления драйвера вам следует выполнить следующие действия, чтобы заменить его новой, обновленной версией.
Шаг 1. Перезагрузите компьютер.
Шаг 2. Щелкните правой кнопкой мыши меню «Пуск» и выберите «Диспетчер устройств».
Шаг 3. Нажмите значок «Сканировать на предмет изменений оборудования».
5. Запустите сканирование на наличие вредоносных программ
Вредоносное ПО также может отрицательно повлиять на сенсорную панель ноутбука. Вредоносное ПО часто изменяет определенные файлы, что может вызвать проблемы со связью между вашим компьютером и некоторыми его жизненно важными компонентами. Поэтому мы рекомендуем запустить сканирование на наличие вредоносных программ с помощью встроенного приложения Windows Security.
Шаг 1. Откройте меню «Пуск», введите «Безопасность» и выберите приложение «Безопасность Windows».
Шаг 2. Нажмите «Защита от вирусов и угроз» на правой панели, затем слева нажмите «Параметры сканирования».
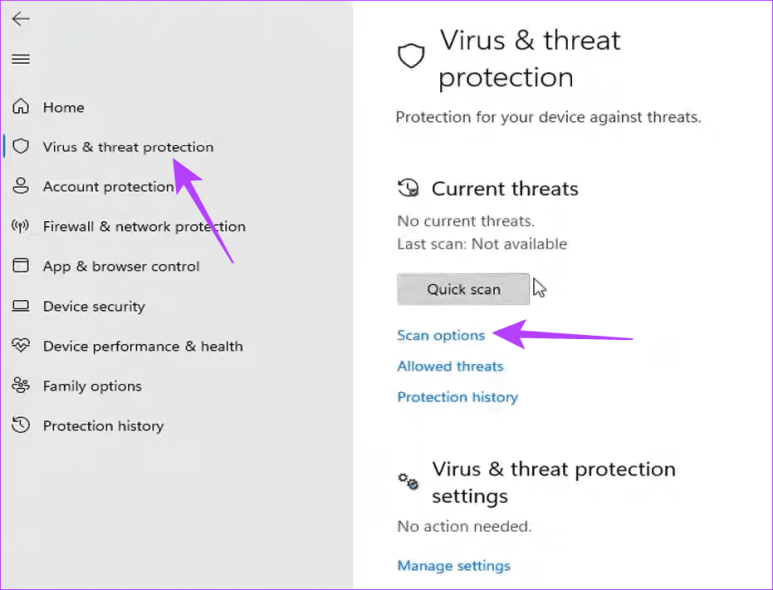
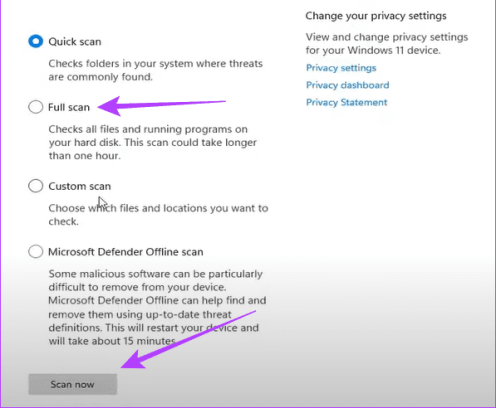
Шаг 3. Выберите «Полное сканирование», затем нажмите «Сканировать сейчас».
6. Чистая загрузка компьютера
Конфликтующие службы на вашем компьютере могут привести к самостоятельному щелчку мыши. Выполнив чистую загрузку устройства, вы заставите компьютер открываться только с ограниченным количеством служб или программ, тем самым устраняя любые конфликты, которые могут вызвать проблемы с мышью.
Шаг 1. Нажмите клавиши Windows+R на клавиатуре, чтобы открыть диалоговое окно «Выполнить».
Шаг 2. Введите msconfig и нажмите Enter на клавиатуре, чтобы открыть консоль служб.
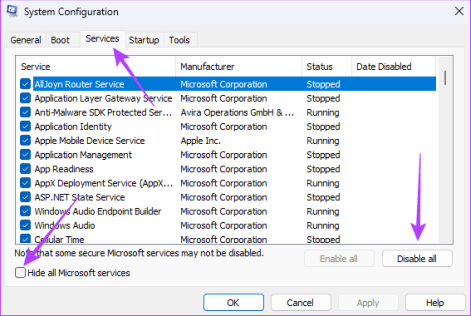
Шаг 3. Перейдите на вкладку «Службы», установите флажок «Скрыть все службы Microsoft» и нажмите кнопку «Отключить все».
Шаг 4. Перейдите на вкладку «Автозагрузка» и нажмите ссылку «Открыть диспетчер задач».
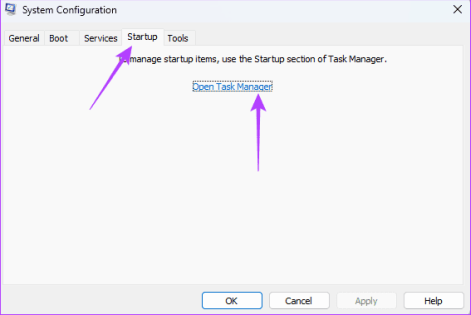
Шаг 5. Нажмите на запускаемое приложение (любое приложение со статусом «Включено»), затем нажмите кнопку «Отключено». Вы можете повторить этот процесс для любого количества запускаемых приложений, прежде чем закрывать диспетчер задач.
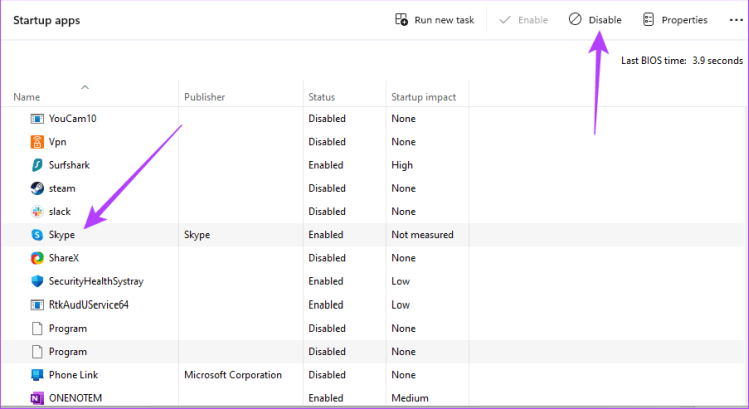
Шаг 6. Нажмите кнопки «Применить» и «ОК» в открытом окне конфигурации системы, затем перезагрузите компьютер.
Получите максимум от вашей мыши
Небольшие проблемы, такие как щелчок мышью сам по себе, могут затруднить использование компьютера и ухудшить удобство использования. Хотя в некоторых случаях требуется использование новой мыши, вы также можете воспользоваться приведенными выше решениями, чтобы устранить проблему с мышью. Это все, что касается этого руководства. Если у вас есть какие-либо вопросы, мы будем рады прочитать их в разделе комментариев ниже.
2024-01-11T14:03:58
Вопросы читателей
9 лучших способов исправить «Код ошибки Roblox 524» в Windows 11
Roblox — популярная бесплатная платформа, на которой имеется множество многопользовательских игр. Присоединиться к игровому серверу легко, но некоторые пользователи сталкиваются с кодом ошибки Roblox 524. Таким образом, они не могут пройти дальше экрана присоединения.
Мы обсудим возможные причины этого кода ошибки Roblox, а также девять способов его исправить и возобновить игру на вашем ПК с Windows.
Что означает код ошибки 524 в Roblox?
Код ошибки 524 в Roblox появляется при присоединении к серверу с сообщением «у вас нет разрешения на присоединение к этому опыту». Это означает, что не удалось подключиться к игровому серверу. Вот несколько возможных причин этого:
- Плохие проблемы с подключением к Интернету.
- Серверы Roblox временно не работают.
- Ваша учетная запись не имеет права присоединиться к игре.
- Заблокированный VPN-сервер.
- Ваш профиль Roblox не позволяет частным серверам добавлять вас в качестве участника.
1. Выполните базовое устранение неполадок в Интернете.
Прежде чем переходить к продвинутым методам, убедитесь, что у вас есть работающее подключение к Интернету. Откройте веб-браузер, зайдите в Интернет или откройте веб-приложение. Вы также можете перезагрузить маршрутизатор, чтобы очистить временный кэш и восстановить соединение с вашим интернет-провайдером.
2. Проверьте статус сервера Roblox.
Roblox — это игровой веб-сервис, и он может периодически отключаться. Итак, вы должны проверить официальную страницу состояния сервера Roblox, чтобы узнать о любых серьезных сбоях в работе и затронутых регионах.

В случае незначительных сбоев вы можете проверить сторонние веб-сайты, такие как DownDetector, или поискать недавние темы Reddit или X (ранее Twitter) о подобной проблеме. Терпеливо подождите, пока серверы снова станут активными, и повторите попытку подключения к игровому серверу.
3. Проверьте возраст своей учетной записи.
Некоторые игровые серверы запрещают присоединение к ним новых учетных записей. Вы можете проверить возраст своей учетной записи, просто проверив почтовый ящик адреса электронной почты, который вы использовали для регистрации в Roblox. Однако, если вы зарегистрировались без адреса электронной почты, вы можете использовать приложение, чтобы проверить, существует ли учетная запись менее 30 дней. Вот как:
Шаг 1: Нажмите клавишу Windows, чтобы открыть меню «Пуск». Введите Roblox в строке поиска и нажмите Enter, чтобы запустить приложение.
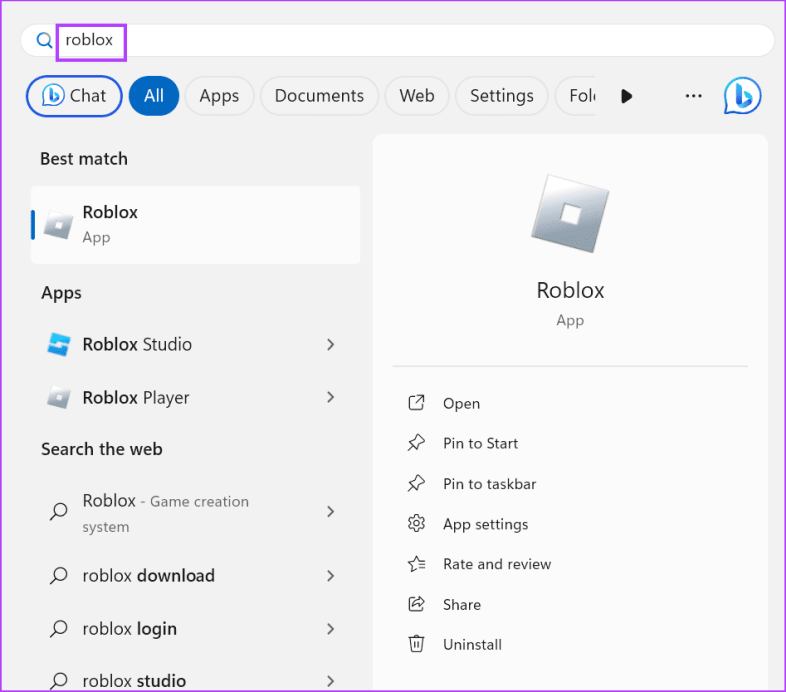
Шаг 2: Нажмите на значок профиля в правом верхнем углу. Затем нажмите на опцию «Просмотреть полный профиль».
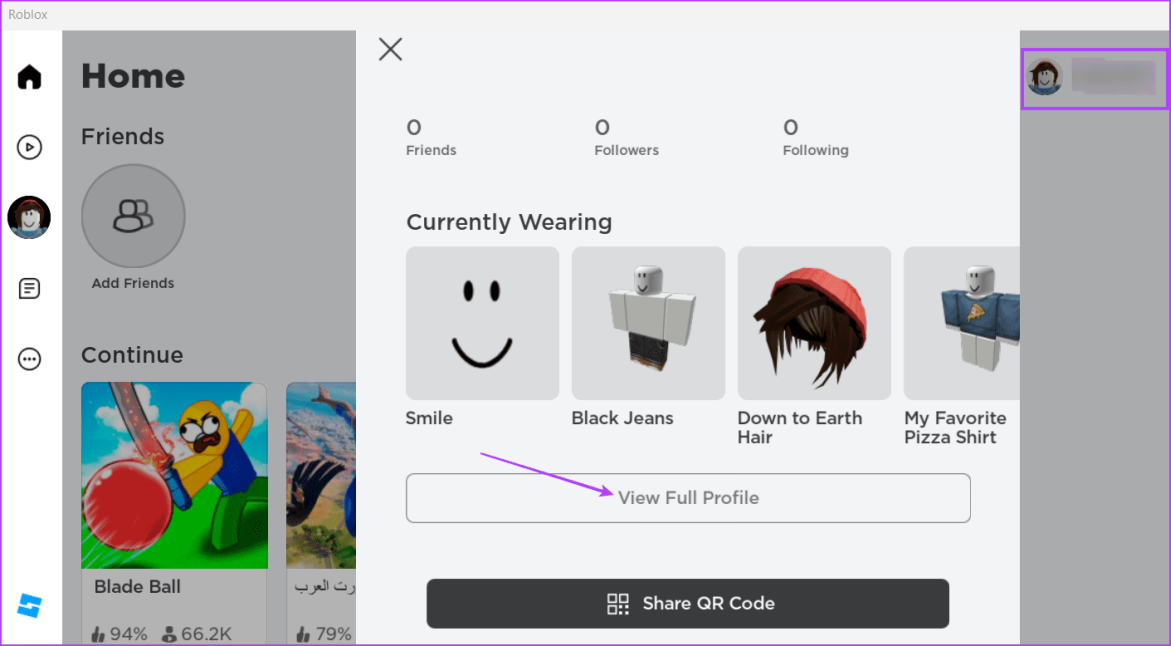
Шаг 3: Прокрутите вниз до раздела «Статистика». Здесь вы найдете дату, когда вы присоединились к Roblox.
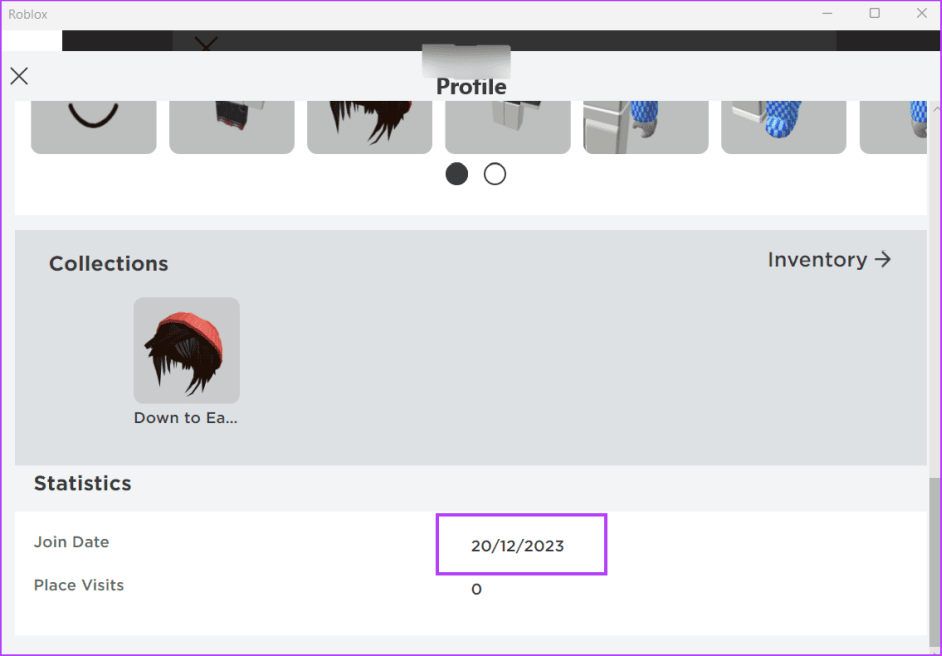
Если прошло менее 30 дней, вам необходимо дождаться, пока учетная запись преодолеет порог, а затем повторить попытку присоединиться к игре.
4. Разрешите частным серверам добавлять вас в качестве участника
Если ваша учетная запись Roblox не позволяет частным серверам добавлять вас в качестве участника, вы должны изменить ее, чтобы исправить код ошибки 524 в Roblox. Вот как изменить разрешение:
Шаг 1: Запустите приложение Roblox.
Шаг 2: Нажмите на значок трех точек в вертикальном меню слева.
Шаг 3: Теперь нажмите значок «Настройки».
Шаг 4: Нажмите на опцию «Конфиденциальность».
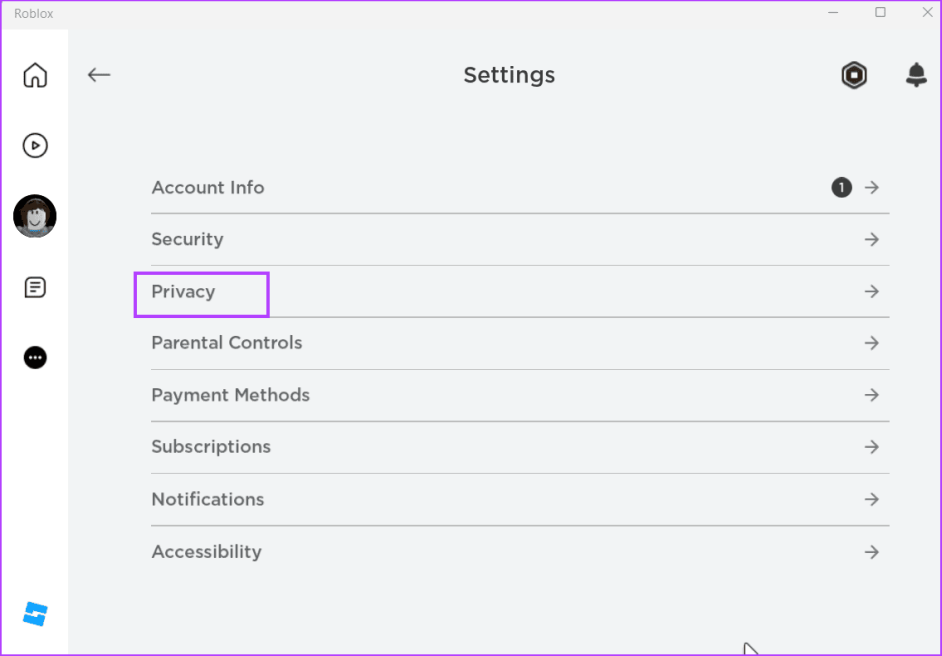
Шаг 5: Перейдите в раздел «Другие настройки». Нажмите на опцию «Кто может сделать меня участником своего частного сервера» и выберите «Все».
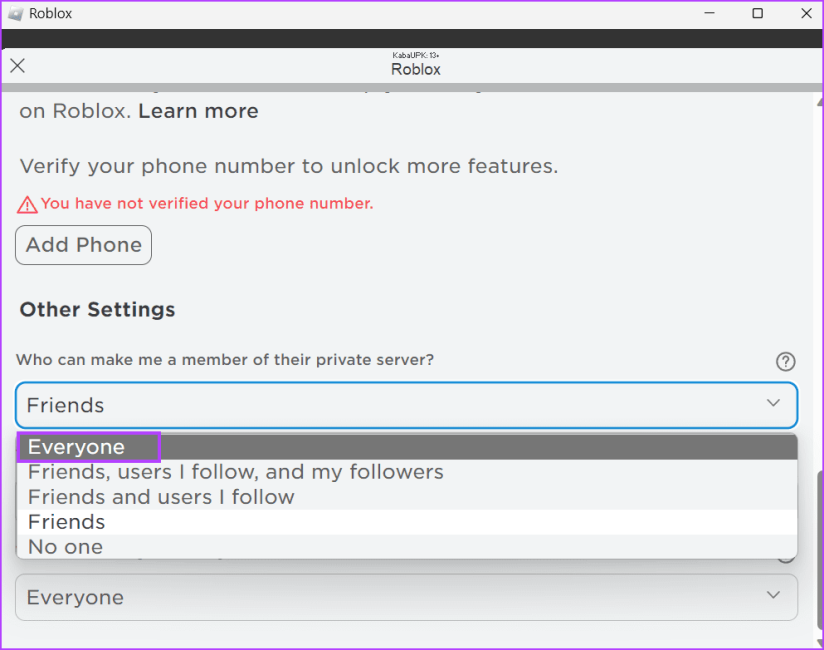
Шаг 6: Выйдите со страницы настроек и повторите попытку подключения к игре.
5. Попросите администратора отправить запрос на подключение.
Вы можете попросить администратора частного сервера добавить вас в список. Все, что им нужно, это ваше имя пользователя Roblox, чтобы пригласить вас через страницу настроек своего сервера. Вот как это сделать:
Шаг 1: Откройте приложение Roblox.
Шаг 2: Нажмите на значок профиля в правом верхнем углу. Затем нажмите на опцию «Просмотреть полный профиль».
Шаг 3: Перейдите на вкладку «Творения». Нажмите на значок игры.
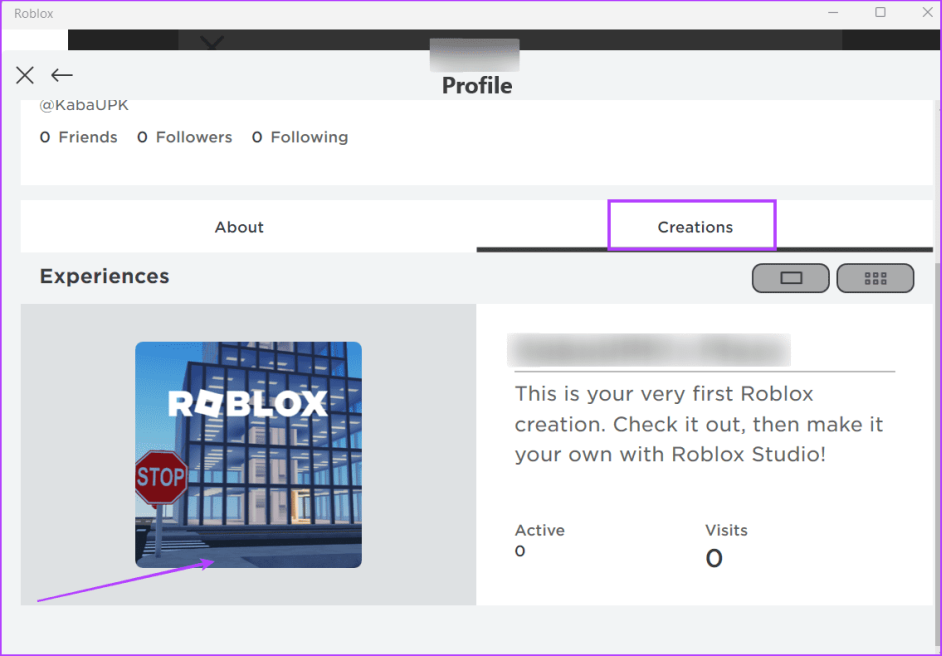
Шаг 4: Прокрутите вниз и выберите опцию «Серверы».
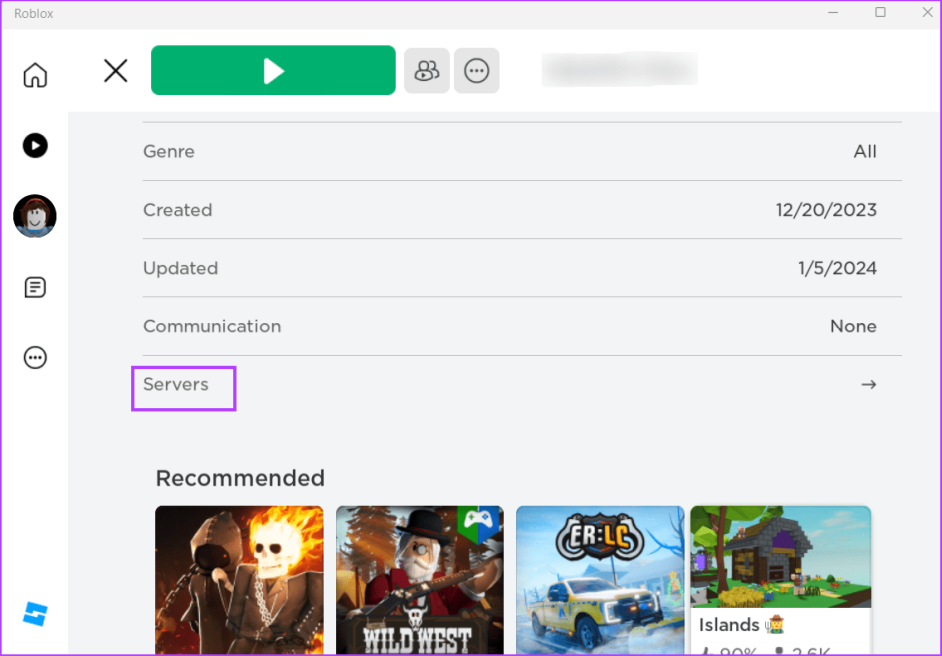
Шаг 5: Нажмите кнопку с тремя точками и выберите опцию «Настроить».
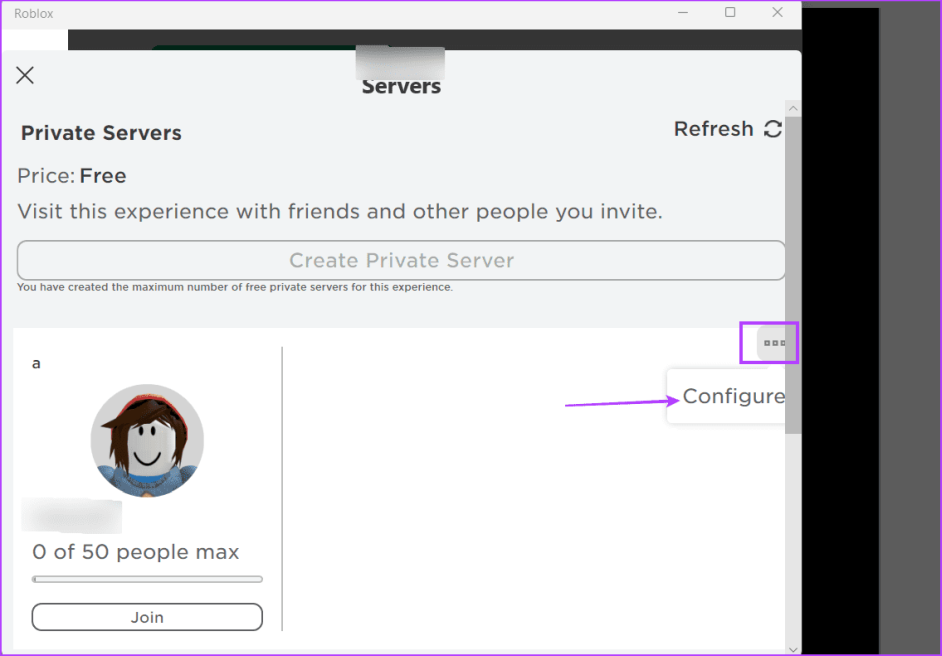
Шаг 6: Перейдите в раздел «Участники сервера» и щелкните значок «Добавить людей».
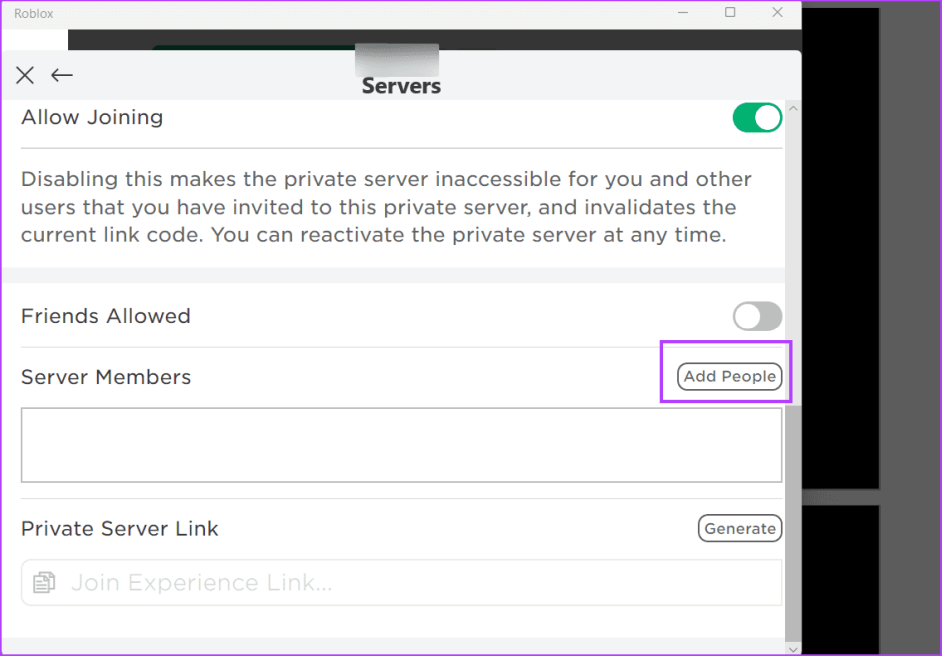
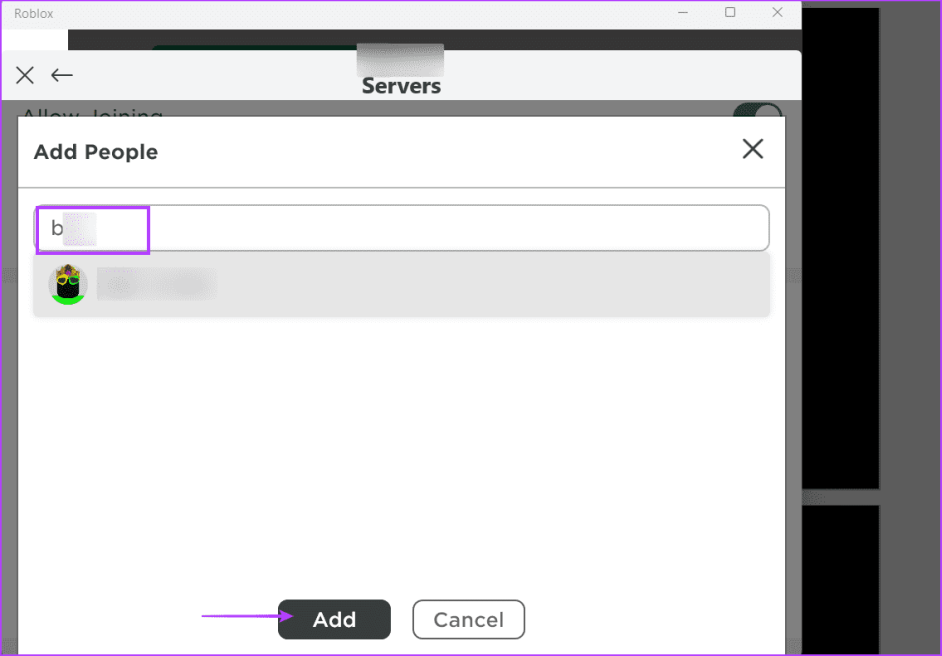
Шаг 7: Введите имя пользователя Roblox и нажмите кнопку «Добавить».
6. Отключите службу VPN.
Если вы используете VPN для подключения к Roblox и получаете код ошибки Roblox 524, попробуйте отключить VPN и использовать исходный IP-адрес для подключения к игровому серверу. Вот как это сделать:
Шаг 1. Перейдите в область значков на панели задач в правой части панели задач. Нажмите на значок стрелки.
Шаг 2: Щелкните правой кнопкой мыши значок VPN и выберите параметр «Отключить».
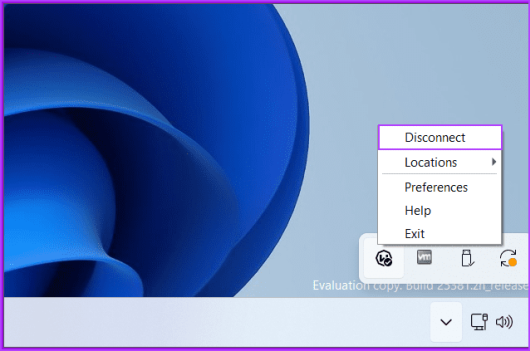
Шаг 3: Повторите попытку подключения к игре.
Если вы используете настройку VPN вручную, вам придется отключить ее с помощью приложения «Настройки».
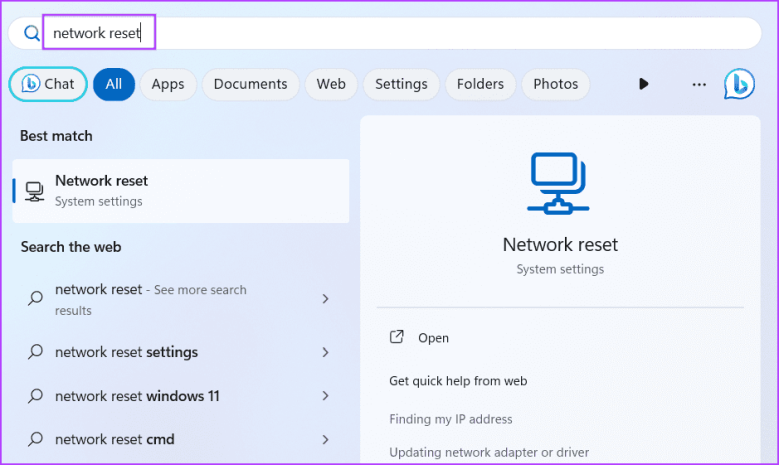
7. Сброс настроек сети.
Поврежденные настройки сети и проблемы с конфигурациями сетевых адаптеров могут вызвать проблемы с подключением в Roblox. Итак, вам необходимо сбросить сетевое соединение, чтобы восстановить настройки по умолчанию. После этого вам нужно будет настроить параметры Ethernet, Wi-Fi или VPN. Вот как:
Шаг 1: Нажмите клавишу Windows, чтобы открыть меню «Пуск». Введите сброс сети в поле поиска и нажмите Enter.
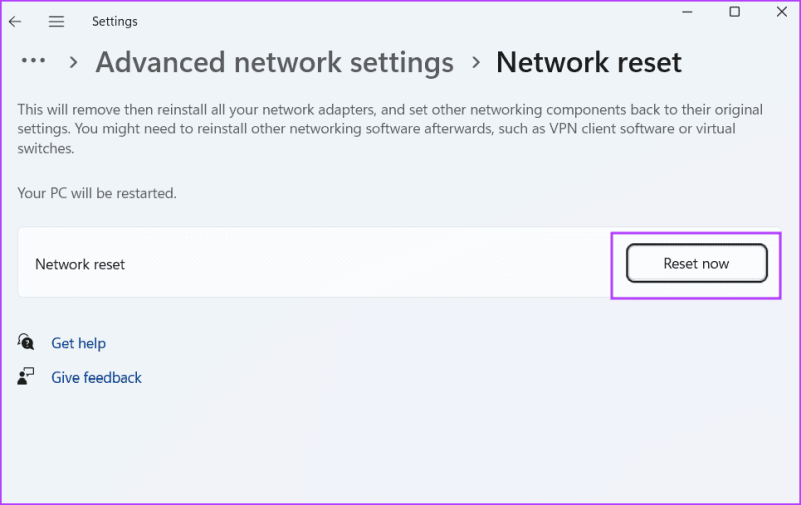
Шаг 2: Нажмите кнопку «Сбросить сейчас».
Шаг 3: Нажмите кнопку «Да», чтобы начать процесс.
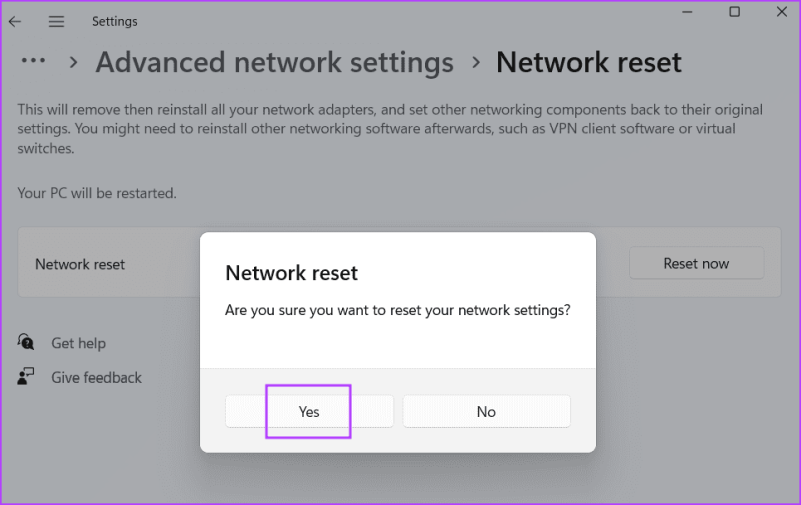
Ваш компьютер автоматически перезагрузится, чтобы применить изменения.
8. Восстановите или перезагрузите приложение Roblox.
Если вы используете версию приложения Roblox из Microsoft Store на своем ПК, вы можете восстановить или сбросить приложение, чтобы исправить повреждение файла. Вот как:
Шаг 1: Нажмите клавишу Windows, чтобы открыть меню «Пуск». Введите Roblox в поле поиска и нажмите кнопку «Настройки приложения».
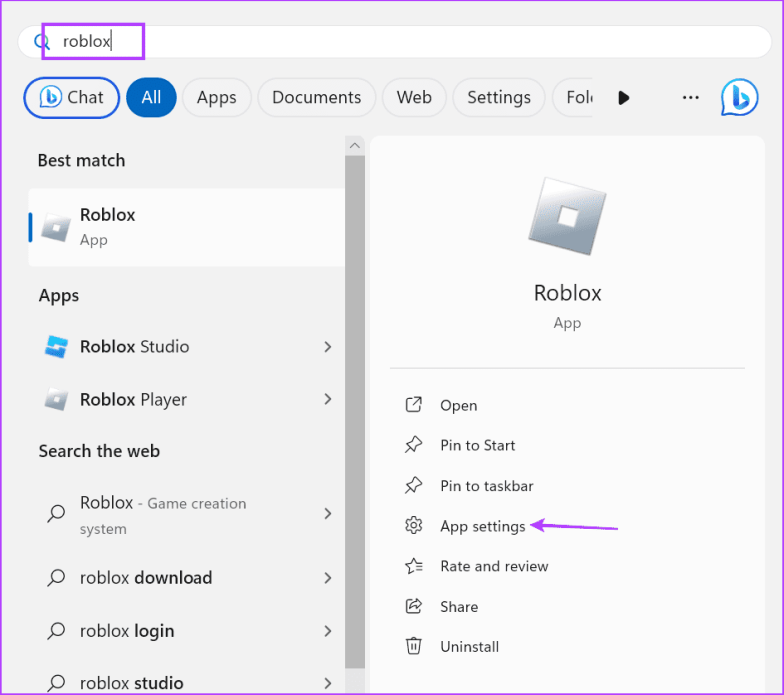
Шаг 2: Перейдите в раздел «Сброс». Нажмите кнопку «Восстановить».
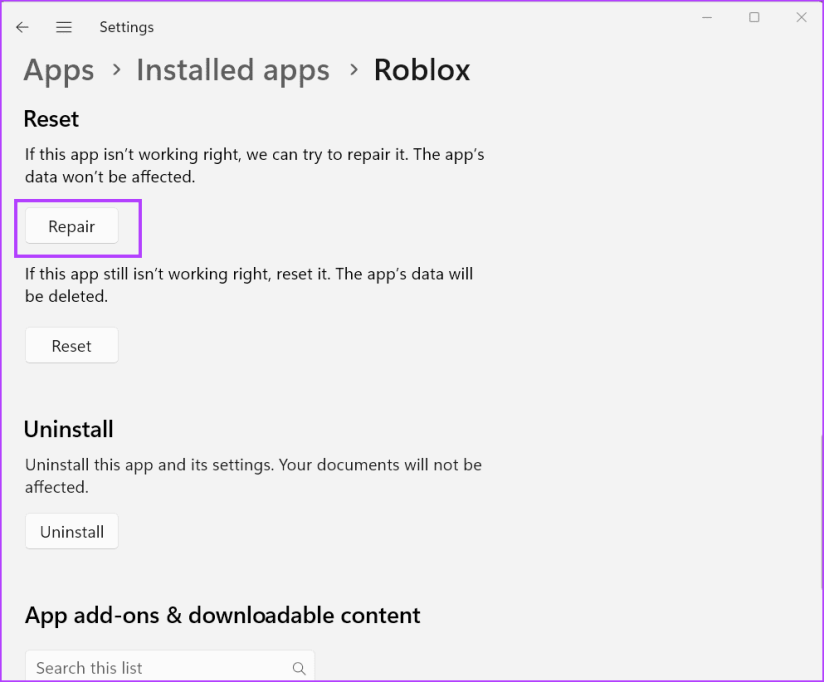
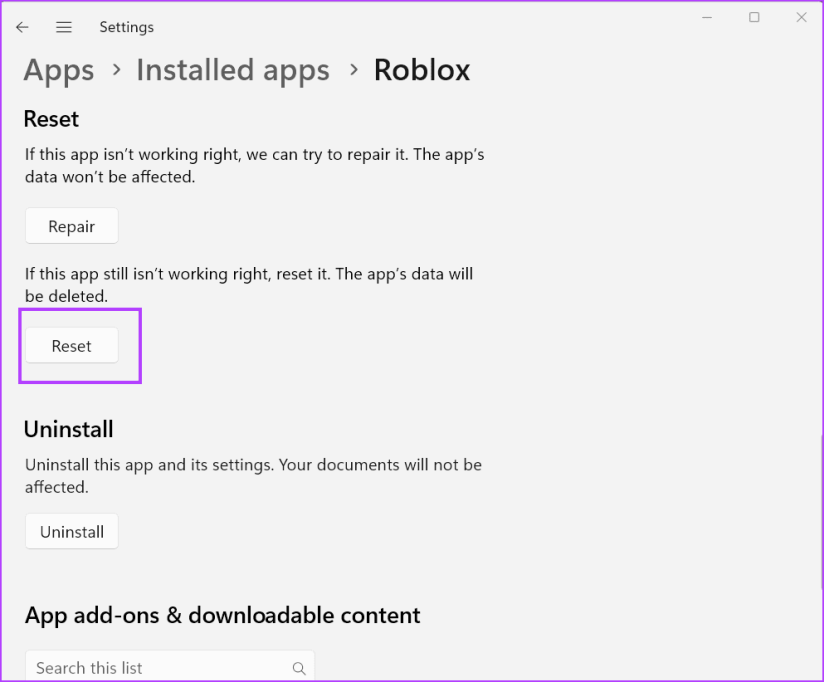
Шаг 3. Запустите Roblox, чтобы проверить, можете ли вы войти в игру без кода ошибки 524. Если нет, переключитесь в приложение «Настройки» и нажмите кнопку «Сброс».
9. Переустановите Роблокс
В крайнем случае — переустановить Roblox на свой компьютер. Он удалит текущую установку приложения вместе с ошибочными или поврежденными файлами с вашего компьютера. Вот как это сделать:
Шаг 1: Нажмите клавишу Windows, чтобы открыть меню «Пуск». Введите Roblox в поле поиска и нажмите «Удалить».
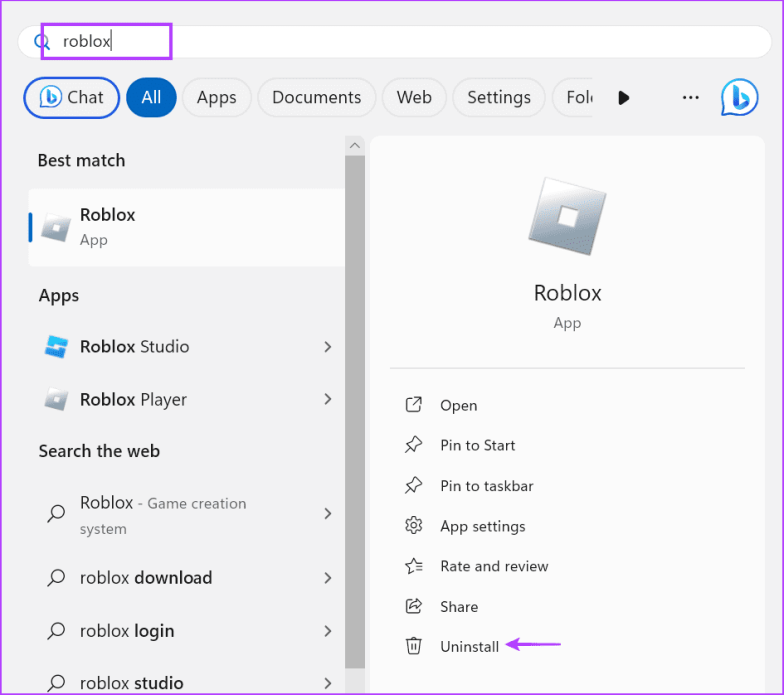
Шаг 2: Нажмите кнопку «Удалить», чтобы удалить приложение.
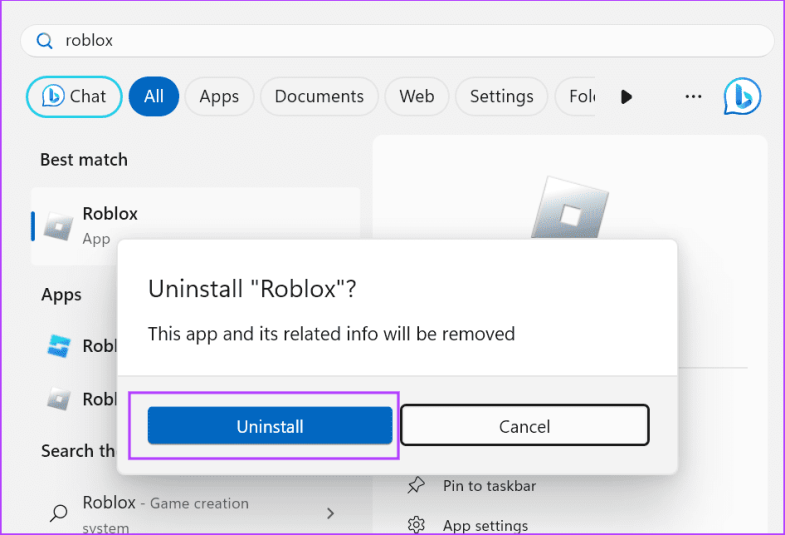
Шаг 3. Теперь запустите Microsoft Store и найдите приложение Roblox. Загрузите и установите последнюю версию. После этого войдите в свою учетную запись и проверьте, появляется ли код ошибки.
Исправьте надоедливые ошибки Roblox
Это были девять способов исправить код ошибки Roblox 524 в Windows 11. Обычно это возникает из-за проблем с сетью или неправильного профиля Roblox и настроек сервера. Обязательно обратитесь в службу поддержки Roblox, если вы по-прежнему не можете играть в игры.
2024-01-11T13:46:26
Вопросы читателей
7 способов исправить ошибку красного света на материнской плате
В сложном мире компьютерного оборудования материнская плата является основой вашей системы. Однако даже самые продвинутые и надежные материнские платы не застрахованы от периодических сбоев, и одним из самых страшных сигналов бедствия является появление красного индикатора. В этой статье мы покажем вам простые шаги, как исправить ошибку красного индикатора на материнской плате.
«Моя материнская плата сломалась?» Это может быть первый вопрос, который может возникнуть, когда вы увидите красный индикатор на материнской плате. Ответ — нет. Это не смерть, если на материнской плате горит красная лампочка, но все остальное работает нормально. Теперь давайте разберемся, что означает этот красный индикатор на вашей материнской плате.
Что такое красный свет на материнской плате
Прежде чем углубляться в руководство по устранению неполадок, начните с поиска таких меток, как CPU, DRAM, BOOT и VGA, рядом со светодиодами на материнской плате. Знание этих ярлыков облегчит определение источника любых проблем.

1. Индикатор процессора
Причины, по которым горит красный индикатор рядом с меткой ЦП:
- Устаревший BIOS
- Несовместимый процессор
- Неправильная установка процессора
- Неисправный процессор
- Проблемы с подключением
2. Свет DRAM
Возможные причины, по которым вы видите красный индикатор рядом с DRAM:
- Неправильно установлена ОЗУ
- Несовместимая оперативная память
- Зажимы RAM не закреплены
- Неисправная оперативная память
- Проблемы с контактами процессора
3. ЗАГРУЗОЧНЫЙ свет
Возможные причины горения индикатора BOOT:
- ОС не установлена
- Неправильно подключен HDD/SSD.
- Неисправный порт SATA
- Загрузка с незагрузочного диска
- Неисправный или поврежденный жесткий диск/SSD
- Проблемы с обнаружением BIOS
4. Световой разъем VGA
Вот почему может гореть красный индикатор рядом с VGA:
- Неправильные подключения графического процессора/блока питания.
- Незащищенная защелка разъема PCIe
- Неправильный слот графического процессора или повреждение
Как исправить ошибку красного света на материнской плате
Теперь, когда вы знаете, что означает красный индикатор на материнской плате, давайте выясним, как решить проблему.
1. Обеспечьте правильное подключение кабелей.
Кабели отвечают за питание, передачу данных и периферийные соединения. Ослабленные соединения или неправильное подключение кабелей могут привести к перебоям в подаче электроэнергии, сбоям в передаче данных и общей нестабильности, вызывая ошибку красного света.

Обеспечение правильного подключения кабелей имеет первостепенное значение при решении неприятной проблемы, связанной с ошибкой красного света на материнской плате. Вот как это можно сделать:
Шаг 1. Выключите компьютер и отсоедините его от основного источника питания.
Шаг 2. Проверьте все кабели, подключенные к материнской плате. Плотно подключите их и убедитесь, что они находятся в нужных местах.
Шаг 3. Отсоедините и снова подключите кабели, чтобы убедиться, что они плотно прилегают.
Шаг 4. Найдите поврежденные кабели и при необходимости замените их.
Шаг 5: Наконец, включите компьютер. Надеюсь, красный свет погас.
2. Замените неисправное оборудование.

Убедившись, что все кабели подключены правильно, вы можете осмотреть материнскую плату на предмет видимых признаков повреждений, таких как обгоревшие участки. Если вы обнаружите какой-либо неисправный компонент, например неисправный модуль оперативной памяти или поврежденную видеокарту, замените его новым.
Этот метод особенно эффективен, поскольку он непосредственно воздействует на источник проблемы, обеспечивая более постоянное решение по сравнению с программным устранением неполадок. Кроме того, решение аппаратных проблем способствует общей стабильности и надежности компьютерной системы, предотвращая будущие ошибки и обеспечивая бесперебойную работу.
3. Отключите и снова подключите периферийные устройства.

Если вы заметили красный индикатор на материнской плате без дисплея, систематическое отключение и повторное подключение всех внешних устройств, включая клавиатуру, мышь, внешние жесткие диски и видеокарту, может быстро исправить это. Это помогает обеспечить безопасные соединения и может решить проблему.
Примечание. Этот подход может не работать для всех ошибок «красного света», особенно тех, которые связаны с внутренними компонентами.
4. Проверьте или сбросьте настройки BIOS.
BIOS (базовая система ввода-вывода) — это важнейший компонент, который инициализирует оборудование во время процесса загрузки компьютера. Ошибки в настройках BIOS могут привести к нестабильности системы, а красный индикатор на материнской плате часто указывает на критическую проблему, требующую внимания.
Однако вы можете быстро решить эту проблему, проверив настройки BIOS на вашем устройстве. Для этого войдите в BIOS и вручную проверьте все настройки. Кроме того, обратите пристальное внимание на такие параметры, как частота процессора, тайминги оперативной памяти и конфигурации хранилища. Неправильные настройки в любой из этих областей могут вызвать ошибку красного света. Внесите необходимые изменения и убедитесь, что все конфигурации соответствуют характеристикам вашего оборудования.
Вы также можете сбросить настройки BIOS на своем устройстве. Вот как это делается:
Шаг 1. Нажмите Windows+S на клавиатуре, введите «Параметры восстановления» и нажмите «Открыть».

Шаг 2. Рядом с пунктом «Расширенный запуск» нажмите «Перезагрузить сейчас».
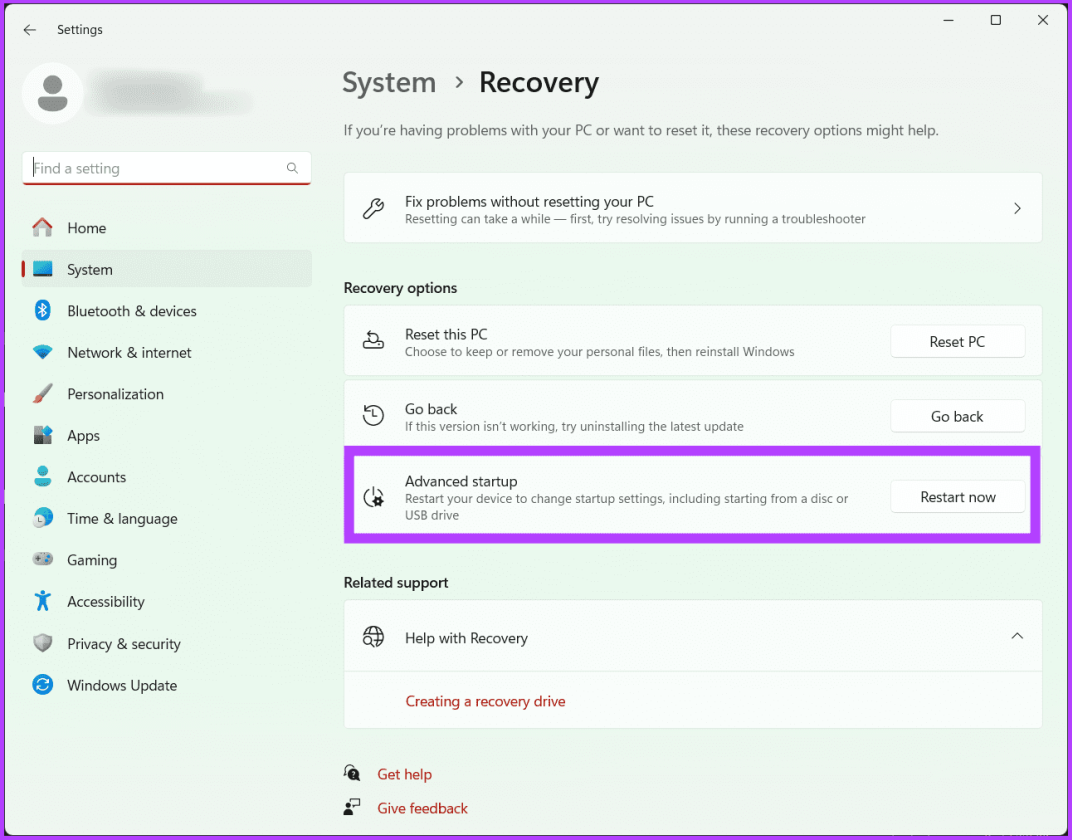
Шаг 3. Еще раз выберите «Перезагрузить сейчас» для подтверждения.
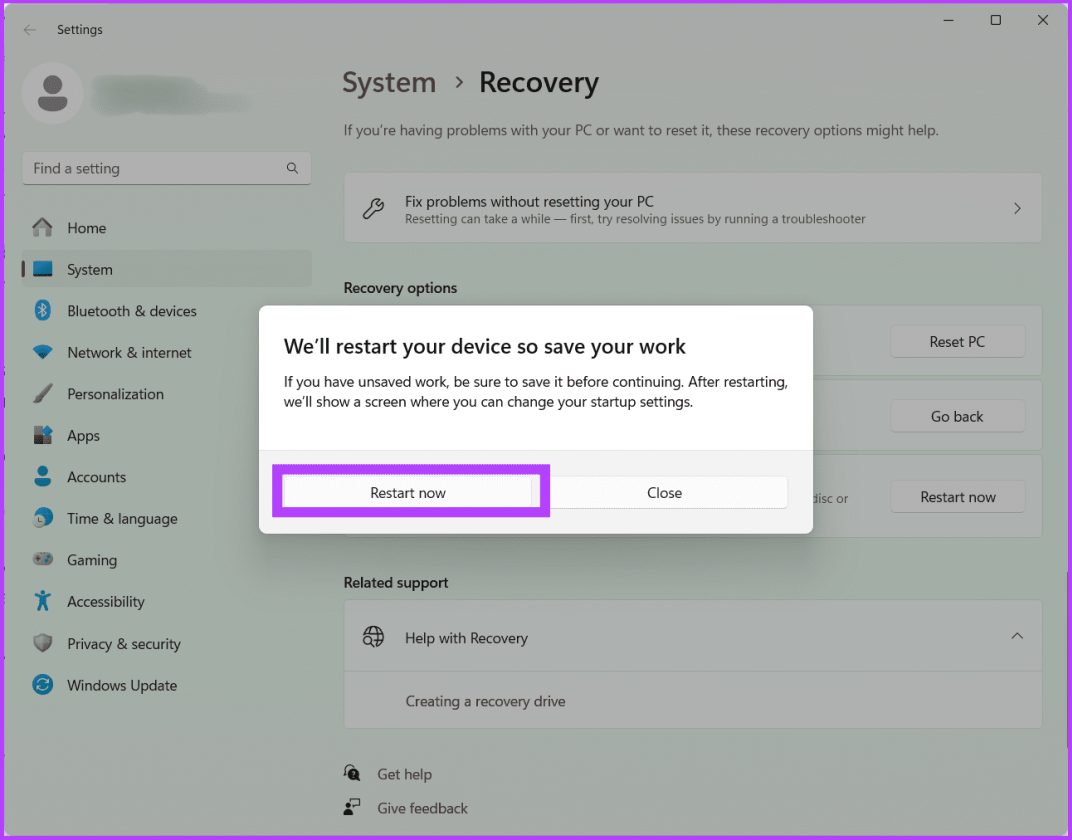
Шаг 4: Теперь ваш компьютер перезагрузится. После завершения выберите «Устранение неполадок».
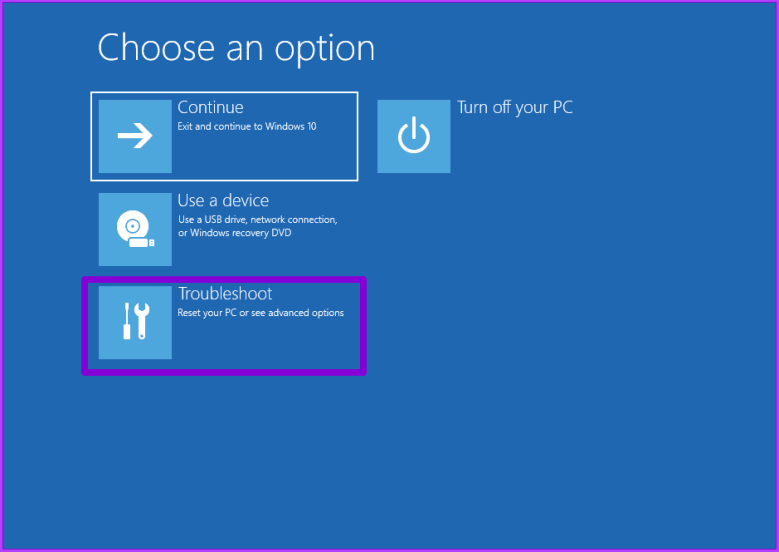
Шаг 5: Перейдите в Дополнительные параметры.
Шаг 6. Выберите «Настройки прошивки UEFI».
Шаг 7. Чтобы перезагрузить компьютер и получить доступ к экрану BIOS, нажмите кнопку «Перезагрузить».
Примечание. Экран BIOS может выглядеть по-разному на вашем компьютере в зависимости от вашей материнской платы.
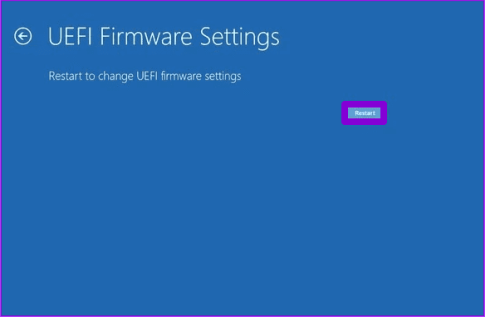
Шаг 8: Нажмите F9 на клавиатуре, чтобы выбрать «Настройка по умолчанию», и нажмите «Да».
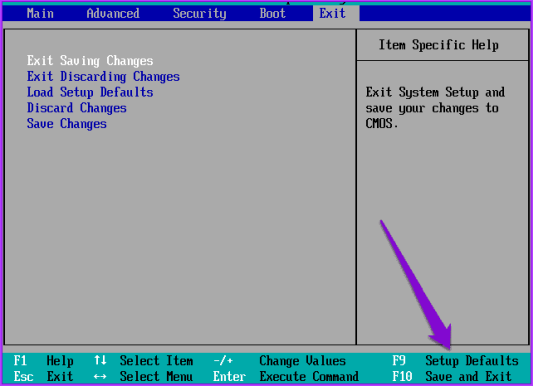
Шаг 9: Наконец, нажмите кнопку F10, чтобы выйти из экрана BIOS и сохранить изменения.
5. Оцените функциональность оперативной памяти и графического процессора.
Оценка функциональности оперативной памяти и графического процессора является эффективным решением, если вы видите красный свет на материнской плате без дисплея, поскольку эти компоненты являются неотъемлемой частью общей производительности и стабильности вашей системы. Если оперативная память или графический процессор неисправны, замена проблемного компонента на исправный может решить проблему.

Начать можно с проверки модулей оперативной памяти. Убедитесь, что они надежно вставлены в соответствующие разъемы DIMM. Если у вас несколько планок оперативной памяти, извлекайте их одну за другой, очищайте их тканью и снова вставляйте в слоты по одной, загружая систему после того, как вы вставите каждую планку обратно.
Если красный индикатор продолжает гореть, это может указывать на неисправность модуля ОЗУ. Рассмотрите возможность тестирования каждого модуля по отдельности или замены их заведомо исправными, чтобы определить, связана ли проблема с оперативной памятью.

Далее обратите внимание на графический процессор. Графический процессор играет решающую роль в отображении визуальной информации на дисплее. Убедитесь, что графический процессор правильно вставлен в слот PCI Express и что все дополнительные разъемы питания надежно подключены.
Если возможно, протестируйте систему с другим графическим процессором или встроенной графикой, чтобы увидеть, сохраняется ли ошибка красного света. Неисправный графический процессор может способствовать нестабильности системы и вызывать срабатывание индикаторов материнской платы. После этого проверьте, горит ли красный индикатор на материнской плате.
6. Сбросьте настройки и замените батарею CMOS.
CMOS (дополнительный металлооксидный полупроводник) — это важнейший компонент компьютерной системы, отвечающий за хранение настроек BIOS системы, включая информацию о конфигурации оборудования, дате и времени.

Батарея CMOS представляет собой небольшую батарейку типа «таблетка» на материнской плате, которая подает питание на микросхему CMOS, обеспечивая сохранение этих настроек даже при выключении компьютера. Когда батарея CMOS разряжена или настройки повреждены, это может привести к различным проблемам, включая ужасную ошибку красного индикатора на материнской плате.
Сброс CMOS включает сброс сохраненных настроек на чипе CMOS до значений по умолчанию. Этого можно добиться с помощью перемычки на материнской плате или извлечения и повторной установки батареи CMOS. При этом все поврежденные или конфликтующие настройки, вызывающие ошибку красного света, будут удалены, что позволит материнской плате запуститься с новой конфигурацией.

Со временем эти батареи могут потерять заряд, что приведет к нестабильному поведению и неисправностям. Когда батарея больше не может подавать достаточную мощность на CMOS-чип, это может привести к ошибке красного света. Установка новой батареи CMOS обеспечивает стабильное питание микросхемы CMOS, предотвращая повторение ошибок, связанных с недостаточным питанием.
7. Подумайте о покупке новой материнской платы.

Если вы попробовали все вышеперечисленные исправления, но ошибка красного индикатора на вашей материнской плате не устранена, переход на новую материнскую плату может быть комплексным решением. Новые материнские платы обеспечивают совместимость с современными компонентами и функциями, улучшенную подачу питания и повышенную стабильность. Кроме того, они поставляются с обновленным BIOS и прошивкой для лучшей совместимости оборудования, что потенциально обеспечивает более плавную работу и помогает устранить проблему.
Верните свой компьютер
Многие современные материнские платы имеют четкие этикетки, по которым легко определить, почему горит красный индикатор. Даже если у вас нет меток, простые действия, такие как настройка компонентов и проверка соединений, могут вернуть компьютеру работоспособность. Мы надеемся, что описанные выше действия помогли вам исправить красный индикатор на материнской плате.
2024-01-11T13:32:00
Вопросы читателей
Создание расширенного внешнего интерфейса для Docker контейнера
Docker — это открытая платформа для автоматизации разработки, доставки и запуска приложений в контейнерах. Она позволяет разработчикам развернуть и запускать свои приложения с минимальными затратами времени и ресурсов. В Docker контейнерах можно упаковать приложения вместе со всеми зависимостями, что позволяет их легко развернуть и запустить на любом компьютере, поддерживающем Docker.
Однако, стандартный внешний интерфейс Docker-контейнера не всегда удовлетворяет требованиям разработчиков и системных администраторов. В таких случаях может потребоваться создание расширенного внешнего интерфейса, который бы обеспечивал более удобное и эффективное взаимодействие с Docker-контейнером.
Расширенный внешний интерфейс для Docker контейнера позволяет добавить дополнительные функциональные возможности и упрощает управление контейнером. С его помощью можно, например, отображать статус контейнера, мониторить ресурсы, управлять сетевыми настройками, настраивать автоматическую масштабирование и т.д. Создание такого интерфейса позволяет значительно упростить работу с Docker-контейнером и повысить его эффективность в конкретной задаче.
Дизайн интерфейса Docker контейнера
В данном разделе мы рассмотрим основные принципы и рекомендации по дизайну внешнего интерфейса Docker контейнера. Грамотный дизайн поможет сделать пользовательский опыт более комфортным и удобным.
При разработке дизайна интерфейса Docker контейнера важно учесть следующие аспекты:
- Простота использования: интерфейс должен быть интуитивно понятным и легким для использования, чтобы пользователи могли быстро освоить основные функции контейнера.
- Визуальная консистентность: все элементы интерфейса должны выглядеть состыкованными и согласованными, чтобы создать единое и целостное впечатление.
- Привлекательность и эстетика: дизайн должен быть привлекательным и приятным визуально, чтобы привлечь и удержать внимание пользователей.
- Гибкость и адаптивность: интерфейс должен быть гибким и адаптивным, чтобы корректно отображаться на различных устройствах и экранах разных размеров.
- Ясное отображение информации: информация должна быть представлена наглядно и понятно, чтобы пользователи могли быстро получить нужные им данные.
Наиболее распространенными элементами интерфейса Docker контейнера являются таблицы и списки.
| Название контейнера | Статус | Изображение |
|---|---|---|
| web-server | Запущен | nginx:latest |
| database | Остановлен | mysql:latest |
| app | Остановлен | node:latest |
Таблица представляет основную информацию о контейнерах, такую как их название, статус и используемое изображение. Пользователь может сортировать и фильтровать таблицу по различным параметрам для удобства работы с контейнерами.
Списки также являются важным элементом интерфейса Docker контейнера. С их помощью можно представлять информацию о файловой системе контейнера, доступных сетевых интерфейсах и прочих ресурсах.
- Файлы контейнера: список файлов и директорий внутри контейнера, к которым можно получить доступ.
- Сетевые интерфейсы: список сетевых интерфейсов контейнера и их свойств, таких как IP-адрес и состояние.
- Ресурсы: список доступных ресурсов, таких как CPU, память и дисковое пространство, с возможностью отображения их текущей загрузки.
Выбор типа интерфейса
При создании расширенного внешнего интерфейса для Docker контейнера необходимо определиться с выбором типа интерфейса. В зависимости от конкретных требований проекта и целевой аудитории можно выбрать различные варианты интерфейса.
Следует учитывать, что основная цель создания расширенного внешнего интерфейса – упростить использование Docker контейнера и улучшить пользовательский опыт. Поэтому интерфейс должен быть интуитивно понятным, удобным в использовании и эффективным для выполнения нужных задач.
Определение типа интерфейса можно начать с анализа предполагаемых пользовательских операций. Если контейнер предназначен для работы с данными, то может быть полезно рассмотреть возможность создания таблицы с данными, фильтрации и сортировки данных.
Если контейнер используется для запуска и управления приложениями, то интерфейс может содержать список доступных приложений, возможности управления запущенными приложениями, а также логирование и мониторинг работы приложений.
Графический интерфейс пользователя
Графический интерфейс пользователя (GUI) позволяет взаимодействовать с приложением с помощью визуальных элементов, таких как кнопки, окна, поля ввода и т. д. Создание графического интерфейса для Docker контейнера позволяет упростить использование и настройку контейнеров для пользователей без опыта работы с командной строкой.
Существует несколько способов создания графического интерфейса пользователя для Docker контейнера. Один из них – использование графических инструментов управления контейнерами, таких как Portainer или Shipyard. Эти инструменты предоставляют веб-интерфейс, с помощью которого можно просматривать и управлять контейнерами, создавать новые контейнеры, масштабировать приложения и многое другое.
Еще один способ создания графического интерфейса пользователя – разработка собственного веб-приложения для управления контейнерами. С помощью популярных фреймворков, таких как React или Angular, можно создать интерфейс, позволяющий пользователям запускать, останавливать, масштабировать и управлять параметрами Docker контейнеров.
- Веб-интерфейс для управления контейнерами
- Создание собственного веб-приложения
Веб-интерфейс для управления контейнерами – простой и удобный способ взаимодействия с Docker контейнерами без использования командной строки. Он позволяет просматривать список активных контейнеров, запускать новые контейнеры из образов, настраивать параметры контейнеров (порты, переменные окружения и т. д.), а также масштабировать приложения при необходимости.
Создание собственного веб-приложения для управления контейнерами предоставляет больше свободы в настройке и функционале. Вы можете разработать интерфейс, учитывающий особенности вашего приложения и ваших потребностей. Например, вы можете добавить функционал для автоматического масштабирования контейнеров в зависимости от нагрузки или добавить интеграцию с другими сервисами.
| Преимущества веб-интерфейсов | Преимущества собственных веб-приложений |
|---|---|
|
|
Вопрос-ответ:
Какие преимущества расширенного внешнего интерфейса для Docker контейнера?
Расширенный внешний интерфейс для Docker контейнера предоставляет дополнительные возможности для взаимодействия с контейнером и управления им. Это позволяет легко масштабировать контейнеры, настраивать сетевое взаимодействие и добавлять другие внешние сервисы.
Как можно создать расширенный внешний интерфейс для Docker контейнера?
Создание расширенного внешнего интерфейса для Docker контейнера можно осуществить с помощью связки Docker Compose и Docker Network. Для этого необходимо создать и настроить файл docker-compose.yml, в котором определить сеть для контейнеров и указать нужные параметры.
Как создать расширенный внешний интерфейс для Docker контейнера?
Для создания расширенного внешнего интерфейса для Docker контейнера, вы можете использовать команду “docker network create” с указанием драйвера сети и дополнительных параметров, например, “–subnet” и “–gateway”. Это позволит вам настроить необходимые сетевые параметры для контейнера.
Видео:
Docker – Полный курс Docker Для Начинающих [3 ЧАСА]
Docker – Полный курс Docker Для Начинающих [3 ЧАСА] by Bogdan Stashchuk 1 year ago 3 hours, 1 minute 388,541 views
Уроки Docker для начинающих / #7 – Docker Volumes
Уроки Docker для начинающих / #7 – Docker Volumes by Гоша Дударь 1 year ago 27 minutes 40,985 views
Сообщение Создание расширенного внешнего интерфейса для Docker контейнера появились сначала на Программирование на Python.