Kubernetes позволяет автоматически масштабировать приложения (то есть Pod в развертывании или ReplicaSet) декларативным образом с использованием спецификации Horizontal Pod Autoscaler.
По умолчанию критерий для автоматического масштабирования — метрики использования CPU (метрики ресурсов), но можно интегрировать пользовательские метрики и метрики, предоставляемые извне.
Вместо горизонтального автомасштабирования подов, применяется Kubernetes Event Driven Autoscaling (KEDA) — оператор Kubernetes с открытым исходным кодом. Он изначально интегрируется с Horizontal Pod Autoscaler, чтобы обеспечить плавное автомасштабирование (в том числе до/от нуля) для управляемых событиями рабочих нагрузок. Код доступен на GitHub.
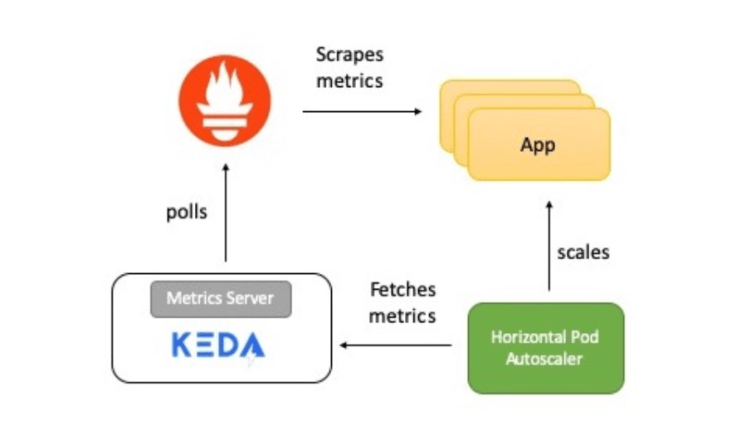
Краткий обзор работы системы
На схеме — краткое описание того, как все работает:
- Приложение предоставляет метрики количества обращений к HTTP в формате Prometheus.
- Prometheus настроен на сбор этих показателей.
- Скейлер Prometheus в KEDA настроен на автоматическое масштабирование приложения на основе количества обращений к HTTP.
Теперь подробно расскажу о каждом элементе.
KEDA и Prometheus
Prometheus — набор инструментов для мониторинга и оповещения систем с открытым исходным кодом, часть Cloud Native Computing Foundation. Собирает метрики из разных источников и сохраняет в виде данных временных рядов. Для визуализации данных можно использовать Grafana или другие инструменты визуализации, работающие с API Kubernetes.
KEDA поддерживает концепцию скейлера — он действует как мост между KEDA и внешней системой. Реализация скейлера специфична для каждой целевой системы и извлекает из нее данные. Затем KEDA использует их для управления автоматическим масштабированием.
Скейлеры поддерживают нескольких источников данных, например, Kafka, Redis, Prometheus. То есть KEDA можно применять для автоматического масштабирования развертываний Kubernetes, используя в качестве критериев метрики Prometheus.
KEDA Prometheus ScaledObject
Скейлер действует как мост между KEDA и внешней системой, из которой нужно получать метрики. ScaledObject — настраиваемый ресурс, его необходимо развернуть для синхронизации развертывания с источником событий, в данном случае с Prometheus.
ScaledObject содержит информацию о масштабировании развертывания, метаданные об источнике события (например, секреты для подключения, имя очереди), интервал опроса, период восстановления и другие данные. Он приводит к соответствующему ресурсу автомасштабирования (определение HPA) для масштабирования развертывания.
Когда объект ScaledObject удаляется, соответствующее ему определение HPA очищается.
Вот определение ScaledObject для нашего примера, в нем используется скейлер Prometheus:
apiVersion: keda.k8s.io/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: default
labels:
deploymentName: go-prom-app
spec:
scaleTargetRef:
deploymentName: go-prom-app
pollingInterval: 15
cooldownPeriod: 30
minReplicaCount: 1
maxReplicaCount: 10
triggers:
- type: prometheus
metadata:
serverAddress:
http://prometheus-service.default.svc.cluster.local:9090
metricName: access_frequency
threshold: '3'
query: sum(rate(http_requests[2m]))
Учтите следующие моменты:
- Он указывает на Deployment с именем go-prom-app.
- Тип триггера — Prometheus. Адрес сервера Prometheus упоминается вместе с именем метрики, пороговым значением и запросом PromQL, который будет использоваться. Запрос PromQL — sum(rate(http_requests[2m])).
- Согласно pollingInterval, KEDA запрашивает цель у Prometheus каждые пятнадцать секунд. Поддерживается минимум один под (minReplicaCount), а максимальное количество подов не превышает maxReplicaCount (в данном примере — десять).
Можно установить minReplicaCount равным нулю. В этом случае KEDA активирует развертывание с нуля до единицы, а затем предоставляет HPA для дальнейшего автоматического масштабирования. Возможен и обратный порядок, то есть масштабирование от единицы до нуля. В примере мы не выбрали ноль, поскольку это HTTP-сервис, а не система по запросу.
Магия внутри автомасштабирования
Пороговое значение используют в качестве триггера для масштабирования развертывания. В нашем примере запрос PromQL sum(rate (http_requests [2m])) возвращает агрегированное значение скорости HTTP-запросов (количество запросов в секунду), ее измеряют за последние две минуты.
Поскольку пороговое значение равно трем, значит, будет один под, пока значение sum(rate (http_requests [2m])) меньше трех. Если же значение возрастает, добавляется дополнительный под каждый раз, когда sum(rate (http_requests [2m])) увеличивается на три. Например, если значение от 12 до 14, то количество подов — четыре.
Теперь давайте попробуем настроить!
Установка KEDA
Вы можете развернуть KEDA несколькими способами, они перечислены в документации. Я использую монолитный YAML:
[root@kub-master-1 ~]# wget https://github.com/kedacore/keda/releases/download/v2.1.0/keda-2.1.0.yaml
[root@kub-master-1 ~]# kubectl apply -f keda-2.1.0.yaml
ну или можно установить через helm
helm repo add kedacore https://kedacore.github.io/charts
helm repo update
kubectl create namespace keda
helm install keda kedacore/keda —namespace keda
я ставил через монолитный файл.
проверим что всё поднялось:
[root@kub-master-1 ~]# kubectl get all -n keda
NAME READY STATUS RESTARTS AGE
pod/keda-metrics-apiserver-57cbdb849f-w7rfg 1/1 Running 0 70m
pod/keda-operator-58cb545446-5rblj 1/1 Running 0 70m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/keda-metrics-apiserver ClusterIP 10.100.134.31 <none> 443/TCP,80/TCP 70m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/keda-metrics-apiserver 1/1 1 1 70m
deployment.apps/keda-operator 1/1 1 1 70m
NAME DESIRED CURRENT READY AGE
replicaset.apps/keda-metrics-apiserver-57cbdb849f 1 1 1 70m
replicaset.apps/keda-operator-58cb545446 1 1 1 70m
3. Пример работы
создаём namespace
kubectl create ns my-site
запускаем обычное приложение например apache:
[root@kub-master-1 ~]# cat my-site.yaml
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-deployment-apache
namespace: my-site
spec:
replicas: 1
selector:
matchLabels:
app: apache # по вот этому лейблу репликасет цепляет под
# тут описывается каким мокаром следует обновлять поды
strategy:
rollingUpdate:
maxSurge: 1 # указывает на какое количество реплик можно увеличить
maxUnavailable: 1 # указывает на какое количество реплик можно уменьшить
#т.е. в одно время при обновлении, будет увеличено на один (новый под) и уменьшено на один (старый под)
type: RollingUpdate
## тут начинается описание контейнера
template:
metadata:
labels:
app: apache # по вот этому лейблу репликасет цепляет под
spec:
containers:
- image: httpd:2.4.43
name: apache
ports:
- containerPort: 80
# тут начинаются проверки по доступности
readinessProbe: # проверка готово ли приложение
failureThreshold: 3 #указывает количество провалов при проверке
httpGet: # по сути дёргает курлом на 80 порт
path: /
port: 80
periodSeconds: 10 #как часто должна проходить проверка (в секундах)
successThreshold: 1 #сбрасывает счётчик неудач, т.е. при 3х проверках если 1 раз успешно прошло, то счётчик сбрасывается и всё ок
timeoutSeconds: 1 #таймаут на выполнение пробы 1 секунда
livenessProbe: #проверка на жизнь приложения, живо ли оно
failureThreshold: 3
httpGet:
path: /
port: 80
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
initialDelaySeconds: 10 #означает что первую проверку надо сделать только после 10 секунд
# тут начинается описание лимитов для пода
resources:
requests: #количество ресурсов которые резервируются для pod на ноде
cpu: 60m
memory: 200Mi
limits: #количество ресурсов которые pod может использовать(верхняя граница)
cpu: 120m
memory: 300Mi
[root@kub-master-1 ~]# cat my-site-service.yaml
---
apiVersion: v1
kind: Service
metadata:
name: my-service-apache # имя сервиса
namespace: my-site
spec:
ports:
- port: 80 # принимать на 80
targetPort: 80 # отправлять на 80
selector:
app: apache #отправлять на все поды с данным лейблом
type: ClusterIP
[root@kub-master-1 ~]# cat my-site-ingress.yaml
---
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: my-ingress
namespace: my-site
spec:
rules:
- host: test.ru #тут указывается наш домен
http:
paths: #список путей которые хотим обслуживать(он дефолтный и все запросы будут отпаврляться на бэкенд, т.е. на сервис my-service-apache)
- backend:
serviceName: my-service-apache #тут указывается наш сервис
servicePort: 80 #порт на котором сервис слушает
# path: / все запросы на корень '/' будут уходить на наш сервис
применяем:
[root@kub-master-1 ~]# kubectl apply -f my-site.yaml -f my-site-service.yaml -f my-site-ingress.yaml
проверяем:
[root@kub-worker-1 ~]# curl test.ru
<html><body><h1>It works!</h1></body></html>
[root@kub-master-1 ~]# kubectl get all -n my-site
NAME READY STATUS RESTARTS AGE
pod/my-deployment-apache-859486bd8c-k6bql 1/1 Running 0 20m
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-service-apache ClusterIP 10.100.255.190 <none> 80/TCP 20m
NAME READY UP-TO-DATE AVAILABLE AGE
deployment.apps/my-deployment-apache 1/1 1 1 20m
NAME DESIRED CURRENT READY AGE
replicaset.apps/my-deployment-apache-859486bd8c 1 1 1 20m
будем автоскейлить — для примера по метрике nginx nginx_ingress_controller_requests
запрос в prometheus будет следующий:
sum(irate( nginx_ingress_controller_requests{namespace=»my-site»}[3m] )) by (ingress)*10
т.е. считаем общее количество запросов в неймспейс my-site за 3 минуты
создаём keda сущность:
[root@kub-master-1 ~]# cat hpa-keda.yaml
apiVersion: keda.sh/v1alpha1
kind: ScaledObject
metadata:
name: prometheus-scaledobject
namespace: my-site
spec:
scaleTargetRef:
name: my-deployment-apache
minReplicaCount: 1 # Optional. Default: 0
maxReplicaCount: 8 # Optional. Default: 100
triggers:
- type: prometheus
metadata:
serverAddress: http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090
metricName: nginx_ingress_controller_requests
threshold: '100'
query: sum(irate(nginx_ingress_controller_requests{namespace="my-site"}[3m])) by (ingress)*10
тут мы указываем в каком namespace нам запускаться:
namespace: my-site
указываем цель, т.е. наш deployment:
name: my-deployment-apache
задаём минимальное и максимальное количество реплик
minReplicaCount: 1 # значение по умолчанию: 0
maxReplicaCount: 8 # значение по умолчанию: 100
есть ещё 2 стандартные переменные отвечающие за то когда поды будут подыматься и убиваться:
pollingInterval: 30 # Optional. Default: 30 seconds
cooldownPeriod: 300 # Optional. Default: 300 seconds
указываем адрес нашего prometheus
serverAddress: http://prometheus-kube-prometheus-prometheus.monitoring.svc.cluster.local:9090
адрес идёт в виде сервис.неймспейс.svc.имя_кластера
указываем нашу метрику:
metricName: nginx_ingress_controller_requests
указываем пороговое значение при котором начнётся автоскейлинг:
threshold: ‘100’
и соответственно наш запрос в prometheus:
query:
всё можно применять:
[root@kub-master-1 ~]# kubectl apply -f hpa-keda.yaml
проверяем:
[root@kub-master-1 ~]# kubectl get horizontalpodautoscalers.autoscaling -n my-site
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-prometheus-scaledobject Deployment/my-deployment-apache 0/100 (avg) 1 8 1 68m
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-v59b8 1/1 Running 0 37m
а теперь накрутим запросов:
[root@kub-worker-1 ~]# for i in {1..5000}; do curl test.ru; done
проверяем:
[root@kub-master-1 ~]# kubectl get horizontalpodautoscalers.autoscaling -n my-site
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
keda-hpa-prometheus-scaledobject Deployment/my-deployment-apache 34858m/100 (avg) 1 8 7 71m
как видим количество запросов превысило наш лимит и стали создаваться новые поды:
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-6885f 1/1 Running 0 49s
my-deployment-apache-859486bd8c-6mcq4 1/1 Running 0 64s
my-deployment-apache-859486bd8c-cdb6z 1/1 Running 0 64s
my-deployment-apache-859486bd8c-kpwb8 1/1 Running 0 64s
my-deployment-apache-859486bd8c-rmw8d 1/1 Running 0 49s
my-deployment-apache-859486bd8c-v59b8 1/1 Running 0 39m
my-deployment-apache-859486bd8c-xmv28 1/1 Running 0 49s
прекращаем запросы и спустя 5 минут, указанное в переменной cooldownPeriod ненужные поды будут убиты:
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-6885f 0/1 Terminating 0 6m35s
my-deployment-apache-859486bd8c-6mcq4 1/1 Running 0 6m50s
my-deployment-apache-859486bd8c-cdb6z 0/1 Terminating 0 6m50s
my-deployment-apache-859486bd8c-kpwb8 0/1 Terminating 0 6m50s
my-deployment-apache-859486bd8c-rmw8d 0/1 Terminating 0 6m35s
my-deployment-apache-859486bd8c-v59b8 0/1 Terminating 0 44m
my-deployment-apache-859486bd8c-xmv28 0/1 Terminating 0 6m35s
[root@kub-master-1 ~]# kubectl get pod -n my-site
NAME READY STATUS RESTARTS AGE
my-deployment-apache-859486bd8c-6mcq4 1/1 Running 0 7m48s
Источник: https://sidmid.ru/kubernetes-автоскейлинг-приложений-при-помощ/
2023-04-02T22:26:47
DevOps