Бывают ситуации, когда нужно автоматизировать сбор и анализ данных из разных источников. Например, если хочется мониторить курс рубля в режиме реального времени. Для решения подобных задач применяют парсинг.
В статье рассмотрена только основная теория. На практике встречаются нюансы, когда нужно, например, декодировать спаршенные данные, настроить работу программы через XPath или даже задействовать компьютерное зрение. Обо всем этом — в следующих статьях, если тема окажется интересной.
Что такое парсинг?
Парсинг — это процесс сбора, обработки и анализа данных. В качестве их источника может выступать веб-сайт.
Парсить веб-сайты можно несколькими способами — с помощью простых запросов сторонней программы и полноценной эмуляции работы браузера. Рассмотрим первый метод подробнее.
Аренда выделенного сервера
Сборка и безлимитный интернет 1 ГБ/сек — бесплатно.
Парсинг с помощью HTTP-запросов
Суть метода в том, чтобы отправить запрос на нужный ресурс и получить в ответ веб-страницу. Ресурсом может быть как простой лендинг, так и полноценная, например, социальная сеть. В общем, все то, что умеет «отдавать» веб-сервер в ответ на HTTP-запросы.
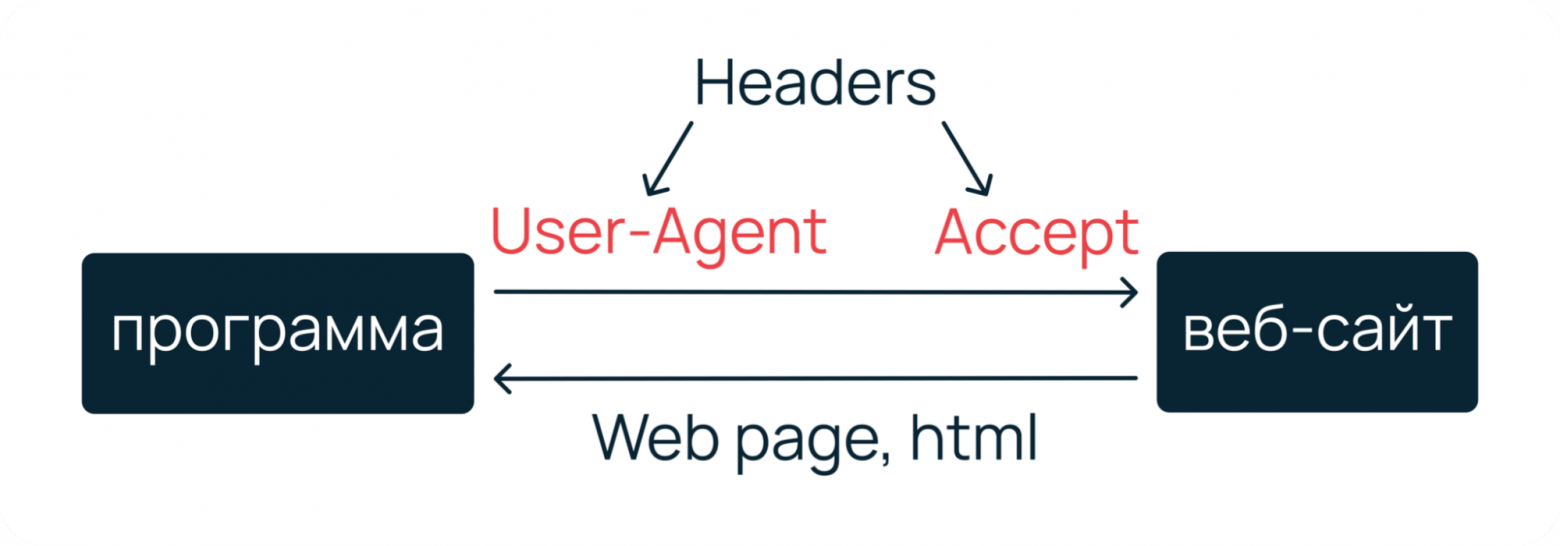 Схема взаимодействия с сервером.
Схема взаимодействия с сервером.
Чтобы сымитировать запрос от реального пользователя, вместе с ним нужно отправить на веб-сервер специальные заголовки — User-Agent, Accept, Accept-Encoding, Accept-Language, Cache-Control и Connection. Их вы можете увидеть, если откроете веб-инспектор своего браузера.
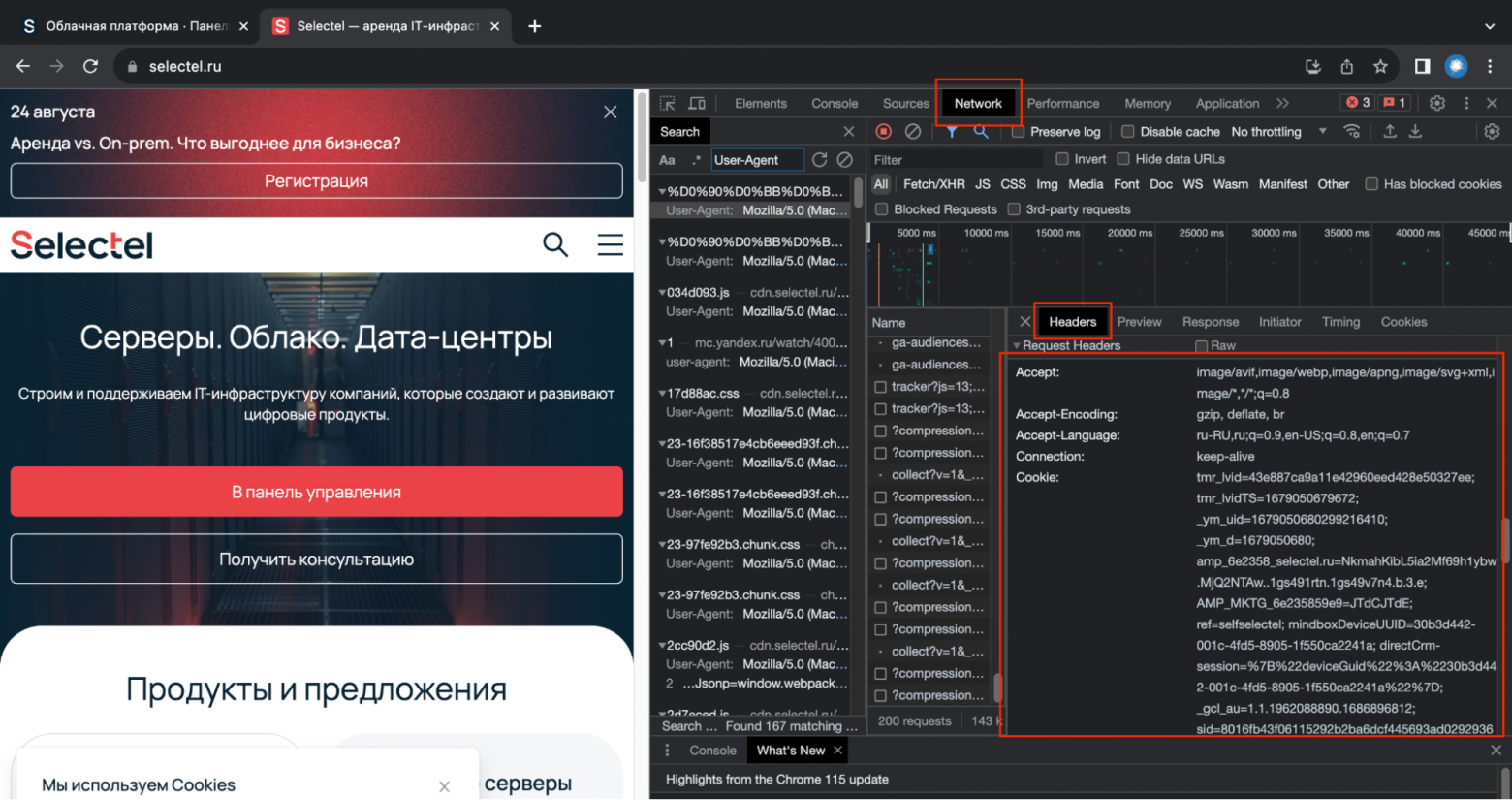 Пример открытого инспектора в браузере.
Пример открытого инспектора в браузере.
Подготовка заголовков
На самом деле, необязательно отправлять с запросом все заголовки. В большинстве случаев достаточно User-Agent и Accept. Первый заголовок поможет сымитировать, что мы реальный пользователь, который работает из браузера. Второй — укажет, что мы хотим получить от веб-сервера гипертекстовую разметку.
st_accept = «text/html» # говорим веб-серверу, # что хотим получить html# имитируем подключение через браузер Mozilla на macOSst_useragent = «Mozilla/5.0 (Macintosh; Intel Mac OS X 12_3_1) AppleWebKit/605.1.15 (KHTML, like Gecko) Version/15.4 Safari/605.1.15″# формируем хеш заголовковheaders = { «Accept»: st_accept, «User-Agent»: st_useragent}
После формирования заголовков нужно отправить запрос и сохранить страницу из ответа веб-сервера. Это можно сделать с помощью нескольких библиотек: Requests, ScraPy или PySpider.
Requests: получаем страницу по запросу
Для начала работы будет достаточно Requests — он удобнее и проще, чем привычный модуль urllib.
Requests — это библиотека на базе встроенного пакета urllib, которая позволяет легко отправлять различные веб-запросы, а также управлять кукисами и сессиями, авторизацией и автоматической организацией пула соединений.
Для примера попробуем спарсить страницу с курсами в Академии Selectel — это можно сделать за несколько действий:
# импортируем модульimport requests… # отправляем запрос с заголовками по нужному адресуreq = requests.get(«https://selectel.ru/blog/courses/», headers)# считываем текст HTML-документаsrc = req.textprint(src)
Сервер вернет html-страницу, который можно прочитать с помощью атрибута text.
<!doctype html><html data-n-head-ssr lang=»ru»><head>… <title>Курсы — Блог компании Селектел</title> <meta property=»og:locale» content=»ru_RU» /> <meta property=»og:type» content=»website» /> <meta property=»og:title» content=»Курсы — Блог компании Селектел» />…
Супер — гипертекстовую разметку страницы с курсами получили. Но что делать дальше и как извлечь из этого многообразия полезные данные? Для этого нужно применить некий «парсер для выборки данных».
Beautiful Soup: извлекаем данные из HTML
Извлечь полезные данные из полученной html-страницы можно с помощью библиотеки Beautiful Soup.
Beautiful Soup — это, по сути, анализатор и конвертер содержимого html- и xml-документов. С помощью него полученную гипертекстовую разметку можно преобразовать в полноценные объекты, атрибуты которых — теги в html.
# импортируем модульfrom bs4 import BeautifulSoup… # инициализируем html-код страницы soup = BeautifulSoup(src, ‘lxml’)# считываем заголовок страницыtitle = soup.title.stringprint(title)# Программа выведет: Курсы — Блог компании Селектел
Готово. У нас получилось спарсить и напечатать заголовок страницы. Где это можно применить — решать только вам. Например, мы в Selecte на базе Requests и Beautiful Soup разработали парсер данных с Хабра. Он помогает собирать и анализировать статистику по выбранным хабраблогам.
Проблема парсинга с помощью HTTP-запросов
Бывают ситуации, когда с помощью простых веб-запросов не получается спарсить все данные со страницы. Например, если часть контента подгружается с помощью API и JavaScript. Тогда сайт можно спарсить только через эмуляцию работы браузера.
Интересен Python? Мы собрали самые интересные и популярные запросы разработчиков в одном файле! По ссылке — материалы по геймдеву, машинному обучению, программированию микроконтроллеров и графических интерфейсов.
Парсинг с помощью эмулятора
Для эмуляции работы браузера необходимо написать программу, которая будет как человек открывать нужные веб-страницы, взаимодействовать с элементами с помощью курсора, искать и записывать ценные данные. Такой алгоритм можно организовать с помощью библиотеки Selenium.
Настройка рабочего окружения
1. Установите ChromeDriver — именно с ним будет взаимодействовать Selenium. Если вы хотите, чтобы актуальная версия ChromeDriver подтягивалась автоматически, воспользуйтесь webdriver-manager. Далее импортируйте Selenium и необходимые зависимости.
pip3 install selenium from selenium import webdriver as wd
2. Инициализируйте ChromeDriver. В качестве executable_path укажите путь до установленного драйвера.
browser = wd.Chrome(«/usr/bin/chromedriver/»)
Задача: работа с динамическим поиском
При переходе на страницу Академии встречает общая лента, в которой собраны материалы для технических специалистов. Они помогают прокачивать навыки и быть в курсе новинок из мира IT.
 Пример страницы Академии Selectel.
Пример страницы Академии Selectel.
Но материалов много, а у нас задача — найти все статьи, связанные с Git. Подойдем к парсингу системно и разобьем его на два этапа.
Шаг 1. Планирование
Для начала нужно продумать, с какими элементами должна взаимодействовать наша программа, чтобы найти статьи. Но здесь все просто: в рамках задачи Selenium должен кликнуть на кнопку поиска, ввести поисковый запрос и отобрать полезные статьи.
 Настройка Selenium на примере работы с поиском по Академии Selectel.
Настройка Selenium на примере работы с поиском по Академии Selectel.
Теперь скопируем названия классов html-элементов и напишем скрипт!
Шаг 2. Работа с полем ввода
Работа с html-элементами сводится к нескольким пунктам: регистрации объектов и запуску действий, которые будет имитировать Selenium.
…# регистрируем кнопку «Поиск» и имитируем нажатиеopen_search = browser.find_element_by_class_name(«header_search»)open_search.click()# регистрируем текстовое поле и имитируем ввод строки «Git»search = browser.find_element_by_class_name(«search-modal_input»)search.send_keys(«Git»)
Осталось запустить скрипт и проверить, как он отрабатывает:
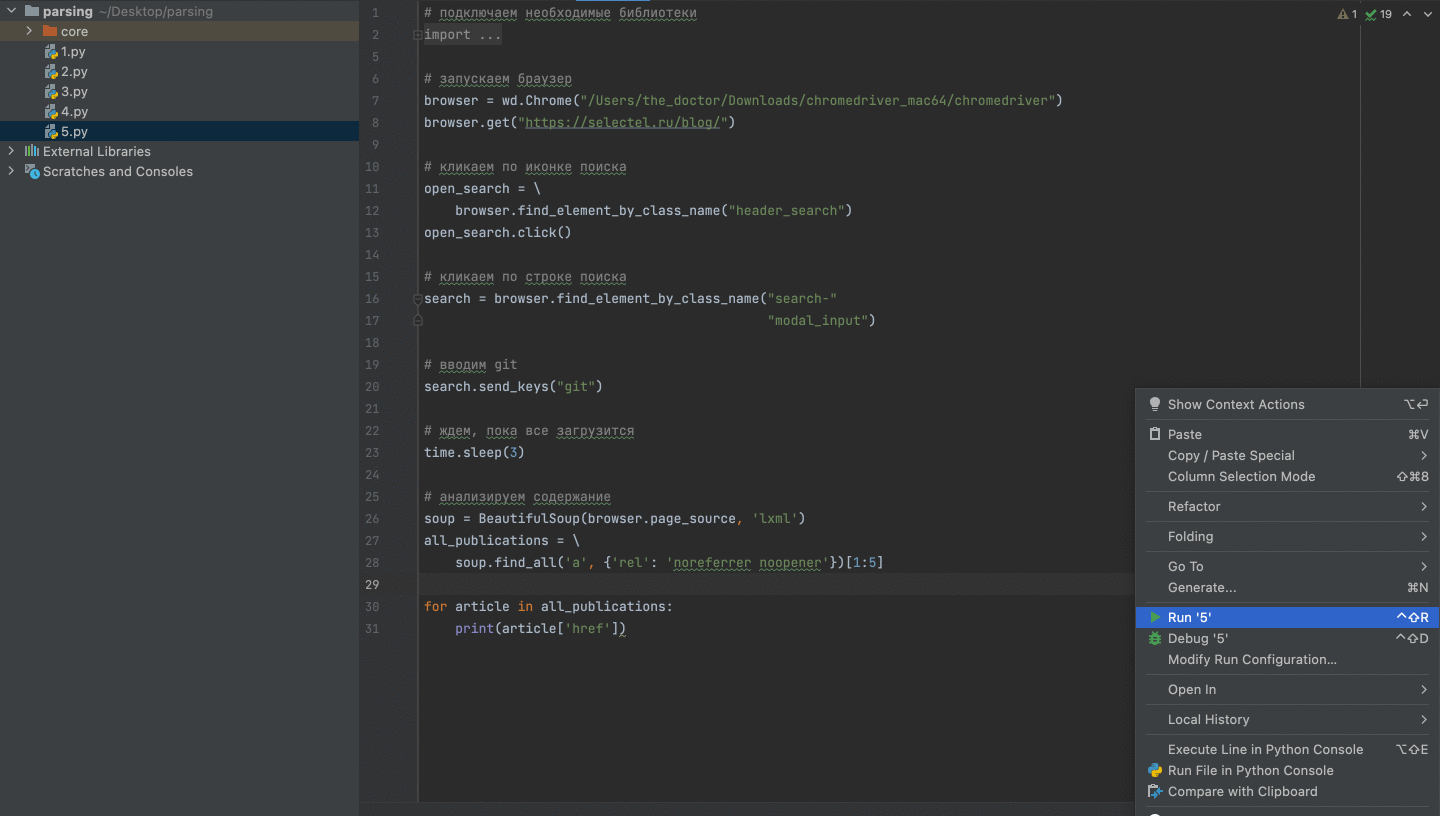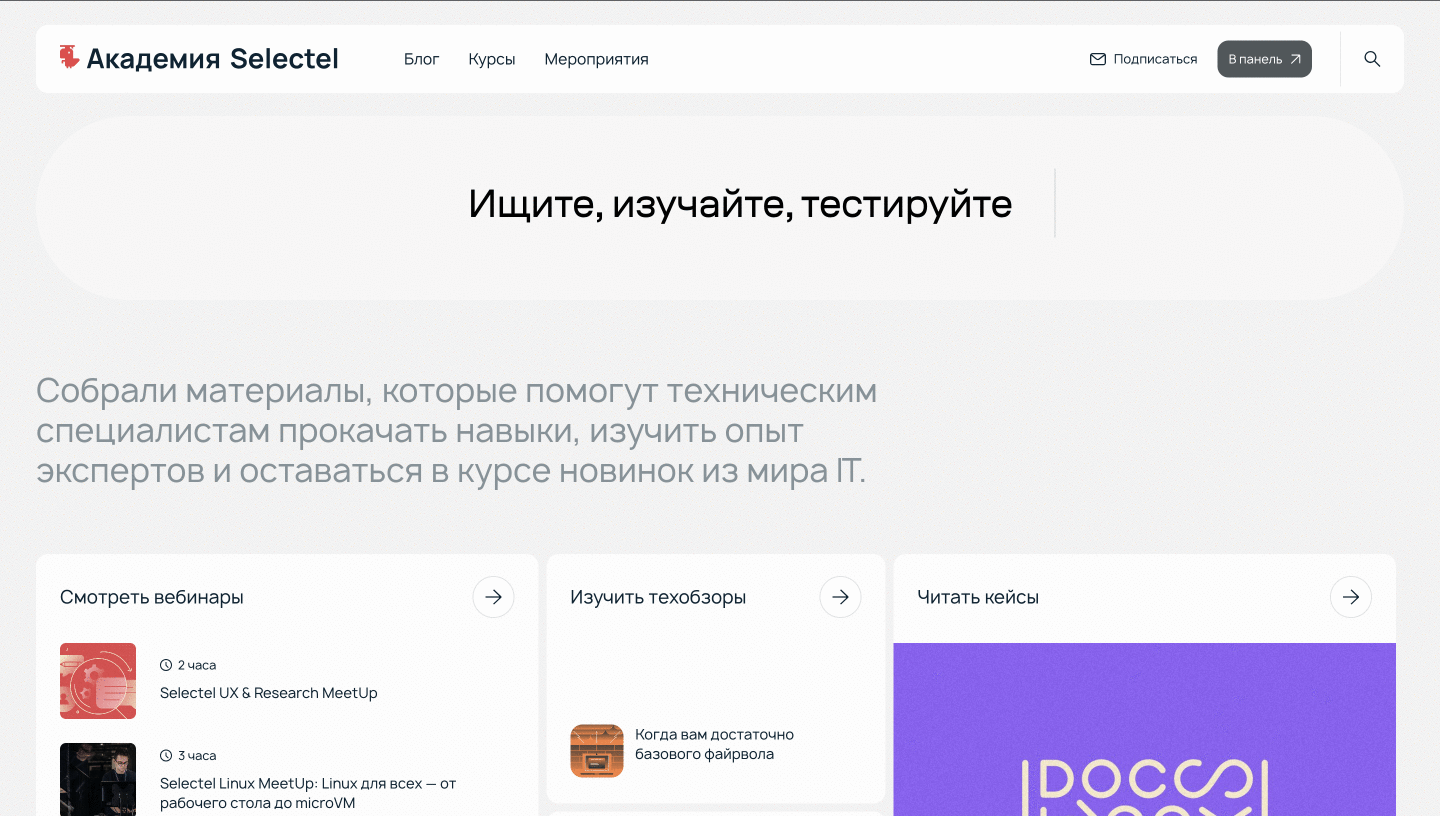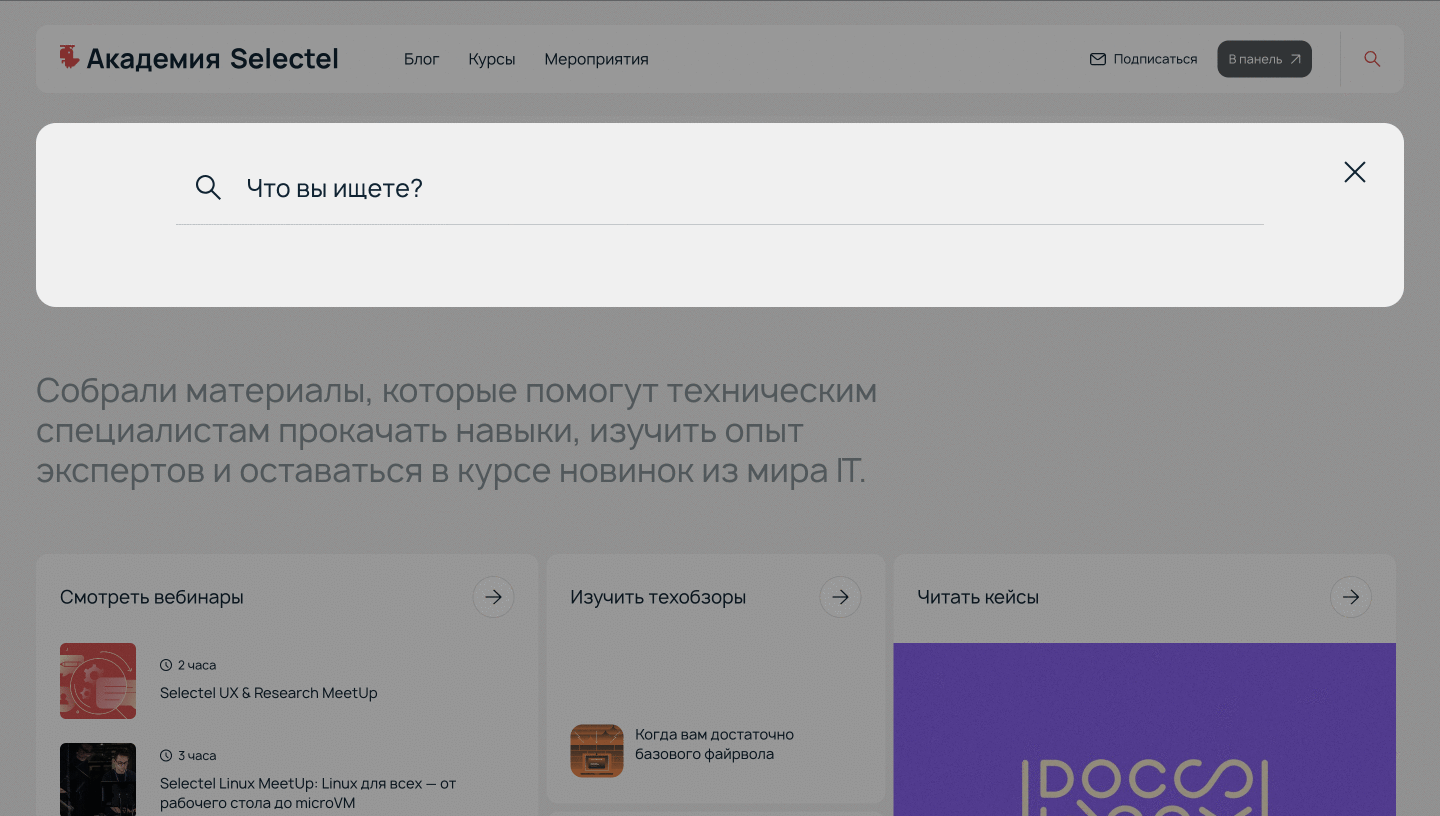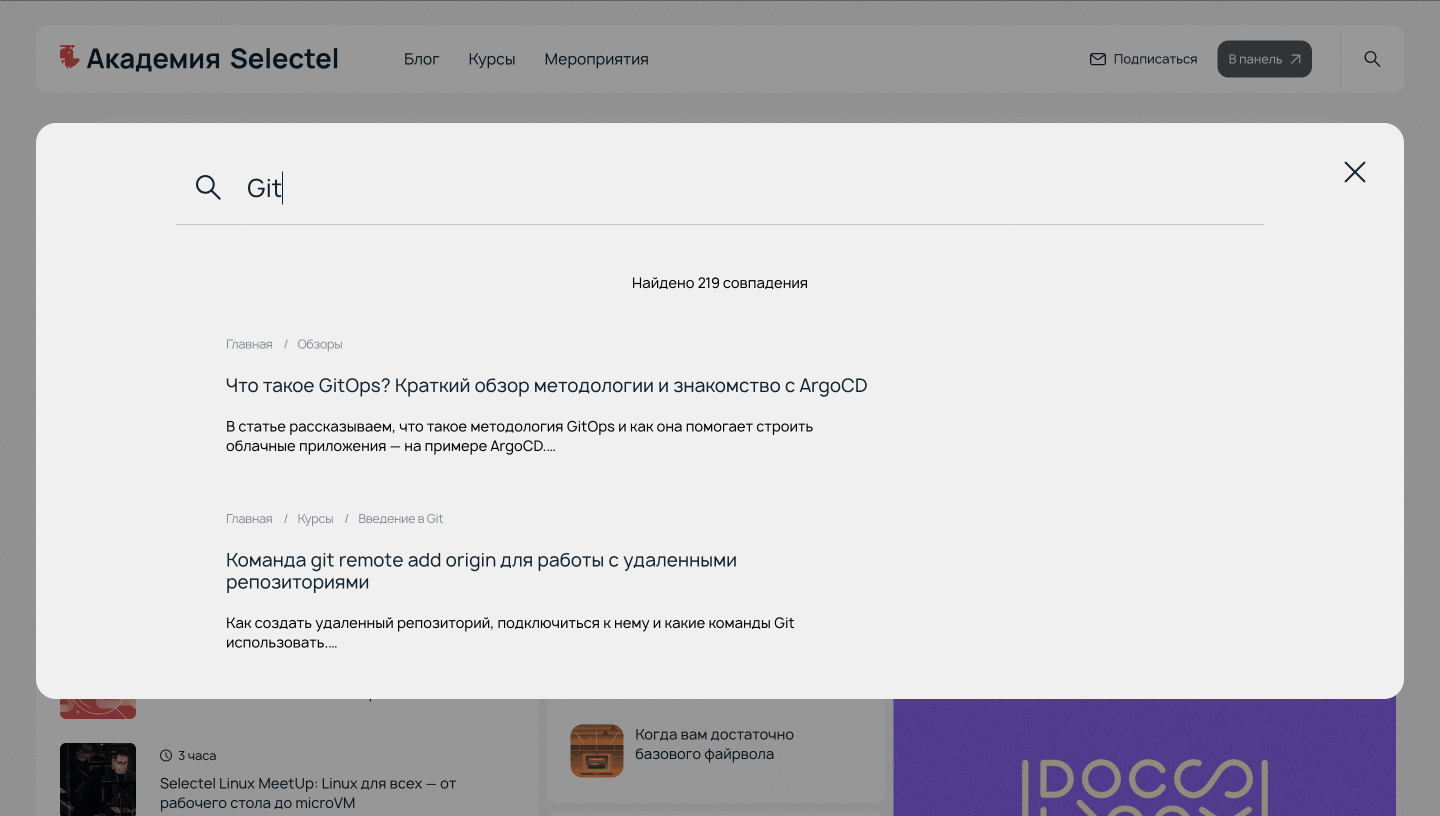 Пример работы скрипта.
Пример работы скрипта.
Скрипт работает корректно — осталось вывести результат.
Шаг 3. Чтение ссылок и результат
Вне зависимости от того, какая у вас задача, если вы работаете с Requests и Selenium, Beautiful Soup станет серебряной пулей в обоих случаях. С помощью этой библиотеки мы извлечем полезные данные из полученной гипертекстовой разметки.
from bs4 import BeautifulSoup…# ставим на паузу, чтобы страница прогрузиласьtime.sleep(3)# загружаем страницу и извлекаем ссылки через атрибут relsoup = BeautifulSoup(browser.page_source, ‘lxml’)all_publications = soup.find_all(‘a’, {‘rel’: ‘noreferrer noopener’})[1:5]# форматируем результатfor article in all_publications: print(article[‘href’])
Готово — программа работает и выводит ссылки на статьи о Git. При клике по ссылкам открываются соответветствующие страницы в Академии Selectel.
