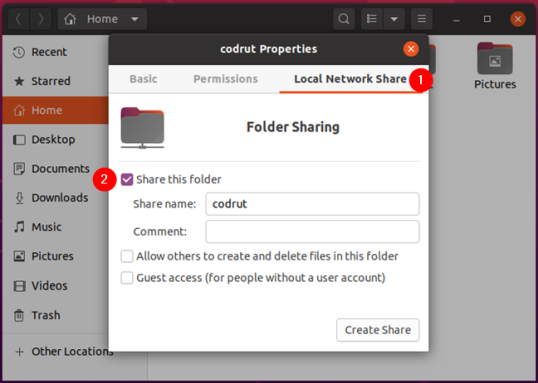
Это краткое руководство показывает студентам и новым пользователям, как настроить Ubuntu для удержания или предотвращения обновления пакетов.
В некоторых случаях вы можете не захотеть обновлять конкретный пакет. Например, у вас есть веб-сервер Nginx, настроенный с определенными параметрами, и вы знаете, что обновление изменит его конфигурацию и остановит его работу.
Вы можете настроить удержание пакета, чтобы он не обновлялся даже при наличии обновлений, пока вы не будете готовы его обновить.
Предотвращение установки или обновления пакета называется «удержанием пакета».
Это отличная функция, поскольку вы не будете автоматически обновлять пакет или программное обеспечение, которые вы не хотите обновлять в это время. Вы также можете обновить его позже.
Чтобы начать работу с блокировкой или удержанием пакетов в Ubuntu, выполните следующие действия:
Показать пакеты
Существует множество инструментов для блокировки или предотвращения обновления пакетов. Вы можете установить и использовать Synaptic package management, Aptitude для хранения пакетов или использовать команду для того же.
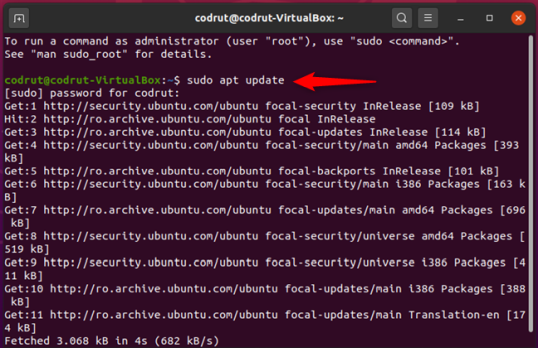
Используя командную строку, чтобы показать все пакеты, которые не обновляются, выполните следующие команды:
sudo apt-mark showhold
Это перечислит пакеты, которые находятся в режиме ожидания.
Удерживайте или блокируйте пакеты
Теперь, когда вы знаете, как отображать заблокированные пакеты, используйте приведенные ниже команды, чтобы заблокировать или предотвратить обновление определенных пакетов.
sudo apt-mark hold <имя-пакета>
Если вы используете aptitude, используйте следующие команды:
sudo aptitude hold <имя-пакета>
Замените <имя-пакета> на пакет, который вы хотите отложить. Например, если вы хотите заблокировать веб-сервер Nginx, выполните следующие команды:
sudo apt-mark hold nginx
Это будет удерживать веб-сервер Nginx от обновления.
Разблокировать пакеты
Если вы хотите разморозить или разблокировать пакеты, чтобы они продолжали получать обновления, выполните следующие команды:
sudo apt-mark unhold <имя-пакета>
Если вы используете aptitude, выполните следующие команды:
sudo aptitude unhold <имя-пакета>
Снова замените <package-name> на пакет, который вы хотите разблокировать или разморозить, и пусть они продолжают получать обновления.
Например, если вы хотите разблокировать Nginx после того, как вы заблокировали выше, выполните следующие команды:
sudo apt-mark unhold nginx
Управление пакетами Synaptic
Если вы используете управление пакетами Synaptic, перейдите в Диспетчер пакетов Synaptic (Действия ==> Поиск Synaptic).
Нажмите кнопку поиска и введите имя пакета, который хотите заблокировать.
Когда вы найдете пакет, выберите его, перейдите в меню «Пакет» и выберите «Заблокировать версию».
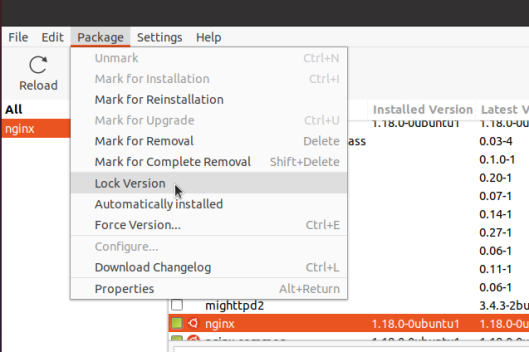
Это заблокирует пакет от получения обновлений.
Это должно сработать!
Вывод:
В этом посте показано, как настроить Ubuntu для блокировки пакетов и предотвращения их установки или получения обновлений.
Если вы обнаружите какую-либо ошибку выше, пожалуйста, используйте форму ниже, чтобы сообщить.