- KB5030310 — это дополнительное обновление, которое необходимо установить вручную.
- Это обновление «Момент 4», поскольку оно представляет новые функции, ожидаемые в версиях от Windows 11 23H2 до Windows 11 22H2, включая Windows Copilot, обновленный Проводник и многое другое.
Microsoft опубликовала КБ5030310 для Windows 11 22H2 в качестве предварительного обновления. Это означает, что вам придется установить его вручную, если не включена автоматическая установка дополнительных обновлений.
Этот выпуск также называют обновлением «Момент 4», поскольку он представляет несколько важных новых функций, которые ожидаются в 4-м основном выпуске, поскольку исходный выпуск Windows 11, как ожидается, выйдет 10 октября.
В предвкушении предстоящей версии Windows 11 23H2, KB5030310 представляет собой раннюю предварительную версию, в которой представлены новые функции, такие как Windows Copilot и обновленный проводник, из будущей версии в текущую версию 22H2. Это сделано для того, чтобы Microsoft могла провести бета-тестирование этих функций и внести любые исправления перед их общедоступным выпуском.
Вы можете загрузить и установить KB5030310 из Центра обновления Windows или по прямым ссылкам для загрузки, указанным ниже. Установка этого обновления обновит сборку вашей операционной системы до 22621.2361.
Обратите внимание: если вы хотите установить это обновление и пользоваться функциями Windows 11 23H2 раньше всех остальных, вам необходимо сначала установить обновление конфигурации Windows.
Примечание: КБ5030301 также было выпущено как дополнительное обновление, но применимо к Windows 11 версии 21H2. В нем представлены исправления, аналогичные KB5030310, за исключением новых функций 23H2. Кроме того, это последнее необязательное обновление, не связанное с безопасностью, для Windows 11 22H2, и оно больше не будет выпущено.
Сводка выпуска KB5030310
- Статья базы знаний: КБ5030310
- Версия ОС: Windows 11 версия 22H2
- Строить: 22621.2361
- Размер: 601,2 МБ
- Дата выпуска: 26 сентября 2023 г.
Новое в KB5030310
KB5030310 не является обновлением, не связанным с безопасностью, оно включает только новые функции и устраняет существующие проблемы. Вот основные моменты новых функций, которые он представляет.
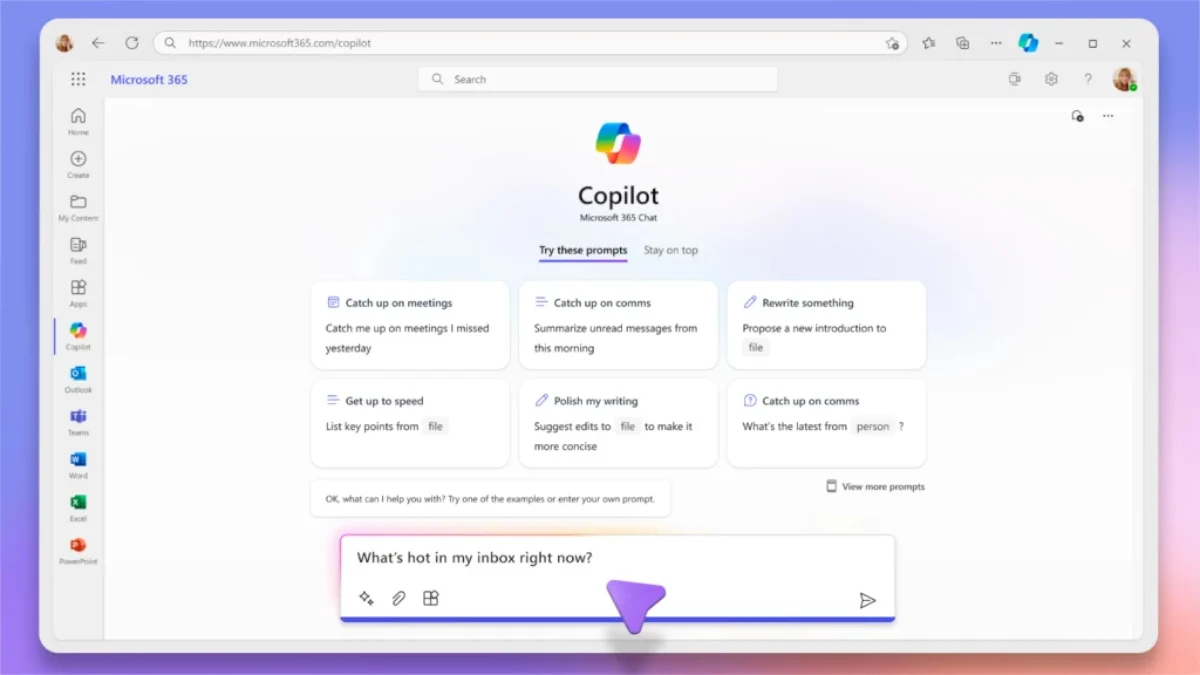
Windows второй пилот
Благодаря полной интеграции искусственного интеллекта Microsoft также включила его в Windows 11 23H2. Copilot позволяет вам напрямую взаимодействовать с ИИ и повышать производительность в дороге.
После установки дополнительного обновления KB5030310 вы сможете освоить Windows Copilot. Использовать Клавиша Windows + С сочетания клавиш из любой точки Windows и взломайте их с помощью Copilot.
 Windows второй пилот
Windows второй пилот
Дев Драйв
Dev Drive — это новая функция, представленная в Windows 11 23H2. Используя эту технологию, пользователи могут создавать специализированные диски или тома, которые работают лучше, чем обычные разделы.
Эта функция специально предназначена для разработчиков. Целевая оптимизация файловой системы реализуется с помощью ReFS и предлагает дополнительный административный контроль над настройками безопасности и настройками объема хранилища, такими как обозначение доверия, настройка антивируса и административный контроль над связанными фильтрами.
Чтобы настроить, создать Dev Drives и управлять ими, перейдите на страницу Настройки > Система > Память > Диски и тома.
 Диск для разработчиков в настройках Windows
Диск для разработчиков в настройках Windows
Узнайте все о Dev Drive и о том, как его настроить.
Голосовой доступ
Windows 11 23H2 представляет набор новых голосовых возможностей. Он расширяет команды, которые теперь вы можете предоставить ОС Windows, и реагирует соответствующим образом.
Например, теперь вы можете сказать «Исправьте это», и Windows откроет всплывающее окно исправления с пронумерованными опциями.
Другие функции, улучшения и исправления в KB5030310.
Помимо этих ключевых функций, Microsoft также представляет следующий список функций и исправлений для Windows 11 22H2 с KB5030310:
- (Функции)
- Добавляет персонализированные веб-сайты в раздел «Рекомендуемые» меню «Пуск» на основе истории посещений. Чтобы отключить эту функцию, перейдите в Настройки > Персонализация > Начинать.
- Ключ доступа теперь поддерживается.
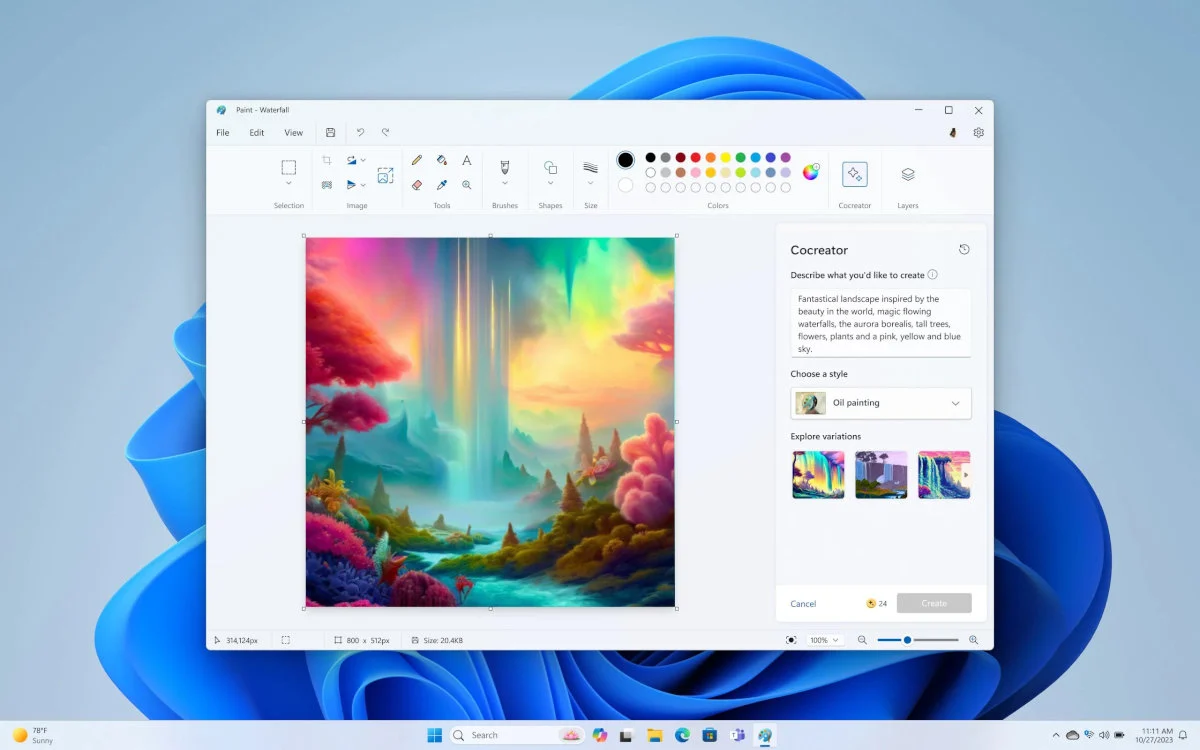
- Paint Cocreator представляет функцию преобразования текста в изображение.
- В проводнике есть «Галерея», упрощающая доступ к фотографиям.
- Clipchamp включает автоматическое создание видео.
- Было представлено приложение Windows Backup для бесперебойного резервного копирования и восстановления данных.
- Улучшены функции определения присутствия, такие как «Адаптивное затемнение».
- Приложение «Фото» теперь может похвастаться расширенными возможностями редактирования.
- Рассказчик теперь использует естественные человеческие голоса и поддерживает новые языки.
- Инструмент «Ножницы» включает поддержку звука и микрофона.
- (Исправления и изменения)
- Это обновление устраняет проблему, затрагивающую Microsoft Excel. Он перестает отвечать, когда вы пытаетесь поделиться файлом в формате PDF в Outlook.
- Это обновление устраняет проблему, затрагивающую корейскую сенсорную клавиатуру. Он дополняет первый символ в поле поиска на панели задач. Этого не ожидается.
- Это обновление устраняет проблему, которая влияет на всплывающую подсказку окна поиска. Он не отображается в правильном положении.
- Это обновление устраняет проблему, которая затрагивает кнопку поиска. Он исчезает при взаимодействии с всплывающим окном поиска.
- Это обновление устраняет проблему, влияющую на спящий режим. После выхода из спящего режима появляется пустое окно с заголовком «Ввод данных в Windows».
- Это обновление устраняет проблему, которая затрагивает Календарь и Контакты iCloud. Outlook не может правильно синхронизировать их при использовании приложения iCloud для Windows. Чтобы возобновить синхронизацию, выполните действия, описанные в этой статье поддержки Apple. статья.
- Это обновление завершает работу по обеспечению соответствия требованиям GB18030-2022. Он удаляет и переназначает символы для ввода Microsoft Wubi и ввода U-режима Microsoft Pinyin.
- Это обновление поддерживает переход на летнее время (DST) в Гренландии.
- Это обновление меняет написание столицы Украины с Киева на Киев.
- Это обновление устраняет проблему, влияющую на событие блокировки учетной записи 4625. Неверный формат события в журнале ForwardedEvents. Это происходит, когда имя учетной записи имеет формат имени участника-пользователя (UPN).
- Это обновление затрагивает центр распространения ключей (KDC) и идентификаторы безопасности пользователей (SID).
- Это обновление устраняет проблему, связанную с изменениями в пересылке событий.
- Это обновление устраняет проблему, которая затрагивает события, имеющие символ TAB. События не отображаются, или вы не можете их пересылать.
- Это обновление устраняет проблему, которая затрагивает запросы XPath к FileHash и другим двоичным полям. Это не позволяет им сопоставлять значения в записях событий.
- Это обновление устраняет проблему, которая затрагивает среду виртуализации приложений (App-V). Операции копирования внутри него перестают работать. Это происходит после установки обновления за апрель 2023 г.
- Это обновление устраняет проблему, которая затрагивает Microsoft Print to PDF.
- Это обновление устраняет проблему, которая затрагивает некоторые USB-принтеры. Защитник Microsoft не позволяет им печатать.
- Это обновление устраняет проблему, влияющую на управление приложениями Защитника Windows (WDAC). Политики тегирования AppID могут значительно увеличить время запуска вашего устройства.
- Это обновление устраняет проблему, затрагивающую IMEPad. Он перестает работать. Это происходит при вводе символов, определяемых конечным пользователем (EUDC).
- Это обновление устраняет проблему, затрагивающую удаленные приложения. Отображение некоторых элементов выровнено неправильно.
- Это обновление устраняет проблему, затрагивающую координатора распределенных транзакций Microsoft (DTC). Имеет течь ручки. Из-за этого системе не хватает памяти.
- Это обновление устраняет проблему, из-за которой Windows может перестать отвечать на запросы. Это может произойти, если вы используете файлы Microsoft OneDrive, сжатые NTFS.
- Это обновление устраняет проблему, которая может вызвать утечку памяти в пользовательском режиме. Это может произойти, когда вы позвоните Копировать файл() или ПереместитьФайл().
- Это обновление устраняет проблему, влияющую на совместимость приложений. Это связано с Microsoft Defender для конечной точки.
- Это обновление устраняет проблему, влияющую на внешнюю привязку. Это терпит неудачу.
Благодаря этим исправлениям и улучшениям в настоящее время в этом выпуске нет известных проблем. Однако есть несколько стабильных обновлений для Windows 11. Подробнее о них можно прочитать здесь:
Известные проблемы и исправления Windows 11
Загрузите и установите Windows 11 KB5030310.
Это дополнительное обновление, не связанное с безопасностью, можно установить через Центр обновления Windows и автономные установщики.
Ниже мы предоставили прямые ссылки для загрузки автономных установщиков, с помощью которых вы можете установить обновление в соответствующей версии Windows 11 или просто обновиться до последней сборки с помощью Центра обновления Windows, следуя приведенному ниже руководству.
Автономные установщики
Загрузите предварительный накопительный пакет обновления KB5030310 для 64-разрядной версии Windows 11 22H2 (601,2 МБ)
Загрузите предварительный накопительный пакет обновления KB5030310 для Windows 11 версии 22H2 ARM64 (715,9 МБ)
Чтобы установить обновление, просто запустите загруженный файл MSU, и Windows автоматически установит обновление. Чтобы загрузить любые другие обновления, связанные с любым из вышеперечисленных, пожалуйста, проверьте Каталог Майкрософт.
Центр обновления Windows
Чтобы установить это обновление через Центр обновления Windows, вам необходимо использовать Windows 11 версии 22H2. Чтобы проверить свою версию операционной системы, введите «победитель» в поле «Выполнить команду» и нажмите Входить. Вам также необходимо установить обновление конфигурации Windows.
Убедившись, что у вас правильная версия ОС, выполните следующие шаги для установки KB5030310:
-
Перейдите к следующему:
Приложение «Настройки» >> Центр обновления Windows
-
Здесь нажмите «Проверьте наличие обновлений».
 Проверьте наличие ожидающих обновлений
Проверьте наличие ожидающих обновлений
-
Нажмите «Загрузить и установить» в рамках доступного дополнительного обновления.
Вы увидите следующее обновление, доступное в разделе Дополнительное качественное обновление доступный:
Доступен накопительный предварительный просмотр обновления 2023-09 для Windows 11 версии 22H2 для систем на базе x64 (KB5030310).
Загрузите и установите KB5030310 с функциями Windows 11 23H2.
-
(При условии) Если вы не выбрали получение последних обновлений Windows, как только они станут доступны, вы можете увидеть всплывающее диалоговое окно. Выберите, хотите ли вы принять участие или нет.
Выберите получение обновлений, как только они станут доступны.
-
После загрузки и установки обновления нажмите «Перезагрузить сейчас».
Перезагрузить компьютер 3.
После перезагрузки компьютера обновление будет успешно установлено. Чтобы убедиться в этом, проверьте обновленный номер сборки, набрав «победитель» в поле «Выполнить команду».
 KB5030310 установлен
KB5030310 установлен
Откат/удаление накопительного обновления Windows 11
Если вы по каким-то причинам не желаете сохранять установленное обновление, вы всегда можете откатиться к предыдущей сборке ОС. Однако это можно сделать только в течение следующих 10 дней после установки нового обновления.
Чтобы откатиться через 10 дней, вам нужно будет применить этот трюк.
Очистка после установки обновлений Windows
Если вы хотите сэкономить место после установки обновлений Windows, вы можете выполнить одну за другой следующие команды в командной строке с правами администратора:
dism.exe/Online/Cleanup-Image/AnalyzeComponentStore dism.exe/Online/Cleanup-Image/StartComponentCleanup
 Очистка Windows после установки Центра обновления Windows
Очистка Windows после установки Центра обновления Windows
Заблокировать установку KB5030310
Хотя это необязательное обновление, а это значит, что оно не будет установлено без нажатия каких-либо кнопок вручную. Однако вы можете полностью заблокировать его установку, как временно, так и навсегда, выполнив следующие действия:
-
Загрузите инструмент «Показать или скрыть обновления» от Майкрософт.
-
Запустите утилиту и нажмите Следующий чтобы начать процесс сканирования.
 Показать или скрыть обновления
Показать или скрыть обновления
-
Далее нажмите кнопку «Скрыть обновления” кнопка.
Скрыть обновления
-
Выберите обновления, которые хотите заблокировать, и нажмите Следующий.
Список обновлений, которые нужно скрыть
Это автоматически скроет обновление из Центра обновления Windows и не будет установлено во время следующего процесса обновления.
-
Нажмите кнопку Закрывать кнопка.
Если вы хотите отобразить или показать скрытые обновления, запустите инструмент еще раз и выберите «Показать скрытые обновления” вместо “Скрыть обновления». В остальном процесс тот же.
Windows 11 KB5030310 Момент 4, практический курс
Для начала Windows 11 KB5030310 пришлось установить вручную. Он был немного больше, поэтому его загрузка и последующая установка заняли много времени. Однако процесс прошел гладко.
После установки и загрузки компьютера поначалу существенных различий не было. Однако после изучения новых функций мы обнаружили, что многие из них не были раскрыты Microsoft в примечаниях к выпуску KB5030310 или обновлении конфигурации, выпущенном ранее.
В приложении «Настройки» мы заметили новую вкладку на боковой панели с тегом «Дом». Это новая страница настроек, которая объединяет несколько существующих страниц настроек, включая информацию об учетной записи Microsoft, последние настройки, к которым вы, возможно, имели доступ, а также некоторые параметры персонализации.
Новая страница домашних настроек
Мы также заметили другие изменения, такие как обновленный Проводник, Windows Copilot и другие функции, упомянутые в сообщении выше. В целом после установки KB5030310 остались хорошие впечатления, и с нетерпением ждем Windows 11 версии 2023 (23H2).
История дополнительных обновлений Windows 11, не связанных с безопасностью
Статья базы знанийВерсия ОССтроитьДата выпускаЗначительные измененияОбъявлениеKB503031022H222621.236126-Сентябрь 23 – представляет новые функции Windows 11 23H2.
– Сделаны основные исправления и решены проблемы.Анонс Microsoft о выпуске KB5030310KB502935122H222621.221522-23 августа — улучшены настройки приложения по умолчанию и его закрепление.
– Включает поведение при наведении курсора на блеск окна поиска.Объявление Microsoft о KB5029351KB502825422H222621.207026-июль-23 — устранены проблемы с push-уведомлениями.
– Исправлены проблемы с VPN-подключением.Анонс Microsoft о KB5028254KB502730322H222621.192827-июнь-23 – включает все функции и улучшения Moment 3, включая возможность показывать секунды на часах на панели задач.
– Улучшен обмен локальным файлом в проводнике с контактами Microsoft Outlook.
– Несколько дополнений и изменений на страницах приложения «Настройки».Анонс Microsoft о KB5027303KB502644622H222621.177824-23 мая — устраняет известную проблему с распознаванием речи, добавляет представление общего хранилища OneDrive на странице настроек учетных записей, добавляет Bluetooth LE к поддерживаемому оборудованию.
– Представляет новую проблему с 32-битными приложениями при их сохранении, прикреплении и перемещении.Анонс Microsoft о KB5026446Журнал изменений для дополнительных предварительных обновлений, не связанных с безопасностью, для Windows 11
2023-09-27T12:33:17
Tips and Tricks

 Windows второй пилот
Windows второй пилот Диск для разработчиков в настройках Windows
Диск для разработчиков в настройках Windows Проверьте наличие ожидающих обновлений
Проверьте наличие ожидающих обновлений
 Загрузите и установите KB5030310 с функциями Windows 11 23H2.
Загрузите и установите KB5030310 с функциями Windows 11 23H2.
 Выберите получение обновлений, как только они станут доступны.
Выберите получение обновлений, как только они станут доступны.
 Перезагрузить компьютер 3.
Перезагрузить компьютер 3.
 KB5030310 установлен
KB5030310 установлен Очистка Windows после установки Центра обновления Windows
Очистка Windows после установки Центра обновления Windows Показать или скрыть обновления
Показать или скрыть обновления
 Скрыть обновления
Скрыть обновления
 Список обновлений, которые нужно скрыть
Список обновлений, которые нужно скрыть Новая страница домашних настроек
Новая страница домашних настроек