Многие из нас пережили сбой жесткого диска или SSD. Некоторые из нас даже пытались узнать больше о надежности жестких дисков и их функции скрытого прогнозирования, которая является частью технологии SMART. Можно утверждать, что SMART не так надежен, так как он не предсказывает неудачу во всех случаях. Этот факт отчасти верен, но действительная внутренняя работа этой системы самоконтроля не так проста, поэтому давайте рассмотрим, как работает SMART. Мы также собираемся показать вам, как проверить состояние SMART жесткого диска, а также состояние SMART твердотельного накопителя
Что такое SMART (HDD и SSD)?
SMART — это система, которая контролирует внутреннюю информацию вашего диска. Его умное название на самом деле является аббревиатурой от технологии самоконтроля, анализа и отчетности. SMART, также называемая SMART, — это технология, используемая в жестких дисках и твердотельных накопителях. Он не зависит от вашей операционной системы, BIOS или другого программного обеспечения.
Что делает SMART для HDD и SSD?
SMART был изобретен, потому что компьютерам требовалось что-то, что могло бы контролировать состояние их жестких дисков. Это означает, что SMART должен сказать, что ваш жесткий диск или твердотельный накопитель перестанет работать!

Как SMART делает это? У вас может возникнуть соблазн думать, что SMART может волшебным образом угадать, исправен ли ваш диск. 🙂 То, что он делает, это совсем другая история. SMART отслеживает ряд переменных, число и тип которых варьируются от диска к диску, что является показателем его надежности. Если вы хотите получить подробное представление обо всех атрибутах SMART, поскольку их около 50 (частота ошибок необработанного чтения, время раскрутки, сообщаемые неисправимые ошибки, время включения, количество циклов загрузки и т.д.), посетите эту страницу.
Тем не менее, следует знать, что, за исключением отдельных попыток (Google , Backblaze), большинство данных SMART не документированы. Система предоставляет много внутренних данных. Тем не менее, в статистике много несоответствий, потому что многие производители жестких дисков используют разные определения и измерения. Например, некоторые производители хранят данные о времени включения в виде часов, в то время как другие измеряют их в минутах или секундах. Кроме того, они не объясняют, какие из различных атрибутов или переменных заслуживают нашего внимания, заставляя нас утонуть в данных.
Прежде чем пытаться понять, какие атрибуты SMART являются релевантными, мы должны сначала провести различие между основными типами сбоев SSD и HDD: предсказуемыми и непредсказуемыми.

Предсказуемые отказы включают поломки, которые появляются вовремя и вызваны неисправной механикой диска или повреждениями поверхности диска в случае жестких дисков. Для твердотельных накопителей прогнозируемые сбои могут включать нормальный износ с течением времени или большое количество попыток стирания, которые не увенчались успехом. Проблемы усугубляются со временем, и диск в конечном итоге выходит из строя.
Непредсказуемые сбои вызваны внезапными событиями, из которых мы можем упомянуть, например, внезапные скачки напряжения или непредвиденное повреждение схемы внутри жесткого диска или твердотельного накопителя. Важно понимать, что SMART может помочь вам обнаружить только предсказуемые ошибки .
Теперь, когда у вас есть общее представление о том, что такое SMART и что делает, давайте посмотрим, как проверить состояние SMART ваших дисков в Windows, а затем также узнать, как читать и интерпретировать данные SMART.
Как проверить статус SSD и HDD SMART
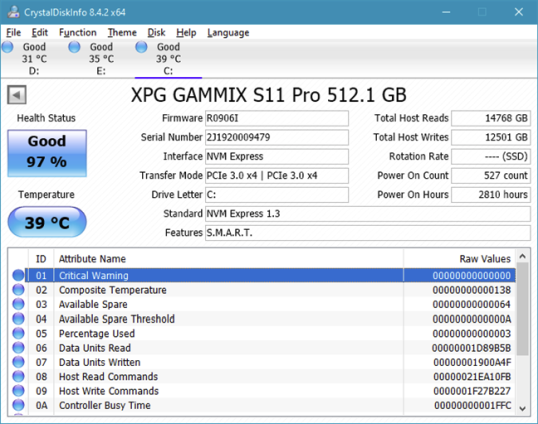
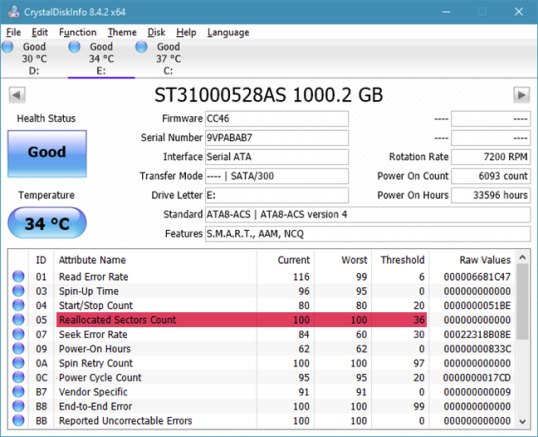
На компьютерах и устройствах с Windows самый простой способ считывания данных SMART с жесткого диска или с SSD — использование специализированных приложений. Там немало, но многие из них либо плохо развиты, либо стоят денег. Из всех приложений, которые могут считывать данные SMART, лучшим из тех, которые мы рекомендуем использовать, является CrystalDiskInfo. Он бесплатный, способен считывать атрибуты SMART, а также является одним из немногих таких приложений, которые могут получать данные SMART как с дисков IDE (PATA), SATA и NVMe, так и с портативных дисков, использующих eSATA, USB, или IEEE 1394.

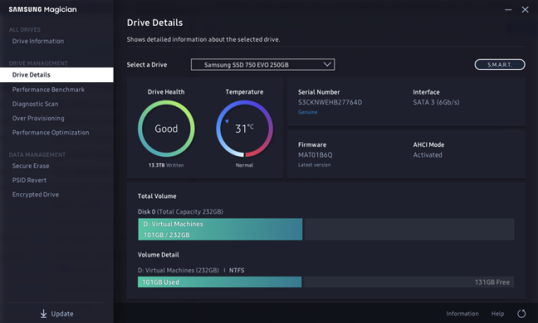
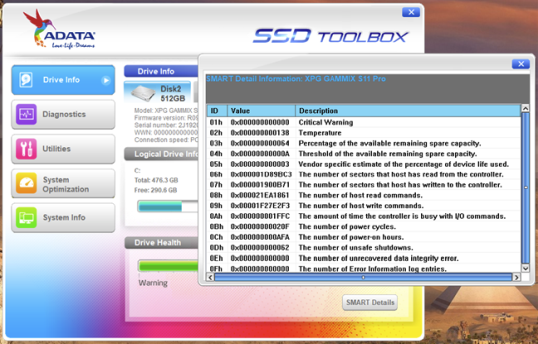
Еще один отличный способ проверки состояния SMART и деталей жесткого диска или SSD — использование приложений, предоставленных его производителем. Например, большинство твердотельных накопителей сопровождаются приложениями поддержки, которые позволяют проверять информацию о них, проверять их состояние, запускать диагностику и т.д. Эти приложения обычно включают опции для проверки состояния SMART.

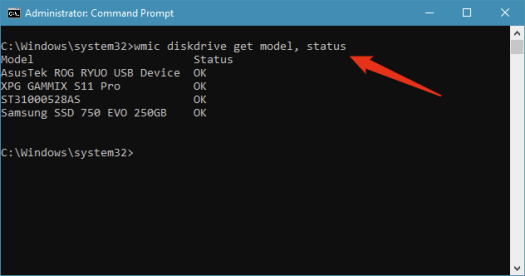
Windows 10. Третий способ проверки состояния SMART вашего жесткого диска или твердотельного накопителя предлагается в Windows 10. Он не показывает подробности, но может сказать вам, является ли состояние SMART ваших накопителей нормальным или нет. Чтобы проверить SMART, откройте командную строку и выполните следующую команду: wmic diskdrive get model, status. Команда выводит список дисков, подключенных к вашему ПК, и показывает состояние SMART для каждого из них.

Этот последний метод проверки состояния SMART, вероятно, самый быстрый способ в Windows 10, чтобы проверить, не работают ли ваши диски.
Как читать SMART значения и атрибуты
Состояние жесткого диска постоянно проверяется и контролируется несколькими датчиками. Значения измеряются с использованием типовых алгоритмов, а затем соответствующие атрибуты настраиваются в соответствии с результатами.
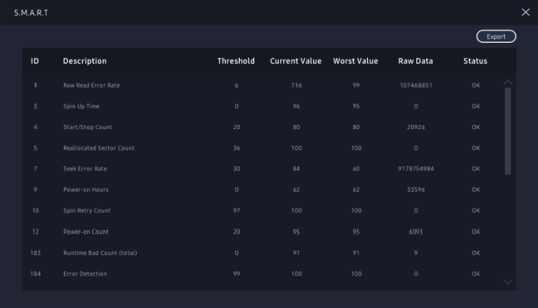
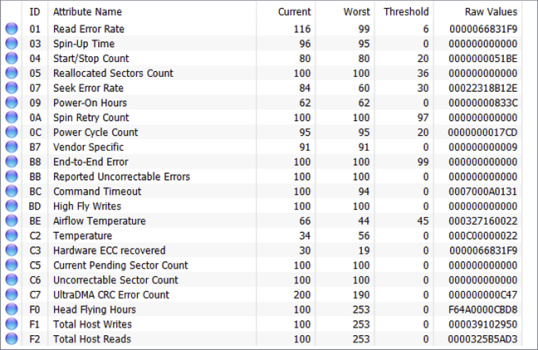
В любой программе мониторинга SMART вы должны увидеть атрибуты, которые содержат хотя бы некоторые из этих полей:
- Identifier: определение атрибута. Обычно оно имеет стандартное значение и помечено числом от 1 до 250 (например, 9 — это число при включении). Тем не менее, все инструменты мониторинга и тестирования диска предоставляют имя и текстовое описание атрибута.
- Threshold: минимальное значение для атрибута. Если это значение достигнуто, значит, ваш диск может выйти из строя.
- Value: текущее значение атрибута. Алгоритм вычисляет это число на основе необработанных данных. Новый жесткий диск должен иметь большое число, теоретический максимум (100, 200 или 253 в зависимости от производителя), который уменьшается в течение срока службы.
- Worst: самое маленькое значение атрибута, когда-либо записанное.
- Data: необработанные измеренные значения, предоставляемые датчиком или счетчиком. Это данные, используемые алгоритмом, разработанным производителем HDD или SSD. Его содержимое зависит от атрибута и производителя диска. Обычные пользователи должны пропустить это.
- Flags: цель атрибута. Обычно это устанавливается производителем и поэтому варьируется от диска к диску. Каждый из атрибутов является либо критическим и может предсказать неизбежный сбой (например, число перераспределенных секторов с идентификатором 5), либо статистическим без прямого влияния на состояние (например, счетчик неожиданных потерь мощности с идентификатором 174).

Пытаясь понять состояние любого атрибута SMART, проверьте значения этих трех полей: значение, порог и флаги. Также помните, что, как правило, меньшие значения указывают на снижение надежности.
Как использовать SMART для прогнозирования сбоя жесткого диска или SSD (необходимо проверить значения)
Не все атрибуты SMART имеют решающее значение для прогнозирования сбоев. Два вышеупомянутых исследования частоты отказов жестких дисков и других источников согласны с тем, что важная помощь в выявлении неисправных дисков:
- Reallocated sector counts. Перераспределение происходит, когда логика привода перераспределяет поврежденный сектор в результате повторяющихся программных или жестких ошибок в новый физический сектор из его резервных. Этот атрибут отражает количество случаев повторного отображения. Если его значение увеличивается, это указывает на износ жесткого диска или SSD.
- Current Pending Sector Count. Это подсчитывает «нестабильные» сектора, то есть поврежденные с ошибками чтения, которые ждут переотображения, своего рода «испытательная» система. Алгоритмы SMART имеют смешанные представления об этом конкретном атрибуте, поскольку иногда это неубедительно. Тем не менее, он может обеспечить более раннее предупреждение о возможных проблемах.
- Reported Uncorrectable Errors. Это количество ошибок, которые невозможно исправить, и это полезно, потому что кажется, что оно имеет одинаковое значение для всех производителей.
- Erase Fail Count. Этот является отличным показателем преждевременной смерти твердотельного накопителя. Он подсчитывает количество неудачных попыток удаления данных, а значение, которое увеличивается, говорит о том, что флеш-память внутри твердотельного накопителя близка к завершению.
- Wear Leveling Count. Это также особенно полезно для твердотельных накопителей. Производители устанавливают ожидаемый срок службы SSD в своих данных SMART. Нивелирование износа граф является оценка состояния здоровья вашего диска. Он рассчитывается с использованием алгоритма, который учитывает предопределенное ожидаемое время жизни и количество циклов (запись, стирание и т. д.), Которые каждый флэш-блок памяти может выполнить до достижения своего конца срока службы.
- Disk temperature является весьма обсуждаемым параметром. Тем не менее считается, что значения выше 60 ° C могут сократить срок службы жесткого диска или твердотельного накопителя и увеличить вероятность повреждения. Мы рекомендуем использовать вентилятор для понижения температуры ваших дисков и, возможно, продлить срок их службы.

Вышеупомянутые атрибуты SMART относительно легко интерпретировать. Если вы заметили увеличение их значений, возможно, ваш диск выходит из строя, поэтому лучше начать резервное копирование. Однако, хотя это и полезные показатели надежности привода, не забывайте, что они не являются надежными.
Историческая справка о SMART
SMART был разработан с 1992 года, хотя теперь вы знаете, что он включен во все современные твердотельные накопители и жесткие диски. Его история охватывает множество имен, таких как Predictive Failure Analysis или IntelliSafe, а также информацию от всех основных производителей жестких дисков: IBM, Seagate, Quantum, Western Digital. Наконец, его документация впервые была представлена в 2004 году в рамках стандарта Parallel ATA и впоследствии регулярно пересматривалась. Последний был выпущен в 2011 году.
Есть ли что-то еще, что вы хотели бы знать о SSD и HDD SMART?
Это было наше краткое исследование внутренней работы SMART и его возможностей для мониторинга, тестирования и прогнозирования отказов жесткого диска. Основная точка зрения, которую вы должны помнить, заключается в том, что эта система самоконтроля может помочь вам проверить состояние вашего жесткого диска. Если вы хотите использовать эти SMART-данные, чтобы увидеть, есть ли проблемы на вашем диске, прочтите статьи, которые мы рекомендовали в этом руководстве. Кроме того, для вопросов, используйте форму комментариев ниже, и давайте обсудим.
2020-05-04T09:38:52
Вопросы читателей